
Lan Chu from Rabobank reveals that most RAG system failures occur in indexing and retrieval, not the LLM itself, and shares production-tested strategies for document parsing, chunking, and evaluation.
At QCon London 2026, Lan Chu, AI Tech Lead at Rabobank, shared lessons from deploying a production AI search system used internally by more than 300 users across 10,000 documents. Her experience shows that most failures in RAG systems stem from indexing and retrieval, rather than the language model itself. The system allows users to search thousands of internal documents, including PDFs and PowerPoint files, to quickly extract insights for tasks such as preparing for client meetings.
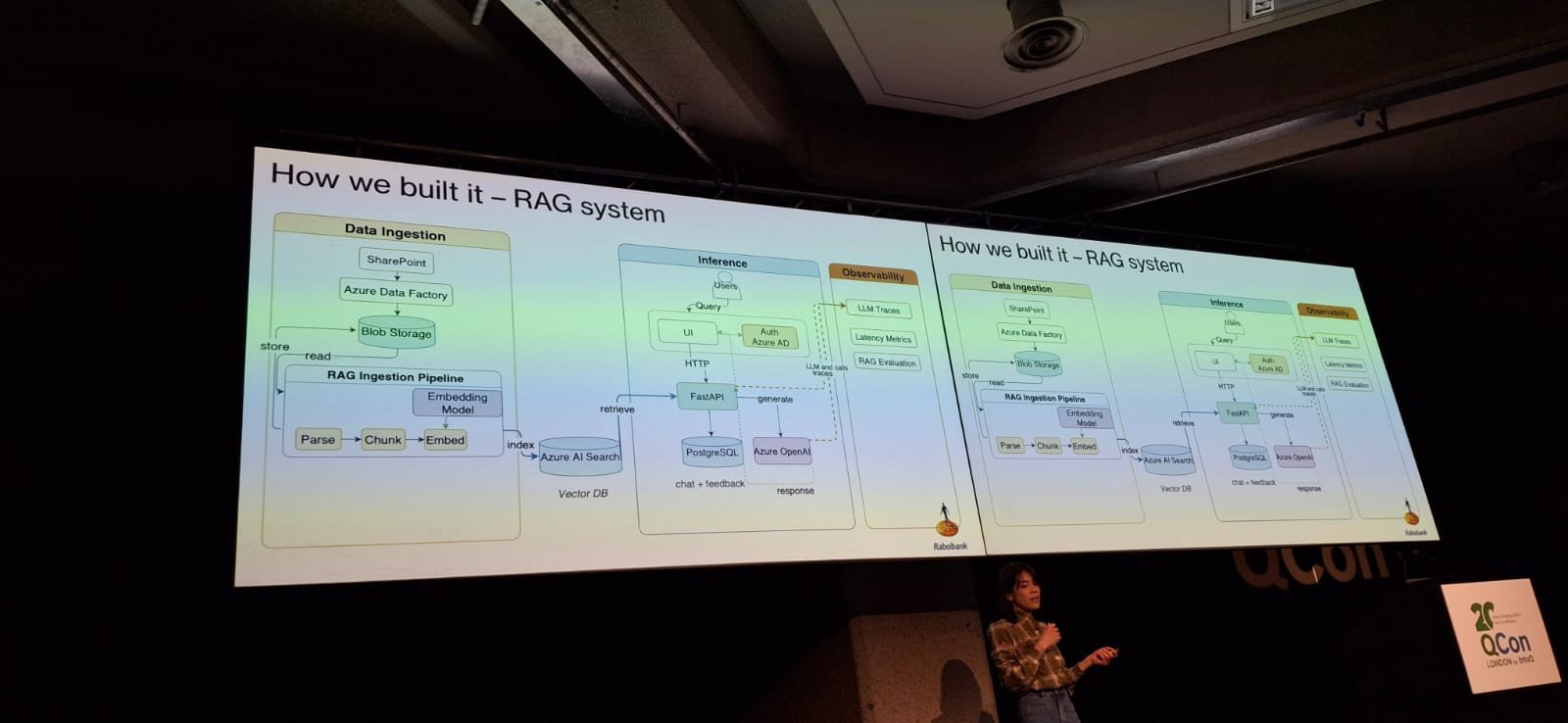
Its architecture follows a typical RAG pipeline: 1- Document ingestion: parsing, chunking, and embedding documents before indexing them in a vector database 2- Retrieval and generation: retrieving relevant chunks and sending them to an LLM to generate answers 3- Observability: monitoring traces, retrieval performance, and evaluation metrics
While the architecture appears simple, Chu explained that production systems quickly encounter challenges around document quality, retrieval relevance, and evaluation. The presenter highlighted that parsing documents accurately is crucial for AI retrieval systems. Enterprise documents often have complex layouts like tables and infographics, and simply converting them to plain text can strip away important structure, causing misread numbers or misinterpreted tables. To fix this, she built a pipeline combining traditional text extraction with visual-language models that understand layouts.
Even with modern language models, chunking content is necessary to avoid overwhelming the model and increasing costs. Chu tested different methods and found that breaking documents into sections worked best for her dataset, reaching high accuracy, though she stressed that the right strategy depends on the specific data. Standard retrieval systems rely on vector similarity, but this can miss important context, like the timing of a document. Her system added temporal scoring to favor newer documents and a routing layer to decide whether to retrieve documents or call external APIs. Since models can struggle with tool parameters, sometimes users are asked to confirm inputs.
Evaluation is often neglected, but Chu recommends building datasets from real user queries, tracking failure modes like routing or temporal errors, and using statistical methods to verify improvements. Real queries often provide more value than synthetic datasets. The key lessons are that building effective AI search systems requires careful attention to several key areas, retrieval quality relies on accurate document parsing and indexing, chunking strategies need to be tested and validated on real datasets, and retrieval should consider signals beyond simple text similarity, like temporal relevance. The presenter noted that agentic architectures can enhance capabilities but introduce additional complexity, and that robust, structured evaluation frameworks are essential to ensure reliable performance in production AI systems.

The core insight from Chu's presentation is that RAG systems fail where most engineers expect them to succeed. While the LLM component often works reliably, the brittle nature of document processing and retrieval creates cascading failures that degrade user experience. This aligns with broader industry observations about retrieval-augmented generation systems, where the retrieval component acts as a critical bottleneck.
From a systems architecture perspective, Chu's approach demonstrates several important patterns for production AI deployments:
Document Processing Pipeline: The combination of traditional text extraction with visual-language models represents a pragmatic hybrid approach. Rather than relying solely on OCR or pure text extraction, the system preserves semantic structure through multimodal understanding. This is particularly crucial for financial documents where tables, charts, and formatted data carry essential meaning.
Chunking Strategy Validation: The emphasis on testing chunking strategies against real datasets rather than theoretical assumptions reflects sound engineering practice. Different document types require different chunking approaches - legal contracts might benefit from paragraph-level chunks, while technical documentation might need section-based segmentation. The key is empirical validation rather than one-size-fits-all solutions.
Retrieval Signal Enrichment: Adding temporal scoring and routing layers demonstrates how simple vector similarity often proves insufficient for production use cases. Financial documents, for instance, have strong temporal dependencies where recent information typically outweighs historical data. The routing layer adds another dimension of intelligence, allowing the system to decide between document retrieval and API calls based on query characteristics.
Evaluation Framework: Chu's recommendation to build evaluation datasets from real user queries rather than synthetic data addresses a common pitfall in AI system development. Production systems face edge cases and real-world complexity that synthetic data rarely captures. Tracking specific failure modes like routing errors or temporal mismatches enables targeted improvements rather than generic model tuning.
Agentic Architecture Considerations: While agentic architectures can enhance RAG systems with tool use and planning capabilities, Chu notes they introduce additional complexity in terms of debugging, monitoring, and failure handling. The trade-off between capability and operational complexity requires careful consideration based on use case requirements.
The production deployment at Rabobank, serving 300+ users across 10,000 documents, provides concrete validation of these approaches. The scale demonstrates that these aren't just theoretical optimizations but practical solutions that work under real-world load and usage patterns.
For teams building production RAG systems, Chu's experience suggests several actionable priorities:
- Invest heavily in document processing quality before optimizing retrieval algorithms
- Build evaluation frameworks using real user data from day one
- Consider multiple retrieval signals beyond semantic similarity
- Design for observability and failure tracking from the architecture phase
- Test chunking strategies empirically rather than assuming optimal configurations
The broader implication is that successful AI system deployment requires as much attention to traditional software engineering practices - testing, monitoring, and iterative improvement - as it does to model selection and architecture design. The LLM may be the most visible component, but the surrounding infrastructure often determines system success or failure.

This presentation at QCon London 2026 adds to the growing body of knowledge about production AI systems, joining insights from other speakers who addressed similar themes around reliability, observability, and practical deployment challenges. The focus on retrieval quality and evaluation frameworks reflects the maturation of the RAG ecosystem from experimental prototypes to production-grade systems requiring enterprise-level reliability.
Comments
Please log in or register to join the discussion