
Akvorado addresses the challenge of processing tens of millions of BGP routes through innovative RIB sharding techniques, eliminating bottlenecks while maintaining data consistency.
The Internet's routing table, now exceeding one million routes, presents a formidable challenge for network monitoring tools like Akvorado, which must process and associate this routing information with network flows. Through the BGP Monitoring Protocol (BMP), Akvorado imports routes to enrich flow data, but the sheer scale of modern routing tables has long strained its implementation. The solution, as recently implemented, involves RIB sharding—a method that partitions the routing database into concurrent segments, dramatically improving performance while maintaining data integrity.
The original implementation of Akvorado's RIB relied on a global read/write lock that became a significant bottleneck. This architecture connected two primary components: a prefix tree built using the bart package (an adaptation of Donald Knuth's ART algorithm) and a list of routes attached to each prefix. 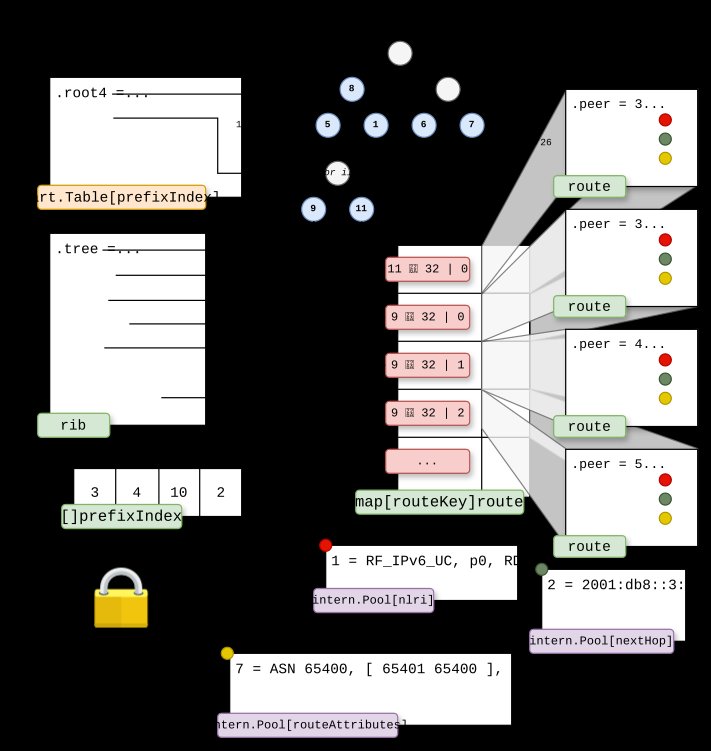 The routes were stored in a Go map leveraging the optimized Swiss table, with each route containing BGP peer identifiers, NLRIs, next hops, and attributes. To optimize memory usage, the implementation employed an interning mechanism for NLRIs, next hops, and route attributes, replacing actual values with 32-bit references.
The routes were stored in a Go map leveraging the optimized Swiss table, with each route containing BGP peer identifiers, NLRIs, next hops, and attributes. To optimize memory usage, the implementation employed an interning mechanism for NLRIs, next hops, and route attributes, replacing actual values with 32-bit references.
The global lock created contention between multiple RIB users with different requirements. Kafka workers, numbering between 8 and 16 in typical deployments, continuously look up routing information to enrich flows. Meanwhile, monitored routers send route updates through BMP, potentially delivering millions of routes during initial synchronization. When BGP peers or monitored routers go down, Akvorado must flush associated routes, all while holding the write lock. This created a situation where both readers and writers experienced significant contention, neither able to lag behind without causing operational issues.
The solution emerged through a two-phase approach to RIB sharding. The first phase implemented basic sharding by splitting the RIB into multiple segments, each handling a subset of prefixes. 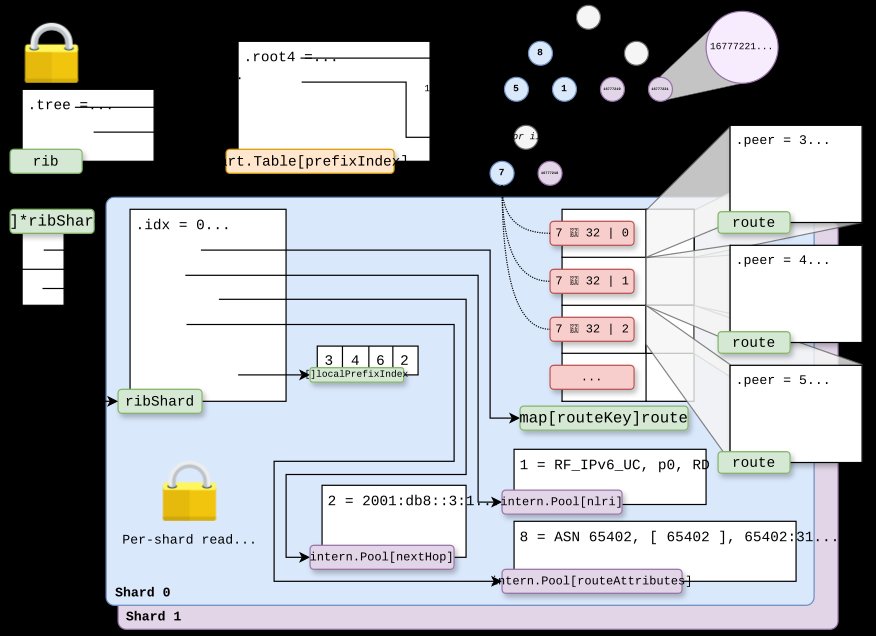 The prefix tree remained global but protected by a single lock, while each shard obtained its own read/write lock, route map, and intern pools. This partitioning strategy allowed concurrent access to different parts of the routing table. The prefix indexes were sharded such that the 8 most significant bits represented the shard index, with the remaining 24 bits serving as the local prefix index.
The prefix tree remained global but protected by a single lock, while each shard obtained its own read/write lock, route map, and intern pools. This partitioning strategy allowed concurrent access to different parts of the routing table. The prefix indexes were sharded such that the 8 most significant bits represented the shard index, with the remaining 24 bits serving as the local prefix index.
This initial implementation demonstrated immediate performance benefits. As noted by the author, after implementing this blind change, the BMP receiver operated steadily. Concurrent benchmarks with half a million synthetic routes partitioned across 0 to 8 writers, while 1 to 16 readers continuously looked up 10,000 routes, confirmed improvements in both read and write latencies. 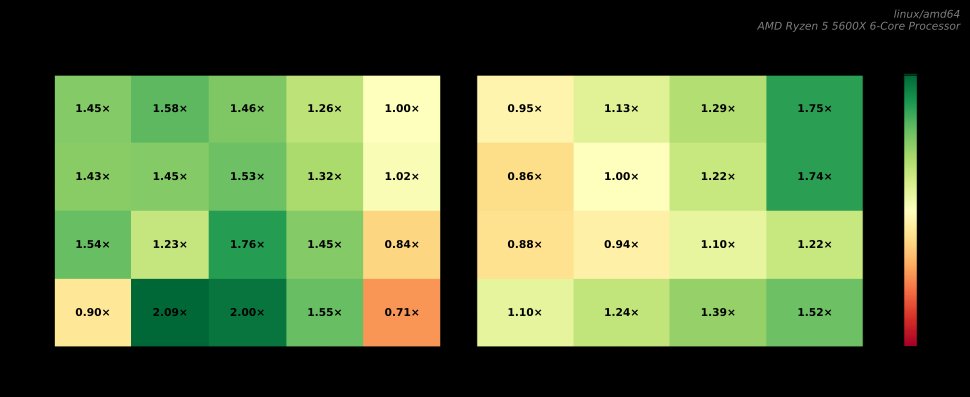 The results showed that while sharding improved overall performance, a high number of writers could degrade read latency, indicating the need for further optimization.
The results showed that while sharding improved overall performance, a high number of writers could degrade read latency, indicating the need for further optimization.
The second phase addressed the remaining global lock protecting the prefix tree by implementing lock-free reads. The bart package provides mutation methods that return an updated tree using copy-on-write semantics, eliminating the need for readers to acquire the global lock. 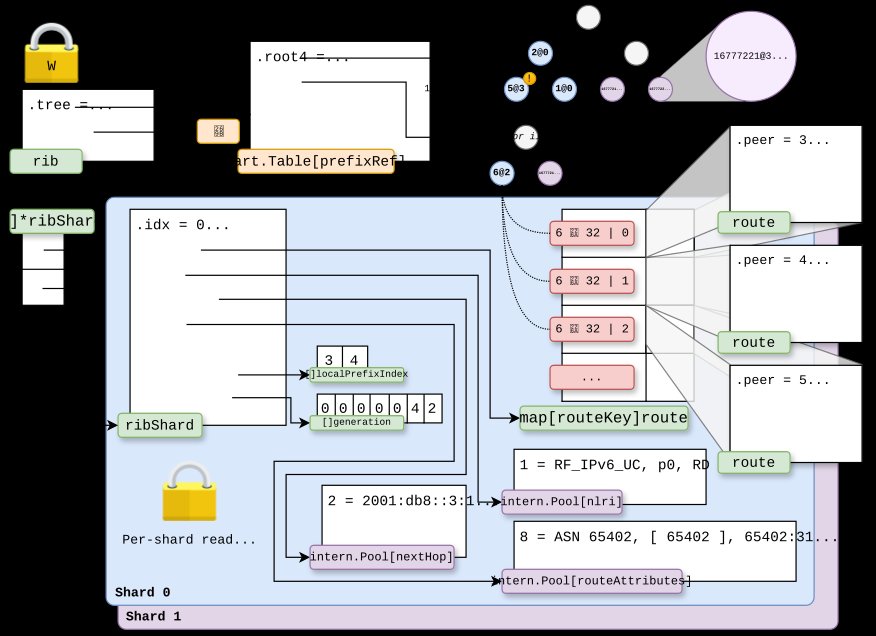 The prefix tree was encapsulated in an atomic pointer, with synchronization responsibilities shifting exclusively to writers.
The prefix tree was encapsulated in an atomic pointer, with synchronization responsibilities shifting exclusively to writers.
To handle potential stale data scenarios—where readers might fetch a recycled prefix index—the implementation introduced generation numbers. Each prefix reference now includes an index and a generation number, with the generation incrementing whenever a prefix index is freed. Readers check if the generation number matches before accessing routes, assuming an empty list if generations don't align. This approach prevents access to stale data while maintaining lock-free reads.
Benchmarking the lock-free implementation showed further improvements in read latency once the copy-on-write costs were amortized. The cumulative improvements from both sharding steps demonstrate the effectiveness of this approach to scaling RIB operations.
The implementation of RIB sharding in Akvorado represents a thoughtful balance between performance optimization and data consistency. By partitioning the routing table and implementing lock-free reads, the system can now handle the massive scale of modern BGP routing tables without sacrificing data integrity. The approach leverages Go's concurrency primitives while addressing the specific challenges of network route processing, including high-frequency updates and the need for low-latency lookups.
This solution highlights the importance of understanding workload characteristics when designing concurrent systems. The two-phase implementation allowed for incremental improvements, with each phase addressing specific bottlenecks while maintaining system stability. The use of generation numbers to handle prefix recycling demonstrates clever engineering that preserves lock-free semantics without compromising data correctness.
Looking forward, the implementation of RIB sharding in Akvorado 2.2 and 2.4 provides a foundation for scaling network monitoring to even larger routing tables. As the Internet continues to grow and routing complexity increases, techniques like these will become essential for maintaining the performance of network monitoring tools. The approach could potentially be applied to other similar systems facing comparable scaling challenges, demonstrating how careful architectural design can transform performance bottlenecks into efficient, concurrent solutions.
For those interested in the technical details, the Akvorado project provides comprehensive documentation and implementation details. The bart package, which forms the foundation of the prefix tree implementation, offers insights into how algorithmic choices can impact system performance. The interning mechanism, while predating Go's newer unique package, demonstrates how custom solutions can outperform standard implementations in specific use cases, particularly when dealing with non-comparable values and explicit reference counting.
The evolution of Akvorado's RIB implementation serves as a valuable case study in systems optimization, showing how understanding both the workload and the available concurrency primitives can lead to elegant solutions to complex scaling problems.
Comments
Please log in or register to join the discussion