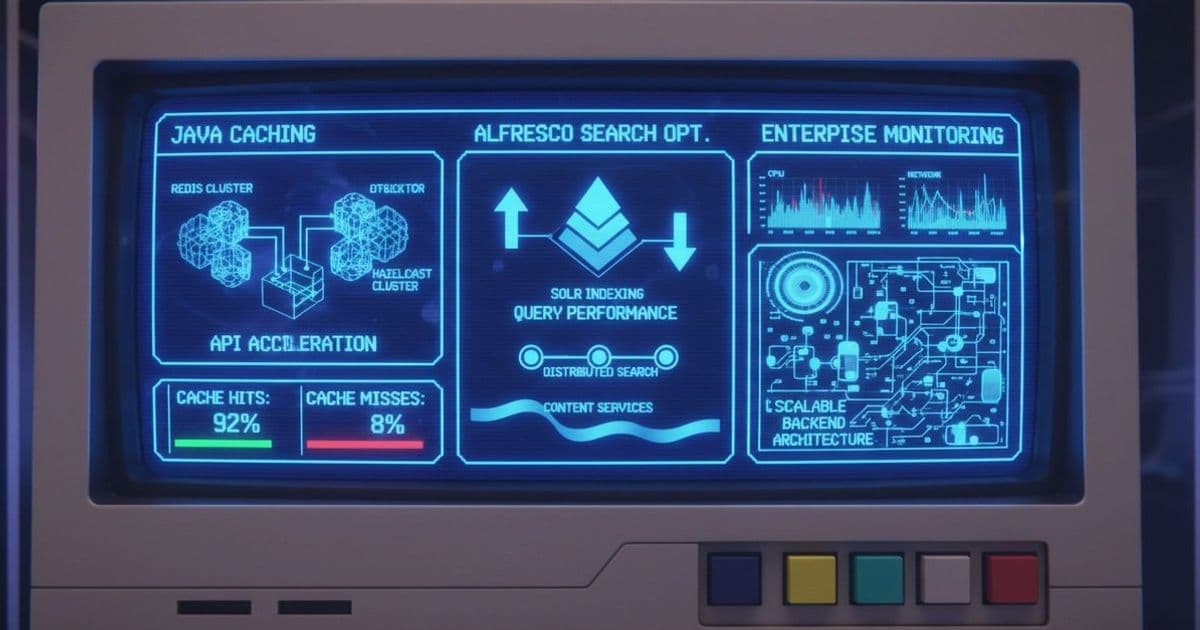
A technical analysis of managing data locality in Java applications and optimizing search performance within Alfresco Content Services environments.
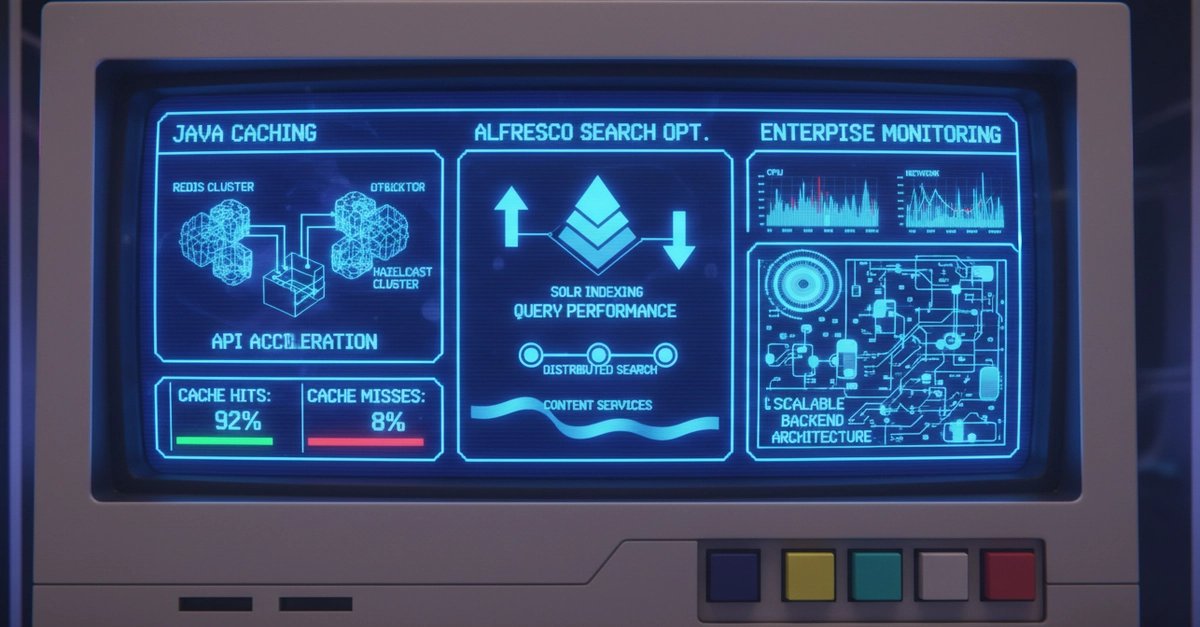
Enterprise systems often fail not because of slow algorithms, but because of how they manage data movement. When an application scales, the bottleneck shifts from CPU cycles to the latency involved in fetching state from a database or searching through massive unstructured content repositories. To build systems that survive high concurrency, engineers must master two distinct but related domains: distributed caching for application state and optimized indexing for content search.
The Distributed Caching Dilemma
In a single-node Java application, in-memory caching via Caffeine or Guava is straightforward. You have a local heap, and the latency is measured in nanoseconds. However, as soon as you move to a clustered environment, local caches become a liability. If Node A updates a user profile and Node B continues to serve the old version from its local heap, you have a consistency failure.
To solve this, engineers typically choose between two distributed patterns: side-cache or integrated data grids.
Redis: The External Side-Cache
Redis operates as an out-of-process store. The application treats it as a fast, external key-value store. This approach offers excellent isolation. If your Java application experiences a heap pressure issue or a Garbage Collection (GC) pause, the cache remains unaffected. The trade-off is the network hop. Every cache hit requires a TCP round-trip, which introduces millisecond-scale latency that local memory does not have.
Hazelcast: The In-Process Data Grid
Hazelcast takes a different approach by providing a distributed data structure that can live within the JVM. This allows for much tighter integration with Java objects. Hazelcast excels in scenarios requiring complex distributed primitives, such as distributed locks or atomic counters. However, because the data resides within the application's memory space, large caches can increase GC overhead and complicate heap management. You are essentially trading network latency for memory management complexity.
Optimizing Search in Alfresco Content Services
While caching manages frequently accessed state, search engines like Apache Solr manage the discovery of information. In an enterprise content management system like Alfresco, the relationship between the relational database (storing metadata) and the Solr index (storing searchable content) is a common point of failure.
The Indexing Bottleneck
Indexing is an expensive operation. In Alfresco, every time a document is uploaded or metadata is changed, a transaction must be coordinated between the database and the Solr index. If the indexing queue grows too large, users experience "search lag," where they upload a file but cannot find it via search for several minutes.
To optimize this, engineers should focus on three areas:
- Schema Design: Avoid indexing large, highly volatile text fields that change frequently. Every update triggers a re-index of that document. Keep the index lean by only including fields necessary for business discovery.
- Commit Strategies: Frequent hard commits in Solr provide high visibility but destroy write throughput because they force the creation of new index segments. Using soft commits allows for near-real-time search visibility without the heavy disk I/O penalty of a full segment flush.
- Query Complexity: Avoid leading wildcards (e.g.,
*term) in search queries. These force Solr to scan the entire term dictionary, bypassing the efficiency of the inverted index. Use edge n-grams or specialized analyzers if prefix searching is a requirement.

Architectural Trade-offs
When designing these systems, you are constantly negotiating the CAP theorem (Consistency, Availability, Partition Tolerance).
In a caching layer, you must decide: do I want my cache to be strictly consistent with my database, or can I tolerate stale data for the sake of speed? Most high-scale web applications choose eventual consistency, using TTL (Time-to-Live) settings to expire old data.
In a search layer, the trade-off is between indexing latency and search accuracy. A system that prioritizes immediate searchability will struggle with high write volumes, while a system that prioritizes write throughput will suffer from a delay between data ingestion and search availability.
Effective enterprise architecture requires recognizing which of these pressures is currently hitting your system. If your application is CPU-bound, look at your caching strategy. If your application is I/O-bound and users are complaining about missing data, look at your Solr indexing configuration.
Comments
Please log in or register to join the discussion