StepFun unveils Step 3.5 Flash, a 196B parameter sparse Mixture-of-Experts model that activates only 11B parameters per token, delivering frontier reasoning at 100-300 tokens/second while maintaining exceptional efficiency for real-time agentic tasks.
StepFun has unveiled Step 3.5 Flash, a groundbreaking open-source foundation model engineered to deliver frontier reasoning and agentic capabilities with exceptional efficiency. Built on a sparse Mixture of Experts (MoE) architecture, the model selectively activates only 11B of its 196B parameters per token, achieving what StepFun calls "intelligence density" that allows it to rival top-tier proprietary models while maintaining the agility required for real-time interaction.
Deep Reasoning at Speed
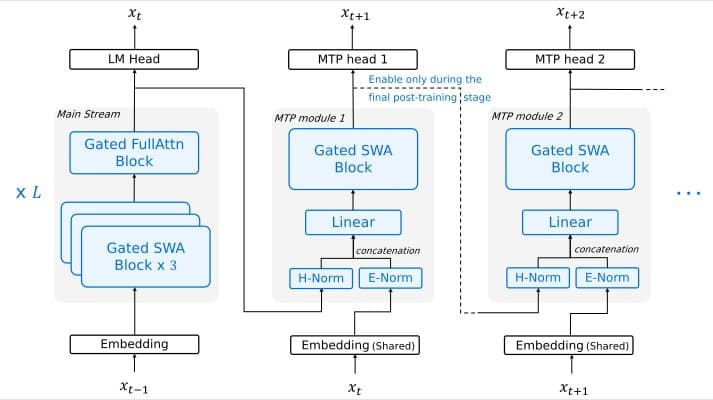
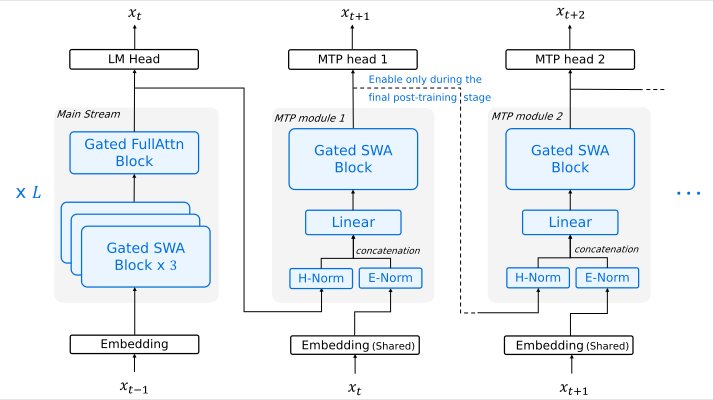
The model's architecture is purpose-built for the demands of modern AI agents. While traditional chatbots excel at reading and responding, agents must reason fast and act decisively. Step 3.5 Flash achieves this through 3-way Multi-Token Prediction (MTP-3), delivering generation throughput of 100–300 tokens per second in typical usage, with peaks reaching 350 tokens per second for single-stream coding tasks. This speed enables complex, multi-step reasoning chains with immediate responsiveness—critical for applications where latency kills user experience.
A Robust Engine for Coding & Agents
Step 3.5 Flash demonstrates its agentic prowess through impressive benchmark performance. The model achieves 74.4% on SWE-bench Verified and 51.0% on Terminal-Bench 2.0, proving its ability to handle sophisticated, long-horizon tasks with unwavering stability. These results position it as a serious contender in the competitive landscape of coding-focused foundation models.
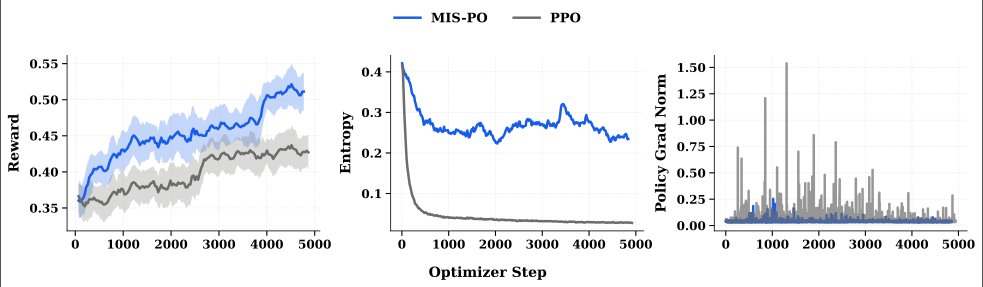
The model's reinforcement learning framework drives consistent self-improvement, with training dynamics showing stable optimization even for long reasoning sequences. The framework employs Metropolis Independence Sampling Filtered Policy Optimization (MIS-PO), which replaces fragile importance weighting with strict sample filtering to maintain training stability at scale.
Efficient Long Context
Long-context processing often comes with prohibitive computational overhead, but Step 3.5 Flash tackles this challenge through innovative architecture. The model supports a cost-efficient 256K context window by employing a 3:1 Sliding Window Attention (SWA) ratio—integrating three SWA layers for every one full-attention layer. This hybrid approach ensures consistent performance across massive datasets or long codebases while significantly reducing the computational overhead typical of standard long-context models.
The architectural choice of SWA over linear alternatives maintains flexibility required for speculative decoding and is inherently compatible with Multi-Token Prediction heads. This compatibility allows the model to validate multiple token hypotheses in a single pass, effectively breaking the serial constraints of standard autoregressive decoding.
Accessible Local Deployment
One of Step 3.5 Flash's most compelling features is its accessibility for local deployment. Optimized for high-end consumer hardware, the model runs securely on devices like Mac Studio M4 Max, NVIDIA DGX Spark, or AMD AI Max+ 395, ensuring data privacy without sacrificing performance. This local-first approach addresses growing concerns about data sovereignty and enables deployment in environments with limited internet connectivity.
The model's optimized parameter scale facilitates highly accessible, local inference. By consolidating its total capacity to a scale compatible with personal hardware, Step 3.5 Flash provides a 100% trusted execution environment for sensitive applications.
Competition-Level Math and Reasoning
Step 3.5 Flash demonstrates exceptional logical rigor in competition-level mathematics. Through deep analysis of IMO Shortlisted problems, the model proves its core strength in complex symbolic reasoning and abstract structural synthesis. The model achieves remarkable scores across elite benchmarks:
- AIME 2025: 97.3 (99.8 with Python code execution)
- HMMT 2025: 98.4 (Feb.) / 94.0 (Nov.)
- IMOAnswerBench: 85.4 (86.7 with Python)
- ARC-AGI-1: 54.8 (56.5 with Python)
These results demonstrate the model's ability to handle complex symbolic reasoning and abstract structural synthesis, essential capabilities for advanced mathematical problem-solving.
Orchestrated Tool-Use
Tool-use represents the fundamental atomic capability that transforms a static model into an active agent. Step 3.5 Flash distinguishes itself through a unique "Think-and-Act" synergy in tool environments. Rather than merely executing commands, the model exhibits massive-scale orchestration and cross-domain precision.
In a stock investment scenario, Step 3.5 Flash orchestrated over 80 MCP tools to aggregate market data and technical indicators, executed raw code for bespoke financial metrics and data visualization, and automatically triggered cloud storage protocols and notification systems. This demonstrates the model's ability to map complex intent to high-density tool-use in a single, integrated session.
Agentic Coding Excellence
The shift from traditional coding to agentic coding marks a transition from passive code completion to autonomous resolution of end-to-end engineering objectives. Step 3.5 Flash functions by decomposing complex requirements into actionable steps within a codebase, treating code as a tool to verify logic, map dependencies, and navigate structural depth.
The model's compatibility with Claude Code enables efficient backend support for agent-led development. Leveraging its long-context reasoning and precision in tool invocation, Step 3.5 Flash handles repository-level tasks and maintains development loop continuity.
Deep Research Capabilities
While Step 3.5 Flash is compact, its utility extends beyond internal parametric knowledge through internet-based research capabilities. The model's performance on benchmarks like xbench-DeepSearch and BrowserComp demonstrates its strength in leveraging the internet as a dynamic knowledge base.
Deep Research extends basic information retrieval by delegating the entire research workflow to an agentic loop of planning, searching, reflecting, and writing. Using a single-agent loop based on ReAct architecture with specialized tools like batch_web_surfer and shell, Step 3.5 Flash achieves a score of 65.27% on the Scale AI Research Rubrics, delivering research quality that competes with OpenAI and Gemini Deep Research while maintaining significantly higher inference efficiency.
Multi-Agent Orchestration Framework
Step 3.5 Flash natively supports a multi-agent architecture where a Master Agent orchestrates complex tasks through autonomous planning and dynamic routing. This hierarchical framework dispatches specialized Search and Verify agents to handle retrieval and factual grounding via parallel tool-invocation loops.
A Summary Agent consolidates each sub-agent's trajectory into structured feedback, enabling the Master Agent to synthesize a final, coherent response. This architecture enables sophisticated task decomposition and coordination across multiple specialized agents.
Edge-Cloud Collaboration
Edge-Cloud Collaboration offers inherent advantages over cloud-only solutions in context management, privacy protection, and cost control. The synergy between cloud-based Step 3.5 Flash and edge-deployed Step-GUI demonstrates how they work together to execute complex tasks on diverse edge devices.
In a WeChat messaging scenario, Step 3.5 Flash acting as the "Cloud Brain" first executes search and summarization in the cloud, then triggers the on-device Step-GUI to wake the phone, open WeChat, and deliver the message. This cloud-device synergy simplifies local execution for reliable results.
Reliability in Interaction
Step 3.5 Flash demonstrates reliability not just in problem-solving but in user engagement with precision and professional judgment. In internal benchmarks of 74 ambiguous real-world requests, the model consistently identified missing information and asked targeted questions to clarify user intent rather than making assumptions.
Across 500 prompts in balanced bilingual settings spanning life, learning, and workplace contexts, the model demonstrated solid domain knowledge and professional style, maintaining high instruction-following standards in both English and Chinese.
Known Issues and Future Directions
While Step 3.5 Flash achieves frontier-level agentic intelligence, it currently relies on longer generation trajectories than some competitors to reach comparable quality. The team aims to address this through efficient universal mastery, advancing variants of on-policy distillation to internalize expert behaviors with higher sample efficiency.
Future work includes applying reinforcement learning to intricate, expert-level tasks found in professional work, engineering, and research. The model may experience reduced stability during distribution shifts, particularly in highly specialized domains or long-horizon, multi-turn dialogues where it may exhibit repetitive reasoning or inconsistencies.
Competition and Market Position
In benchmark comparisons, Step 3.5 Flash demonstrates competitive performance across reasoning, coding, and agentic tasks. The model achieves strong results while maintaining significantly lower computational costs compared to larger models. For instance, at 128K context on Hopper GPU, Step 3.5 Flash operates at 1.0x estimated cost while delivering 100 tokens per second with MTP-3 and EP8 optimization.
Against competitors like DeepSeek V3.2, Kimi K2, and GLM-4.7, Step 3.5 Flash shows particular strength in agentic benchmarks like τ²-Bench (88.2) and BrowseComp (69.0 with Context Manager), while maintaining competitive performance in reasoning and coding tasks.
Availability and Ecosystem
Step 3.5 Flash is available via StepFun's API platform in both Chinese and English, with web chat interfaces and mobile applications for iOS and Android. The model integrates seamlessly with OpenClaw, StepFun's powerful agentic platform, and developers can access the INT4 quantized model weights in GGUF format for local deployment.
The model can be tested on NVIDIA accelerated infrastructure via build.nvidia.com, making it accessible to developers and researchers looking to explore its capabilities.
Conclusion
Step 3.5 Flash represents a significant advancement in efficient foundation models, demonstrating that frontier-level reasoning and agentic capabilities can be achieved without prohibitive computational costs. By combining sparse activation, innovative attention mechanisms, and purpose-built architectures for speed and efficiency, StepFun has created a model that is truly "Fast Enough to Think. Reliable Enough to Act."
The model's success lies not just in its technical specifications but in its practical utility—delivering professional-grade performance across coding, mathematics, research, and agentic tasks while remaining accessible for local deployment. As the AI landscape continues to evolve toward more autonomous and capable agents, Step 3.5 Flash positions itself as a versatile and efficient foundation for the next generation of intelligent applications.
Comments
Please log in or register to join the discussion