
AI app builders get you a working prototype in minutes, then leave you stranded at the boundary between a pretty frontend and a backend that survives real traffic. The gap is structural: probabilistic code generation collides with the deterministic guarantees that payments, permissions, and inventory actually require.
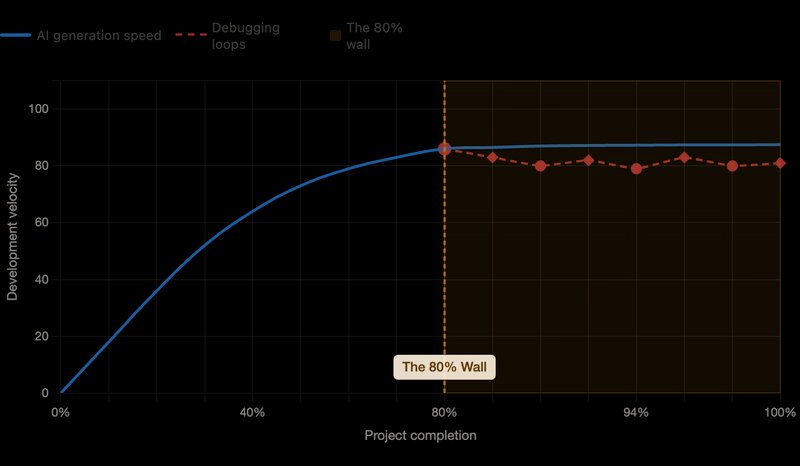
You type a prompt, wait ten minutes, and a functioning interface appears. The first build feels effortless. Then you try to add real users, charge a card, or coordinate two writes against the same row, and the illusion cracks. Founders keep hitting the same boundary: the first 80% of an AI-generated product comes fast, and the last 20% turns into an expensive loop where fixing one bug breaks three working features. The code is a black box you cannot read, so you cannot reason about why it fails.
This is worth examining as a systems problem rather than a tooling complaint. The failure mode is predictable once you understand what these generators optimize for and where that optimization conflicts with the consistency guarantees production software depends on.

The mismatch between probabilistic generation and deterministic systems
The core tension is simple to state. A language model predicts the most likely next token given a pattern. That makes it a strong guesser. Commercial software, however, runs on rules that must execute identically every single time. The path that debits an account, grants an admin role, or decrements stock cannot be a best guess. It has to be a fixed contract.
When a non-technical founder builds entirely through prompts, they accumulate thousands of lines they cannot audit. Call it comprehension debt. The team's bus factor drops to zero, because nobody, human or otherwise, holds a reliable mental model of the system. When something breaks, you are betting that the same probabilistic process that introduced the defect will reliably remove it. That bet gets expensive.
There is data behind the intuition. GitClear's AI Copilot code quality research reported a sharp rise in duplicated code blocks across AI-assisted codebases, evidence that these tools tend to copy-paste a patch rather than refactor toward a shared abstraction. Veracode's GenAI code security findings point in the same direction on the security side, with generated code frequently missing the relational checks and input validation that a human reviewer would insist on.
Where AI backends fall apart: consistency under concurrency
The generators are genuinely good at frontends. Layout, components, state for a single user session, all of that arranges cleanly. The trouble starts at the data layer, where correctness depends on coordination across many simultaneous clients.
AI tools default to flexible formats: flat files, JSON blobs, loosely typed documents. Flexible is easy to emit. It is also where relational constraints go to die. Without foreign keys, unique constraints, and transactional isolation, your application is exposed to race conditions.
Consider the canonical example. Two users request the same concert seat within the same millisecond. A system without proper isolation reads "seat available" twice, then writes "seat booked" twice. Both transactions succeed. You have sold one seat to two people, and the conflict surfaces at the venue door rather than at write time. This is a textbook lost-update problem, and it is exactly the class of bug that a relational database with serializable transactions or row-level locking is designed to prevent.
The problem compounds when generated code tries to paper over slow queries by caching state in the browser. You get intermediate states that are hard to reason about:
- Phantom inventory: items shown as available on screen while the database says sold out, because the client trusts stale local state.
- Silent write-back corruption: the UI persists outdated cached values, overwriting fresher server data with older client data.
These are not cosmetic. They are consistency violations. The system has no single source of truth, and the client and server disagree about reality. Distributed systems engineers spend careers building protocols to avoid precisely this, and a generator that caches for speed reintroduces it by default.
A more durable approach: structured environments and visible logic
The alternative to black-box prompting is to constrain what the model can produce and to make its output inspectable. One useful framing is two-way translatability: anything the AI generates should map to a structure a human can see, understand, and edit.
Instead of hidden scripts, the model emits visual node graphs, typed data tables, and explicit logic flows. When a process breaks, you trace the path visually to the point where the logic diverged. You are auditing a system rather than re-prompting a guess. The model still accelerates the work, but it operates inside guardrails rather than defining the architecture.
The data layer is where this matters most. A scalable backend wants a real relational database, PostgreSQL being the obvious default, with constraints and foreign keys enforced at the storage layer rather than in application code. Row-level security configured explicitly, rather than through generated SQL policies nobody has reviewed, keeps authorization decisions where they belong: close to the data, evaluated on every query, independent of whatever the UI happens to send.
The trade-off is real and worth naming. A structured visual environment is less open-ended than a blank prompt box. You give up some expressiveness and accept the platform's model of the world. In exchange you get constraints you can rely on, output you can read, and a system whose failure modes are bounded. For a business that needs to process payments correctly, that exchange is favorable.
The transition this reflects
This move from free-text generation toward structured, visual tooling tracks a broader shift. Gartner forecasts that a large majority of new applications will be built on low-code or no-code platforms, much of it driven by what they call business technologists: people outside traditional IT who build tools to solve concrete problems in their own domains. As these platforms become the default, the ones that expose their generated structures rather than hiding them are the ones that let non-specialists ship software that holds up.
From prototype to production without the rewrite
The expensive failure is the ejection crisis: the moment the prototype's architecture buckles under real load and the only option is a full rewrite. Avoiding it is mostly about separating the volatile presentation layer from the deterministic business logic early.
Two workflows make sense depending on how you like to build. In a unified full-stack approach, you build the frontend and the backend in one visual platform such as Momen, keeping UI and data coupled from the start. In a hybrid, headless approach, you keep using a generator like Lovable or Bolt.new for rapid UI iteration, then connect that frontend to a structured backend that handles persistence, authorization, and business rules.
The hybrid path leans on integration to stay coherent. A connector built on the Model Context Protocol can wire an AI-generated frontend to a production PostgreSQL database, giving you visual logic flows for backend behavior and auto-generated GraphQL APIs over your schema. The presentation layer stays fast and disposable; the data and logic layer stays rigid and durable. That boundary is the whole point. It lets the part that benefits from rapid iteration iterate rapidly, while the part that demands correctness stays under strict control.
The architect stays human
AI code generation is a strong starting point and a poor finishing one. Speed to market is not the same as speed to a working interface. The system that survives edge cases, concurrent writes, and real traffic is built on deliberate choices about data modeling, consistency, and authorization, choices a probabilistic generator will not make for you. Treat the model as a capable junior developer: useful, fast, and in need of a blueprint it did not write. The founder holds that blueprint, and that responsibility does not transfer to a prompt.
Comments
Please log in or register to join the discussion