
A forensic analyst reveals why PDF files represent a uniquely difficult challenge for digital forensics, where the very concept of a 'typical' document is a misnomer, complicating efforts to detect edits, forgeries, and AI-generated content.
In the world of digital forensics, certain questions are perennial. Can you detect deep fakes? Can you handle audio and video? And the one that makes the analyst cringe: "Can you handle documents?" This almost always means PDFs. While my forensic software can evaluate PDF files and often identify indications of edits, distinguishing real from AI-generated or pinpointing specific edits is a significantly harder task than with images or video. The core problem is that with PDFs, there is almost nothing that is truly "typical," and that fundamental inconsistency is the central forensic problem.
The Illusion of a Standard
When evaluating any media, a quick way to spot potential alteration is to look for deviations from the typical case. For JPEGs, this is relatively straightforward. Over 85% of JPEGs use baseline encoding, and nearly 15% use progressive encoding. Any other of the 12 defined JPEG modes is so rare that its presence should immediately trigger a deeper investigation. The file structure itself can reveal tampering without even viewing the visual content.
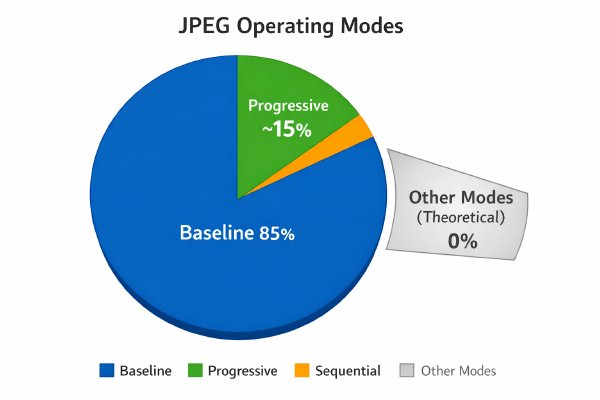
With PDFs, this approach collapses. The PDF specification is an ISO standard (ISO 32000), but in practice, very few applications adhere strictly to it. Every PDF has required components: a version comment, a set of objects with unique identifiers, a cross-reference table (xref or XRef) to locate those objects, an end-of-file marker (%%EOF), and a startxref field. However, the way these components are implemented, combined with the multi-stage creation pipelines common in enterprise environments, creates a chaotic landscape where nearly every file is atypical in some way.
The Versioning Vexation
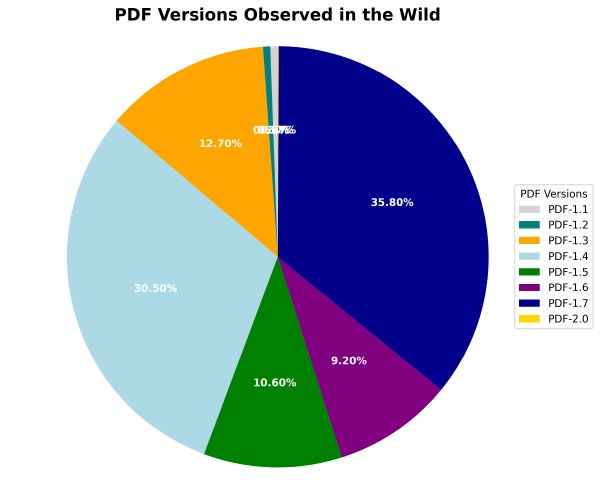
Consider the very first line of a PDF, the version comment (e.g., "%PDF-1.5"). This doesn't mean the file complies with the PDF 1.5 specification; it only means the file requires a viewer that supports 1.5 or later. This is often implemented incorrectly:
- Overstated Versions: A file may claim to be PDF 1.5 but contain no features requiring that version, making it renderable by older viewers.
- Understated Versions: A file may claim to be PDF 1.5 but use features only found in PDF 1.6 or 1.7, causing viewers that only support up to 1.5 to fail or render incorrectly.
Neither scenario indicates an edit. It simply means the encoder didn't properly handle version numbers, which is, ironically, typical for PDF files.
The Myriad Methods of Modification
The concept of a "typical" edit is also a fallacy. When a PDF is altered, the encoding system might:
- Append after EOF: Adding more objects, cross-reference tables, and another %%EOF marker, resulting in multiple EOF lines.
- Append after startxref: Removing the final %%EOF, adding new content, and then adding a new ending, resulting in multiple startxref entries.
- Replace the ending: Removing the final startxref and %%EOF before inserting new objects and a new ending.
- Revise objects: Removing obsolete objects and inserting new ones, leaving unused or duplicate objects behind.
- Rewrite everything: Creating a brand new PDF, which can still carry over artifacts from the original.
The problem is that even a "clean" PDF often contains edit residues. A typical utility bill PDF, for instance, might go through a multi-stage pipeline: an initial template is created, customer information is filled in by one process, mailing address by another, and then a PDF is generated. Enterprise security gateways like MS Defender for Office 365 or Proofpoint may re-encode the PDF to strip macros and disable hyperlinks. Mobile devices might request a transcoded version for preview. Finally, the user might "print to PDF," re-encoding it again. Every step leaves residues, making the final file a composite of multiple processes. This step-wise generation is the norm, not the exception.
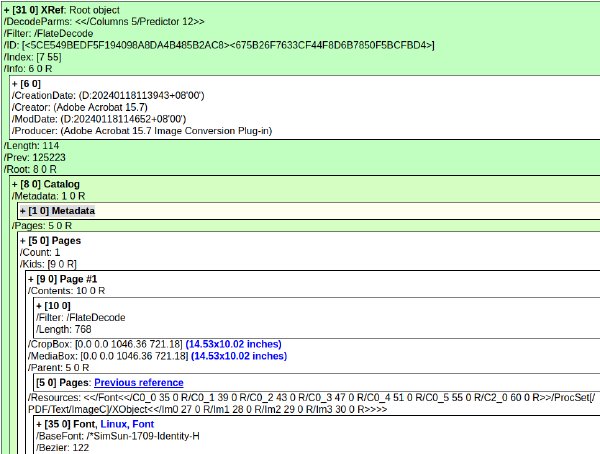
Object Identifiers and Bad References
Further complicating matters are the PDF's internal object structure. Every object has a unique identifier and a generation number. The specification dictates that when an object is replaced, the generation number should be updated. In practice, nearly all PDFs use generation number 0 for every object. Of over 10,000 sample PDFs, only 12 contained objects with non-zero generations. However, it's very common to see the same object number redefined multiple times with the same generation number, which is non-compliant but typical.
Conversely, seeing a non-zero generation number is technically compliant but atypical, and should set off alarms. Similarly, invalid startxref pointers are common. Adobe Acrobat, the de facto standard, has developed special rules over 30 years to handle bad pointers from known generators like older versions of iText. Other viewers like Evince, Firefox, and Chrome are even more forgiving, often searching for correct offsets when they see bad references. This means different viewers may render the same PDF differently, adding another layer of variability.
The AI Tell
Despite the chaos, there are ways to detect intentional edits and AI generation. One crucial tell is the "dog that didn't bark": a filled-in template without an intermediate edit between the template and the personalized information. AI systems generate the template and populate it simultaneously, leaving no edit trail. While it's relatively easy to spot AI-generated images, evaluating the associated PDF is significantly harder.
The difficulty of evaluating PDFs lies in their complexity. They are not just containers for images and text; they are complex, often inconsistent file formats where the rules are frequently broken, and the creation process is a black box. In the forensic world, PDFs are a reminder that the more complicated the file format, the more difficult it becomes to evaluate, and the concept of "typical" is often the first thing you have to discard.
Comments
Please log in or register to join the discussion