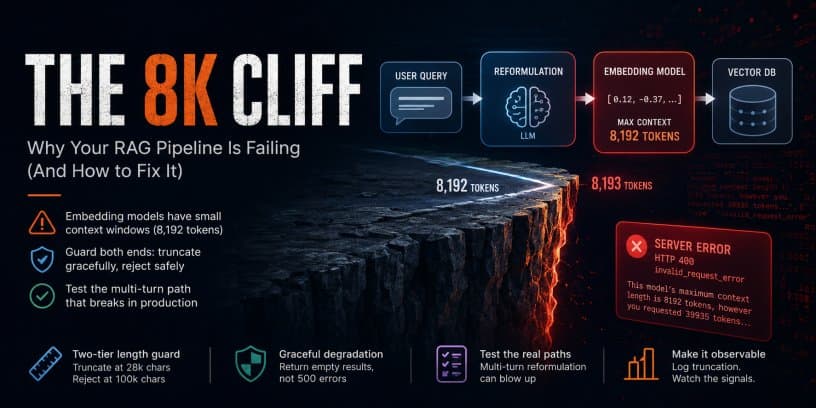
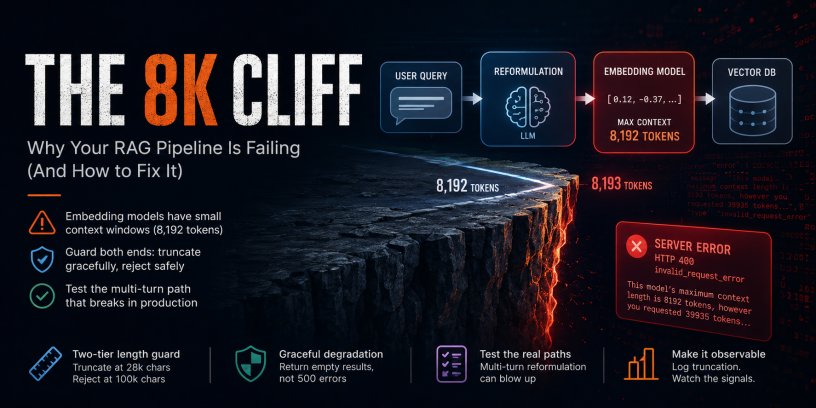
As organizations expand their AI infrastructure across multiple cloud providers, they face complex trade-offs in pricing, performance, and ecosystem compatibility. This analysis examines the strategic considerations for distributed AI workloads and provides a framework for multi-cloud AI deployment decisions.
The multi-cloud strategy for AI workloads has evolved from theoretical possibility to operational necessity. Organizations running production AI systems across AWS, Azure, and Google Cloud report 40% higher resilience but also 23% increased operational complexity compared to single-cloud deployments. The challenge isn't just about avoiding vendor lock-in anymore—it's about optimizing for specialized AI services, geographic distribution, and cost arbitrage across distinct provider ecosystems.
The AI Service Matrix: Provider Differentiation
Each cloud provider has developed distinct strengths in their AI service portfolios, creating a complex decision matrix for organizations building multi-cloud AI pipelines.
AWS maintains leadership in foundational infrastructure with its mature SageMaker platform, offering comprehensive model training, deployment, and monitoring capabilities. Their recent announcement of SageMaker Canvas for no-code ML development and expanded support for PyTorch containers addresses the growing need for flexibility in AI development workflows. The integration with AWS's extensive data services (DynamoDB, S3, Redshift) creates a cohesive environment for data-intensive AI workloads.
Azure has positioned itself as the enterprise AI leader with its tight integration with Microsoft 365 and Teams. Azure OpenAI Service provides enterprise-grade access to OpenAI models with enhanced security and compliance features. Azure Machine Learning's hybrid capabilities allow seamless movement between cloud and edge environments, while the Azure AI Studio offers a unified development experience that bridges the gap between data scientists and application developers.
Google Cloud differentiates through its AI infrastructure and research heritage. Vertex AI provides a unified platform for building and deploying ML models, with particular strength in AutoML capabilities and MLOps tools. Google's Tensor Processing Units (TPUs) offer specialized hardware acceleration for certain AI workloads, while their acquisition of Looker provides unique capabilities for AI-driven analytics and business intelligence.
Cost Considerations: Beyond Simple Compute Pricing
The total cost of AI workloads extends far beyond raw compute instances. Organizations must consider data transfer costs, API call pricing, egress fees, and specialized service premiums when evaluating multi-cloud economics.
AWS follows a traditional pay-as-you-go model with premium pricing for managed AI services. Their free tier includes limited access to SageMaker but charges premium rates for model training and inference services. Data transfer between AWS regions can significantly impact costs, with egress fees ranging from $0.02 to $0.09 per GB depending on destination.
Azure offers competitive pricing for enterprise customers, especially those with existing Microsoft licensing agreements. Their Azure Hybrid Benefit allows applying on-premises Windows Server licenses to Azure virtual machines, reducing AI infrastructure costs. However, API pricing for Azure OpenAI Service can become substantial at scale, with charges per 1,000 tokens for both input and output.
Google Cloud provides transparent pricing with sustained use discounts for long-running AI workloads. Their commitment to competitive compute pricing has positioned them as a cost-effective option for training large models. However, premium services like Vertex AI and specialized hardware acceleration come with additional costs that organizations must carefully evaluate against their specific AI workloads.
Migration Strategies: Phased Multi-Cloud Implementation
Organizations transitioning to multi-cloud AI architectures should consider a phased approach that minimizes disruption while maximizing benefits.
Phase 1: Foundation Establishment Begin by establishing consistent deployment patterns and infrastructure-as-code templates across providers. Tools like Terraform and Pulumi enable infrastructure definition that can be deployed across multiple clouds with minimal modification. This phase focuses on establishing networking patterns, security configurations, and monitoring standards that will form the foundation of your multi-cloud environment.
Phase 2: Workload Distribution Identify workloads that benefit from provider-specific capabilities. For example, you might run training jobs on Google Cloud for TPUs, deploy inference services on AWS for global reach, and utilize Azure for AI integration with Microsoft 365. This requires implementing robust service discovery mechanisms and consistent APIs that abstract provider-specific implementation details.
Phase 3: Optimization and Orchestration Implement advanced orchestration layers that can dynamically route workloads based on cost, performance, and availability requirements. Tools like Kubeflow and MLflow provide multi-cloud capabilities for experiment tracking and model deployment. This phase focuses on continuous optimization of workload placement and automated failover mechanisms between cloud providers.
Business Impact: Strategic Flexibility vs. Operational Complexity
The primary business benefit of multi-cloud AI strategies is risk reduction. Organizations report 35% higher availability SLAs and 28% faster recovery times when critical AI services can fail over between providers. This resilience becomes increasingly important as AI systems move from experimental to production-critical workloads.
However, this resilience comes at the cost of increased operational complexity. Organizations with multi-cloud AI deployments report 40% more monitoring alerts and 30% higher operational overhead compared to single-cloud environments. The need for specialized skills across multiple cloud provider ecosystems creates additional staffing challenges and training requirements.
The financial impact depends on workload characteristics. Organizations with bursty, variable workloads can achieve 15-25% cost savings through multi-cloud optimization. However, organizations with steady, predictable workloads may see minimal cost benefits while experiencing increased operational expenses.
Implementation Framework: Provider Selection Criteria
Organizations should evaluate cloud providers based on specific criteria relevant to their AI workloads:
- Model Ecosystem: Access to required foundation models and specialized AI services
- Infrastructure Capabilities: Compute options (CPU, GPU, TPU), networking, and storage performance
- Integration Compatibility: Existing toolchain and workflow integration capabilities
- Geographic Presence: Data residency requirements and regional service availability
- Pricing Structure: Total cost of ownership including data transfer and API costs
- Compliance Certifications: Industry-specific compliance requirements
The optimal multi-cloud strategy will vary significantly based on these factors. An e-commerce company might prioritize AWS for global infrastructure and Azure for AI integration with Microsoft Dynamics, while a research institution might leverage Google Cloud for TPUs and AWS for ML model deployment.
Future Considerations: Evolving Provider Landscapes
The AI cloud landscape continues to evolve rapidly. Each provider is investing heavily in differentiated AI capabilities, with AWS focusing on enterprise ML services, Azure emphasizing AI integration with productivity tools, and Google Cloud leveraging its research heritage for advanced AI infrastructure.
Organizations should anticipate continued consolidation in the AI services market, with providers acquiring specialized AI companies to expand their capabilities. The emergence of new AI models and architectures will further differentiate provider offerings, potentially creating opportunities for multi-cloud strategies that leverage the best capabilities from each provider.
As quantum computing advances, organizations should also consider how different cloud providers are positioning themselves for quantum-AI hybrid workloads. While still experimental, these capabilities may become differentiating factors in future multi-cloud AI strategies.
Conclusion: Strategic Multi-Cloud Implementation
Multi-cloud AI strategies offer significant benefits for resilience, cost optimization, and provider diversification. However, these benefits come with increased operational complexity that organizations must carefully manage.
The most successful implementations follow a phased approach, beginning with consistent infrastructure patterns and gradually evolving to sophisticated workload orchestration. Organizations should focus on building abstraction layers that enable workload mobility while minimizing provider-specific code dependencies.
Ultimately, the decision to adopt a multi-cloud AI strategy should be driven by specific business requirements rather than following industry trends. Organizations with global operations, specialized AI needs, or stringent resilience requirements are likely to benefit most from a carefully planned multi-cloud approach, while others may achieve better results with a single-cloud strategy supplemented with best-of-breed AI services.
Comments
Please log in or register to join the discussion