Uber has redesigned its Hive data warehouse to decentralize more than 16,000 datasets totaling over 10 petabytes, addressing scalability, operational, and security challenges through a federated architecture that enables zero-downtime migrations and domain-specific autonomy.
Uber has redesigned its Hive data warehouse to decentralize more than 16,000 datasets totaling over 10 petabytes, addressing scalability, operational, and security challenges. Previously, a monolithic Hive instance housed all delivery business datasets under a single namespace, creating risks of cascading outages, resource contention, and governance bottlenecks. By federating Hive databases, Uber aims to maintain high availability, enforce least-privilege access, and allow domain-specific datasets to scale independently, providing teams with operational autonomy.
The migration leverages a pointer-based approach within the Hive Metastore, enabling datasets to be redirected to new HDFS locations without duplicating petabytes of data. Each dataset is copied once to a decentralized target location, then the original pointer is updated, ensuring that queries continue to function during migration. Vijayant Soni, engineer at Uber, explained, "Updating a dataset pointer in HMS is a split-second operation, ensuring continuous functioning for critical workloads." This approach ensures zero downtime for analytics jobs and machine learning pipelines dependent on Hive.
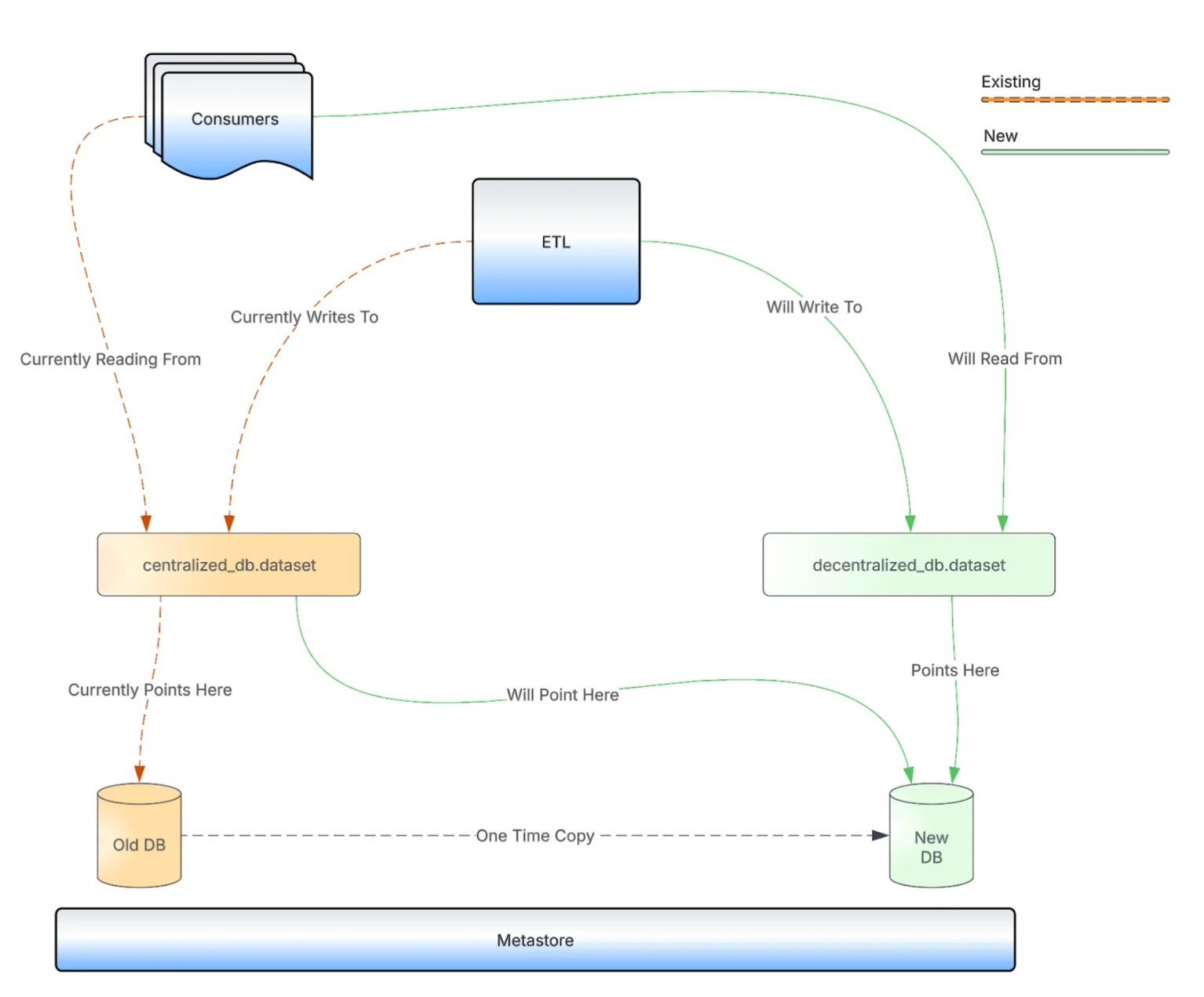
Pointer-based Hive dataset migration showing old vs. new HDFS paths (Source: Uber Blog Post)
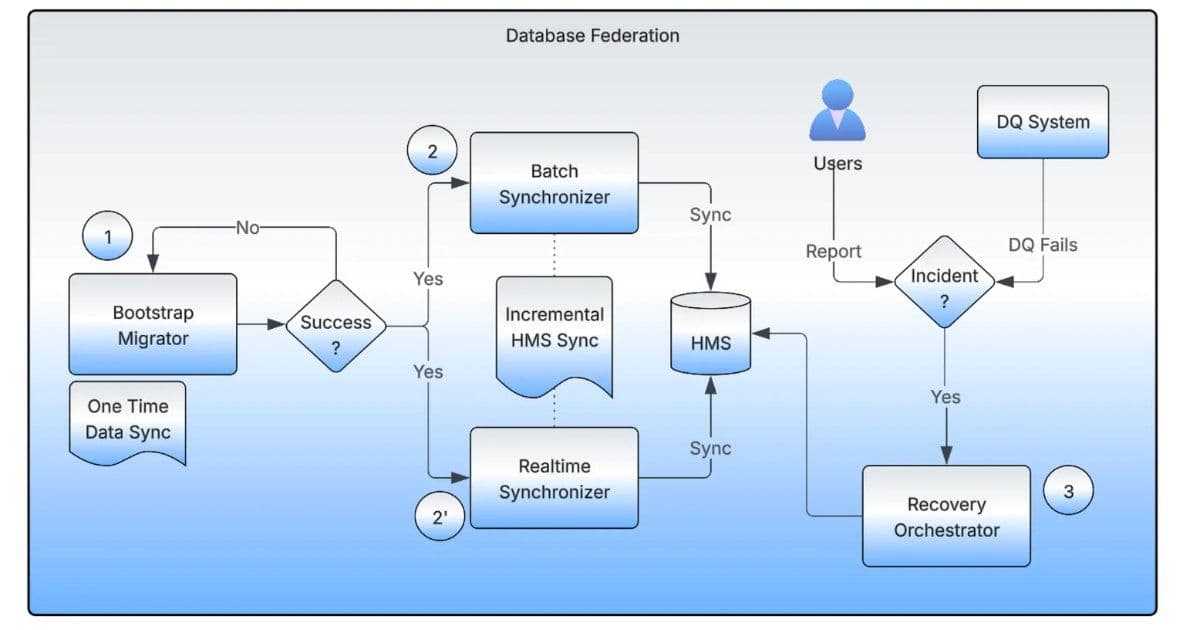
The system supporting this migration includes four key components: the Bootstrap Migrator, Realtime Synchronizer, Batch Synchronizer, and Recovery Orchestrator. The Bootstrap Migrator manages the initial dataset movement, using distributed Spark jobs and checksum verification to validate completeness. Real-time and Batch Synchronizers maintain metadata alignment between source and target during migration, supporting bidirectional updates while teams continue to read and write data. The Recovery Orchestrator tracks pointer backups, enabling safe rollback if inconsistencies are detected. These human-in-the-loop validations and automated checks enable teams to perform migrations with confidence and reduce operational risk.
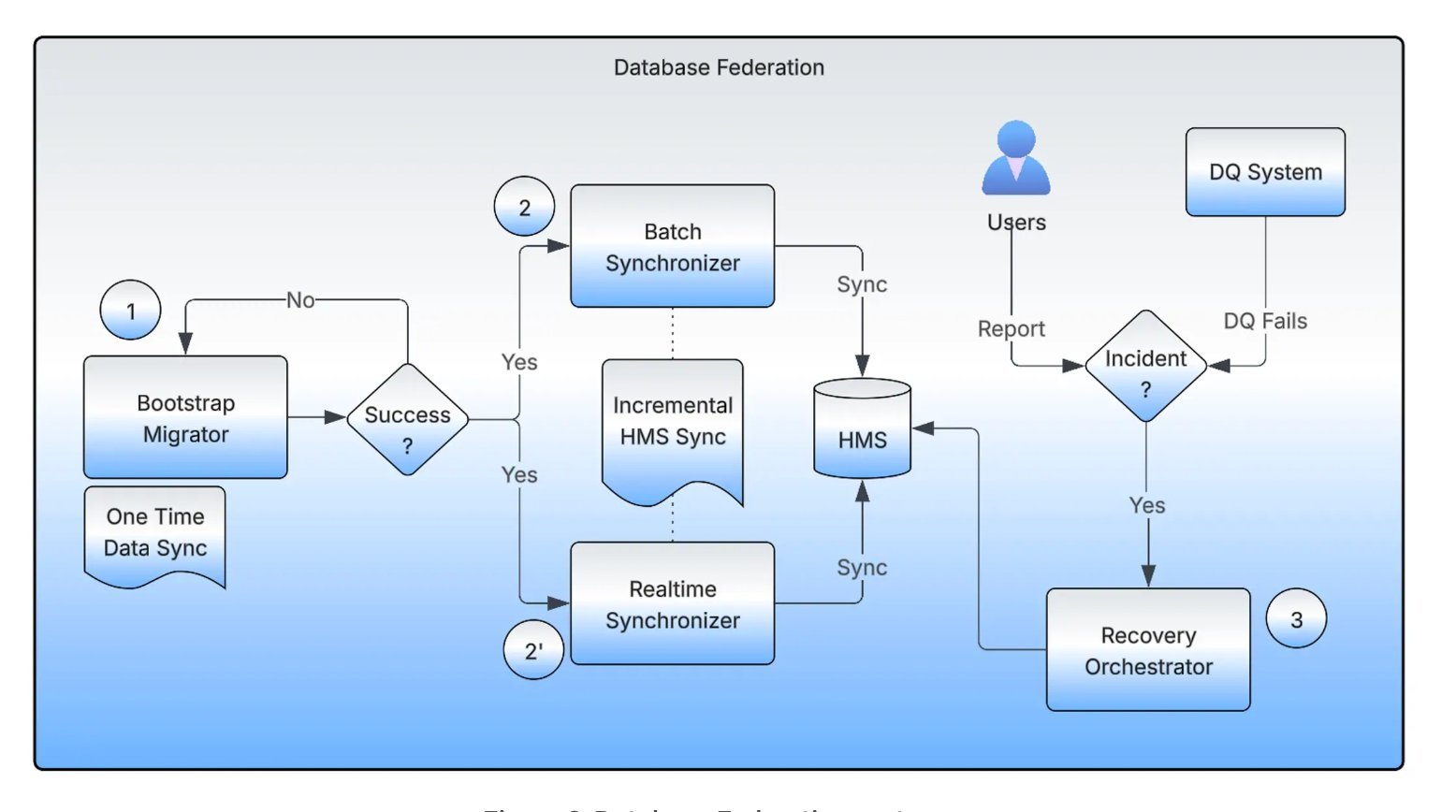
Architecture of the Database Federation system(Source: Uber Blog Post)
Uber's decentralized architecture addresses several limitations of the previous monolithic model. In the old system, multiple teams competed for the same compute and storage resources, leading to noisy neighbor effects that could slow critical workloads. Broad ACL permissions amplified the blast radius of misconfigurations, while centralized governance slowed updates and created bottlenecks. By decentralizing Hive databases and enforcing strict ACLs at the domain level, teams gain ownership of datasets, improving observability, compliance, and workflow efficiency. The migration also reduces storage overhead by avoiding redundant dataset copies and simplifies the onboarding of new datasets. Automated processes, including pre-migration checks and audit logging, ensure that migrations preserve both data integrity and regulatory compliance. Engineers can monitor progress via dashboards that track dataset status, pointer updates, and synchronization metrics, providing transparency and operational confidence.
Throughout the migration, thousands of datasets were moved, over 7 million HMS syncs were performed, and more than 1 PB of HDFS space was reclaimed by removing stale datasets. The approach supports ongoing scaling and ensures that new datasets can be added without disrupting existing workloads. By distributing responsibility across teams, Uber reduces dependency on a central operations team, shortens feedback loops, and improves the resilience of its analytics ecosystem.
This federation approach represents a significant evolution in how large organizations manage their data infrastructure. The pointer-based migration technique demonstrates how careful architectural planning can enable massive data movements without service disruption—a critical capability for organizations running analytics at Uber's scale. The success of this migration provides a blueprint for other enterprises facing similar challenges with monolithic data warehouses, showing that decentralization can deliver both technical and organizational benefits when properly implemented.
Comments
Please log in or register to join the discussion