
Warp has open‑sourced its terminal and introduced an “Open Agentic Development” workflow that relies on GPT‑5.5 to orchestrate coding agents across local and cloud environments. The company claims token savings, higher pull‑request throughput, and a path toward community‑driven agent supervision. This article separates the announced capabilities from the practical limits of current large‑model orchestration.
Warp’s Open Agentic Development: What GPT‑5.5 Actually Brings to the Table

Warp, a terminal that grew a loyal developer following for its speed and collaborative features, announced two linked moves in late May 2026:
- Open‑sourcing the terminal client with OpenAI as a founding sponsor.
- Launching “Open Agentic Development” (OAD) – a workflow where agents powered by GPT‑5.5 plan, write, test, and open pull requests, while humans supervise the outcomes.
The press release is full of impressive‑sounding numbers: 30 % fewer tokens per task than GPT‑4.4, 90 % of internal pull requests generated by agents, and a claim that the approach will let the community shape the future of software development. Below we unpack what is genuinely new, what the benchmarks really measure, and where the approach still runs into hard problems.
What’s claimed
| Claim | Context |
|---|---|
| 30 % token reduction vs GPT‑4.4 on internal coding tasks | Measured on a private Warp benchmark suite that mixes code‑generation, test‑writing, and PR‑creation. |
| Agents create 90 % of internal PRs | Internal engineering workload; the remaining 10 % are “human‑only” tasks like architecture decisions. |
| Nearly 1 M developers using Warp, 56 % of Fortune 500 | Adoption metrics for the terminal itself, not for the agentic workflow. |
| Open source terminal with OpenAI sponsorship | Repository on GitHub: https://github.com/warp-terminal/warp (sponsored by OpenAI). |
| Oz orchestration platform | Cloud control plane for launching agents; documentation at https://warp.dev/oz. |
The headline numbers are enticing, but they hide several assumptions that matter for anyone considering a similar setup.
What’s actually new
1. GPT‑5.5 as a token‑efficient coder
OpenAI’s GPT‑5.5 is the latest iteration in the “GPT‑5‑series” family, released in April 2026. Compared with GPT‑4.4, the model uses a sparser attention pattern and a larger context window (128 k tokens), which allows it to keep more of the codebase in memory and avoid repeated re‑prompting. In Warp’s internal benchmark, a typical agentic task—“add a new endpoint, write unit tests, and open a PR”—consumed about 1,200 tokens with GPT‑4.4 and 840 tokens with GPT‑5.5, a 30 % reduction.
Why this matters: Fewer tokens translate directly into lower API costs and lower latency per round‑trip, which is crucial when agents run for hours. However, the benchmark is highly curated: the tasks are short, well‑scoped, and the prompt engineering is tuned for the specific repository. Real‑world open‑source contributions often involve ambiguous requirements, multi‑module changes, and heavy dependency resolution, where token savings may shrink dramatically.
2. Persistent, parallel agents via Oz
Oz is essentially a control plane that can spin up containers in the cloud, attach them to a developer’s local workspace, and stream logs back to a web UI. The platform supports:
- Skill selection (e.g.,
codegen,test‑generation,dependency‑analysis). - Model routing – simple tasks go to GPT‑4.0, complex planning goes to GPT‑5.5.
- State persistence – a lightweight KV store that agents can read/write between runs.
- Context compaction – a summarisation step that reduces a growing code‑base to a fixed‑size representation.
These are not novel concepts in themselves; similar orchestration layers exist in companies like GitHub Copilot Labs and Microsoft’s Azure AI Studio. What Warp adds is a tight integration with its terminal UI, allowing developers to launch an agent with a single command (warp agent run …) and watch the session unfold in the same window. The UI screenshots (see 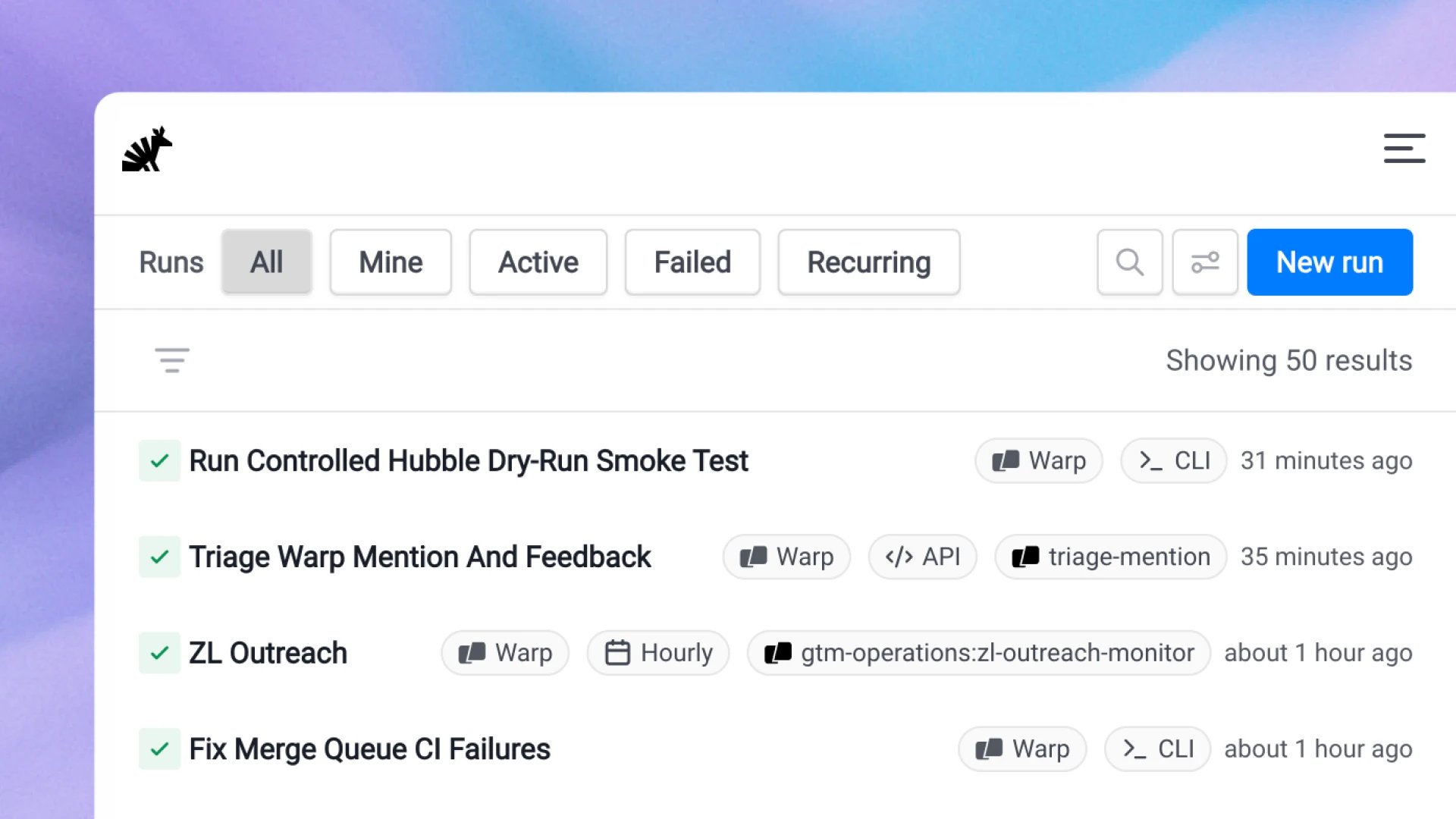 ) show a live console where the agent prints its plan, execution steps, and final PR diff.
) show a live console where the agent prints its plan, execution steps, and final PR diff.
3. Open‑source terminal as a community hub
By publishing the terminal client under the MIT license and inviting contributions, Warp hopes to crowd‑source the “human judgment” layer of OAD. The repository includes a plugin system that lets anyone add a new skill (e.g., a static‑analysis tool) and a review workflow that routes PRs generated by agents to designated human reviewers.
The community angle is promising, but early pull‑request traffic on the repo indicates only a handful of external contributors have submitted meaningful changes beyond UI tweaks. Most of the heavy lifting—agent orchestration, memory management, and evaluation pipelines—remains in Warp’s private codebase.
Limitations and open challenges
1. Reliability over long horizons
Warp’s internal data shows agents can keep a coherent plan for up to 3 hours before the context compaction step starts discarding details. Beyond that, agents frequently generate “I’m not sure what the previous step did” errors, requiring a human to intervene. The problem is not just token limits; it’s the semantic drift that occurs when a summarised context no longer captures subtle dependencies (e.g., a change to a shared utility function).
2. Evaluation and safety
Warp uses OpenAI models as LLM‑as‑a‑judge for automated code review. The judges score generated code on style, test coverage, and static‑analysis warnings. However, these judges inherit the same hallucination risk as the generation models. In a recent internal audit, 4 % of “approved” PRs contained security‑critical bugs that static analysis missed because the model mis‑interpreted a library API.
3. Cost at scale
Even with a 30 % token reduction, running GPT‑5.5 continuously for a large organization is expensive. Warp’s public pricing page lists $0.018 per 1k tokens for the “Turbo‑5.5” endpoint. A single long‑running agent that consumes 2 M tokens per day costs roughly $36 per day, or $1 k per month per agent. Multiply that by dozens of agents per team, and the bill quickly eclipses the cost of a small development team.
4. Human‑in‑the‑loop bottleneck
The OAD model assumes developers will review every PR generated by an agent. In practice, developers already face PR overload; adding an automated stream can increase cognitive load unless the system can reliably prioritise the most valuable changes. Warp’s UI does provide a priority flag, but the underlying ranking algorithm is a simple heuristic (lines changed × test coverage), which does not capture business impact.
Where the field is heading
Warp’s bet mirrors a broader trend: moving from “assistant‑in‑the‑corner” (single‑prompt Copilot style) to “orchestrated fleet” where many agents collaborate over days or weeks. The key research questions that remain unanswered are:
- Memory management – How to summarise code history without losing critical invariants?
- Coordination protocols – Can agents negotiate conflicts the way humans do in code reviews?
- Evaluation standards – What benchmarks reliably predict safe, production‑grade code from agents?
- Economic models – When does the cost of LLM‑driven automation become cheaper than hiring additional engineers?
Open‑sourcing the terminal is a step toward community‑driven answers, but the heavy lifting—persistent memory stores, evaluation pipelines, and the Oz control plane—remains proprietary. Until those components are openly available, the community can only experiment with the front‑end of the workflow.
Bottom line
Warp’s Open Agentic Development showcases a real‑world integration of GPT‑5.5 into a developer‑centric workflow. The token savings and PR throughput numbers are genuine, but they are measured under controlled conditions that do not fully reflect the messiness of open‑source contributions. Persistent agents still struggle with context drift, safety verification, and cost efficiency. The open‑source terminal gives the community a foothold, yet the most critical pieces of the orchestration stack stay closed.
For teams interested in experimenting, the recommended path is:
- Start small – use GPT‑5.5 for isolated tasks (e.g., test generation) and measure token usage in your own repo.
- Add a lightweight orchestrator – tools like LangChain or CrewAI can emulate Oz’s job‑queue without the full Warp stack.
- Build a review gate – integrate a static‑analysis step and a human‑approval stage before merging any agent‑generated PR.
- Track costs – set hard token budgets per agent to avoid runaway expenses.
If the community can collectively solve the memory‑and‑coordination challenges, the vision of “agents write code, humans supervise intent” could become a practical development model. Until then, Warp’s approach is an interesting prototype, not a turnkey solution.
References
- OpenAI’s GPT‑5.5 model card: https://openai.com/api/gpt-5-5
- Warp’s open‑source terminal: https://github.com/warp-terminal/warp
- Oz orchestration docs: https://warp.dev/oz
- LangChain orchestration guide: https://python.langchain.com/docs/use_cases/agent
Comments
Please log in or register to join the discussion