LLMs
KVBoost: Optimizing LLM Inference Without Model Surgery
5/22/2026

LLMs
Multi-Stream LLMs: Parallelising Thought, Input and Output to Unblock Language Agents
5/21/2026
LLMs
DeepSeek launches Harness team to chase Anthropic’s Claude Code
5/21/2026
LLMs
Forge Framework Boosts Small LLM Performance on Complex Tasks with Advanced Guardrails
5/20/2026

LLMs
Gemini 3.5: How the New Agentic Model Is Shaping Developer Workflows
5/19/2026
LLMs
Andrej Karpathy joins Anthropic to focus on LLM research and education
5/19/2026
LLMs
LLMCap Introduces Hard Dollar Caps on LLM API Calls
5/19/2026
LLMs
Azure App Service Self-Healing Agents: Redefining LLMOps for Production
5/19/2026

LLMs
The Last Six Months in LLMs: From Coding Agents to Laptop Models
5/19/2026
LLMs
Alibaba's Qwen3.7 Preview Models Released on Arena Platform
5/18/2026
LLMs
Cursor’s Composer 2.5: What the New Claims Mean for LLM‑powered Coding Assistants
5/18/2026
LLMs
When Open‑Source Experiments Turn Into Public Drama: The Bun‑to‑Rust Transpilation Story
5/17/2026
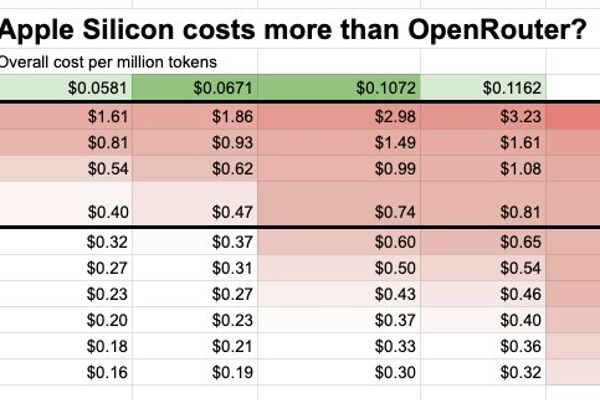
LLMs
Apple Silicon vs. OpenRouter: A Cost‑and‑Speed Reality Check
5/17/2026