A comprehensive guide to advanced Terraform performance optimization techniques, covering init, plan, and apply phases with practical solutions for large-scale infrastructure management.
When managing large-scale infrastructure with Terraform, performance bottlenecks can significantly impact your team's productivity. After presenting my findings at SREcon, HashiConf, and SREDay, I've compiled this comprehensive guide to advanced Terraform performance optimization techniques that go beyond the basics.
The Init Phase: Modules and Providers
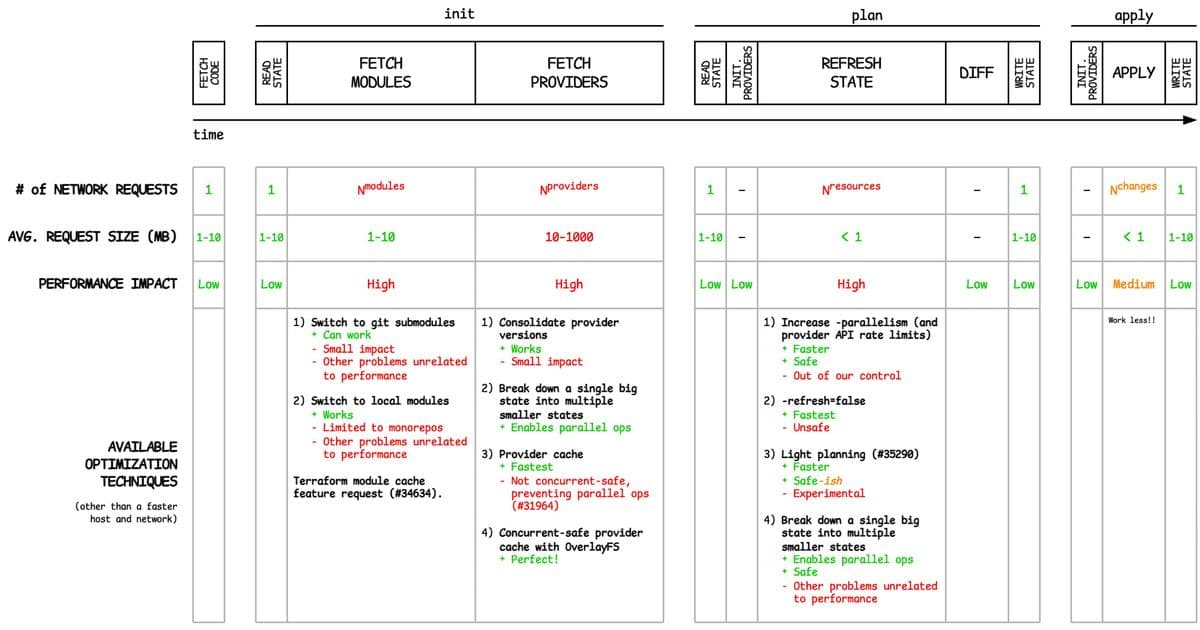
The init phase involves downloading modules and providers, which can become a significant bottleneck at scale.
Module Fetching Challenges
Fetching remote modules requires one network request per module, typically 1-10MB each. When dealing with hundreds or thousands of modules, init times can become prohibitive.
Git Submodules Approach Switching to git submodules can be surprisingly effective if your CI/CD platform supports submodule caching. While it trades Terraform module fetches for git submodule fetches, the performance gain comes from only pulling changes between runs rather than full module downloads.
Local Modules Strategy Converting remote modules to local ones shifts the burden to a single larger root module download. This works well with repository caching systems that only pull changes between runs. However, this approach sacrifices module versioning and isolated CI validation capabilities.
The Missing Module Cache Terraform lacks a built-in module cache, which would be the ideal solution. The feature request has been open for some time, but until it's implemented, teams must find workarounds for this bottleneck.
Provider Binary Downloads
Provider binaries are massive compared to modules. The AWS provider alone exceeds 750MB, and with multiple versions and providers, you're downloading several gigabytes per init.
Provider Version Consolidation Aligning all modules to use the same provider version (or at most one per major version) can significantly reduce download volume. While the performance impact is modest, it's excellent operational hygiene.
Root Module Decomposition Breaking monolithic root modules into smaller ones can distribute the provider load more evenly. This approach also enables parallel operations and can address other productivity issues. However, it introduces significant complexity around dependency tracking, plan ordering, and infrastructure-wide consistency.
Concurrent-Safe Provider Caching Terraform's built-in plugin cache is not concurrent-safe, leading to corruption when multiple init processes write simultaneously. The OverlayFS solution creates isolated cache views for each process while maintaining a shared cache, eliminating corruption risks while preserving speed.
The Plan Phase: State Refresh Optimization
State refresh is the most expensive step in the plan phase, querying every resource against provider APIs to detect drift.
Parallelism and Rate Limits Increasing parallelism can dramatically reduce refresh time, but you'll eventually hit provider API rate limits. This is the safest optimization approach, though it has natural boundaries.
Disabling Refresh
Using -refresh=false provides the fastest option but introduces significant safety risks. Without pre-plan refreshes, drift detection fails, potentially leading to dangerous changes. Scheduled full refreshes can mitigate this risk somewhat, but consistency remains a concern.
Light Planning Approach
My proposed terraform plan -light flag would only refresh resources whose code has changed since the last run, targeting those resources and their dependents. This balances speed and safety more effectively than the binary refresh/no-refresh choice.
Module Decomposition Again Splitting into smaller root modules reduces the scope of each operation, but as mentioned earlier, this introduces substantial complexity that teams must carefully consider.
The Apply Phase: Making Fewer Changes
Unlike the init and plan phases, the apply phase has limited optimization options. The primary strategy is simply to make fewer changes.
This limitation stems from the fundamental nature of the apply phase—you're executing the planned changes, and there's no way around the network operations required to make those changes happen.
Experimental and Dangerous Techniques
Some optimization techniques carry significant risks:
- Disabling state refresh entirely
- Aggressive parallelism that may trigger API limits
- Complex module decomposition strategies
- Experimental caching mechanisms
These approaches can provide substantial performance gains but require careful consideration and testing before production deployment.
The Path Forward
While this guide covers many optimization techniques, Terraform performance remains an active area of exploration. The community continues to develop new approaches, and Terraform itself evolves with features like improved caching and planning capabilities.
For teams pushing Terraform to its limits, the key is balancing performance gains against operational complexity and safety risks. Sometimes the fastest solution isn't the safest, and sometimes the safest solution isn't fast enough.
What optimization techniques have you found effective in your Terraform deployments? The landscape continues to evolve, and sharing experiences helps the entire community move forward more efficiently.
Comments
Please log in or register to join the discussion