The most important fact is not that Fable 5 was pulled. It is that a frontier coding and cyber-capable model crossed from product launch into export-control territory within days.
What's claimed
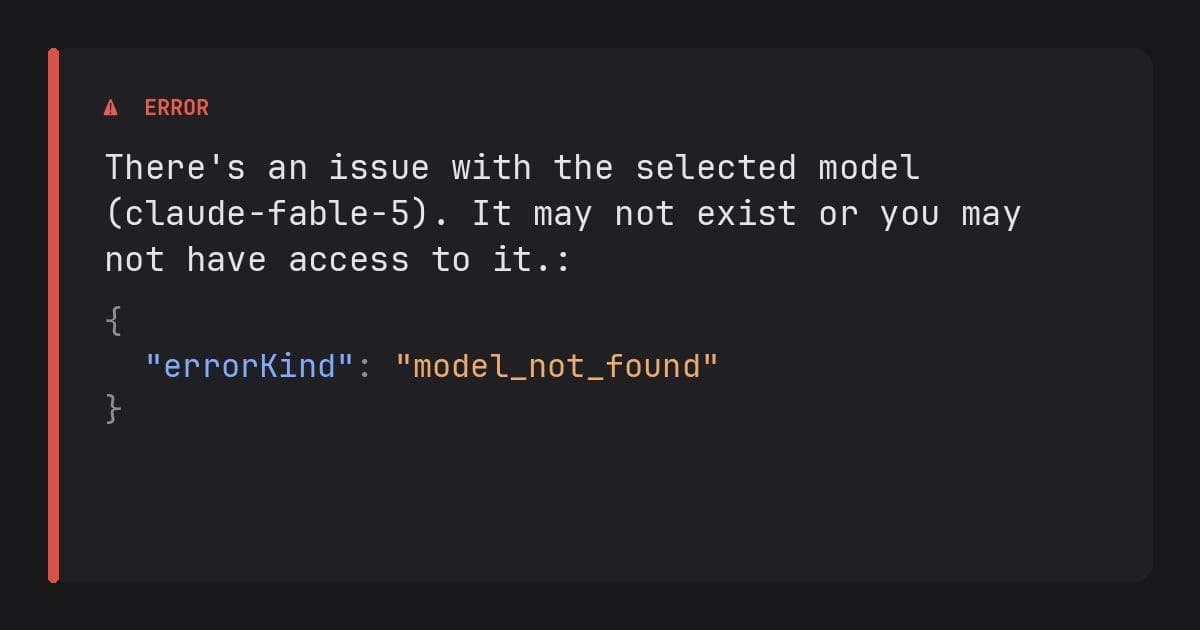
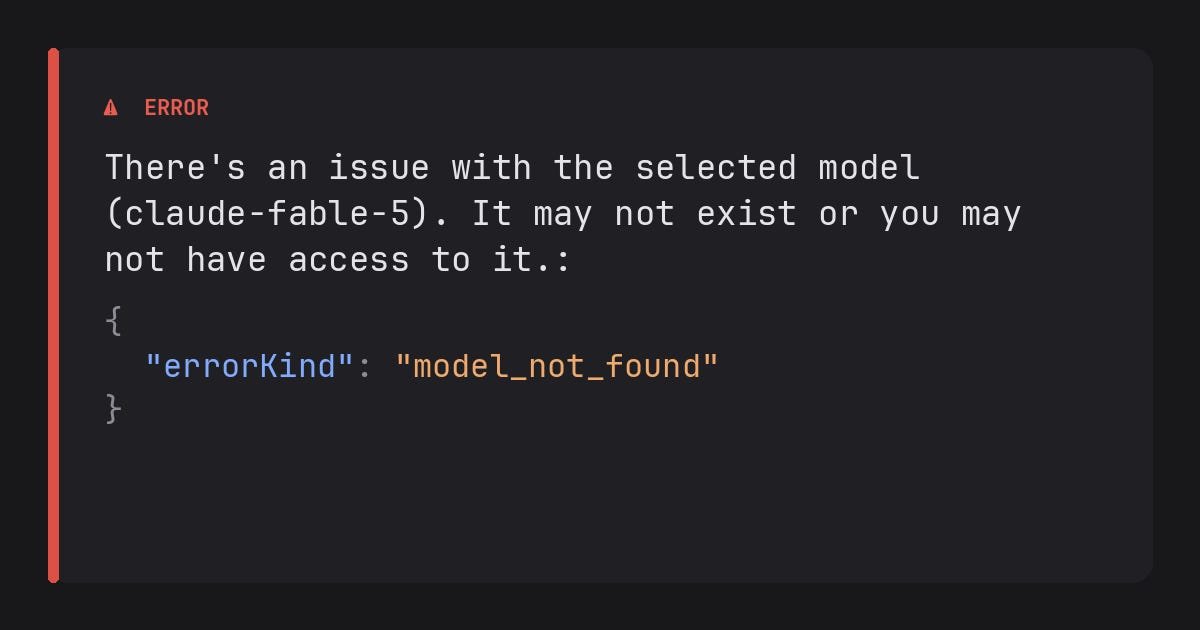
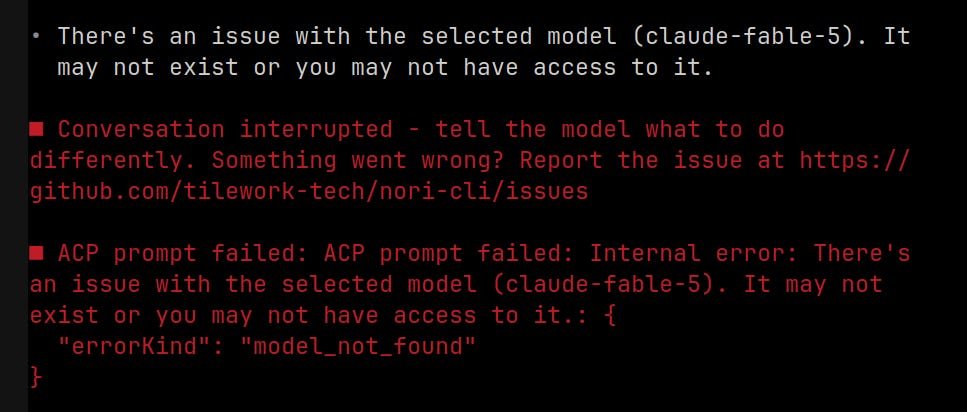
Anthropic says the U.S. government issued an export-control directive on June 12, 2026 requiring it to suspend access to Claude Fable 5 and Claude Mythos 5 for any foreign national, including foreign nationals inside the United States and foreign national Anthropic employees. In its official statement, Anthropic says it disabled both models for all customers because complying selectively was not practical on short notice.
The company’s version of the technical concern is narrow. Anthropic says the government appears to be worried about a jailbreak of Fable 5, but that the demonstrated behavior involved finding a small number of already known, relatively simple software vulnerabilities. Anthropic also says comparable capability is available from other models, including OpenAI’s GPT-5.5, and that defenders use this class of model-assisted vulnerability discovery every day.
That is the key technical dispute. The government appears to be treating Fable 5 and Mythos 5 as controlled dual-use capability. Anthropic is arguing that the specific evidence does not justify recalling a commercial model, especially when the capability is not unique to Fable 5.
What's actually new
Fable 5 and Mythos 5 are not just another pair of renamed Claude releases. Anthropic’s launch post describes Fable 5 as a general-access version of a Mythos-class model, with safety classifiers that route risky requests to Claude Opus 4.8. Mythos 5 is the same underlying model with some safeguards lifted for trusted cybersecurity and biology partners, initially through Project Glasswing.
The model names matter because the product split is the policy. Fable 5 is meant to give normal users the benefit of a stronger model while blocking or downgrading requests in cybersecurity, biology, chemistry, and suspected distillation. Mythos 5 is meant for vetted users who need the full capability for defensive security or scientific work.
Anthropic claimed strong benchmark and field-test results before the shutdown. It said Fable 5 was state of the art on nearly all tested capability benchmarks, led on Cognition’s FrontierCode evaluation, topped Hebbia’s senior-level finance benchmark, and showed major gains in long-horizon coding, document reasoning, vision, memory, and scientific research. Publicly visible numbers are limited, but the launch post includes several concrete claims: more than 95% of Fable sessions avoid fallback, safety triggers average under 5% of sessions, external red teams found no universal jailbreak in more than 1,000 hours, and one partner test found zero compliance on harmful single-turn cyber requests across attack planning, exploit development, and defense evasion prompts.
The practical examples are more informative than the benchmark labels. Anthropic says Stripe used Fable 5 to run a codebase-wide migration across a 50-million-line Ruby codebase in one day, a task estimated at more than two months of team effort by hand. It also says Fable 5 can rebuild web app source from screenshots, complete Pokemon FireRed with a minimal vision-only harness, and maintain focus across million-token work sessions using persistent notes.
On the Mythos side, Anthropic’s claims are more sensitive. The company says Mythos 5 has the strongest cybersecurity capabilities of any model it has evaluated, can help defenders secure important software, and has shown useful performance in protein design, bioinformatics workflows, molecular biology hypotheses, and genomics research. One claim in the launch post is that internal protein design experts saw roughly a 10x acceleration on parts of drug design, with Mythos 5 matching or beating skilled human operators on a tool-using protein design task.
This is the core reason the shutdown matters. The model is valuable because it appears better at long-horizon, tool-using technical work. The model is risky for the same reason. A system that can autonomously inspect a large codebase, reason about failures, choose tools, recover from dead ends, and produce useful patches is exactly what defenders want. It is also what attackers want, once the task changes from remediation to exploitation.
Fable’s safety design is an attempt to separate those cases with classifiers. That is a brittle place to put a policy boundary. A classifier can detect many obvious unsafe requests, but real engineering work is messy. A request to audit a parser, reproduce a crash, generate a proof of concept, or fix a memory-corruption bug can be defensive, offensive, or both depending on context. Anthropic’s own launch materials admit that benign requests will sometimes be routed away from Fable 5 to Opus 4.8.
The government action changes the stakes from product safety to infrastructure reliability. If a model can be launched on Monday and effectively pulled by government directive on Friday, enterprises will price that into adoption. That affects not only Anthropic’s API customers, but also agent platforms, coding tools, security teams, and research groups building workflows around model-specific behavior.
Limitations
There are three gaps in the public record.
First, the government has not publicly shown the jailbreak or the technical report behind the directive. Without that, outside observers cannot tell whether the issue is a routine non-universal bypass, a stronger multi-step attack, or something tied to classified context. Anthropic says it received only limited evidence and that the letter did not provide specific technical details. That may be true, but it also means the public is being asked to evaluate a safety decision without the artifact that motivated it.
Second, Anthropic’s benchmark story is still mostly vendor-controlled. Claims like “highest on FrontierCode,” “highest on CursorBench,” or “highest score on a finance benchmark” are useful signals, but they are not the same as independent, reproducible evaluation. The strongest evidence in the launch post is operational: long code migrations, defensive security work, and scientific tool use. Those are also the hardest claims for outsiders to audit.
Third, the safety boundary is not clean. Fable 5 falls back to Opus 4.8 for flagged topics, but fallback is not the same as solving misuse. It can reduce model uplift in obvious cases. It can also frustrate legitimate users, especially security engineers who need help with exactly the class of code analysis that looks suspicious to a classifier.

A hype-heavy reading says Fable 5 was so powerful the government had to pull it. A more careful reading is that frontier models are entering a zone where coding, cybersecurity, biology, and autonomous tool use are no longer separable product categories. The model that can migrate a huge Ruby codebase can also reason about vulnerabilities. The model that can accelerate protein design can also raise harder biosecurity questions. The model that can run for hours with memory and tools is harder to govern than a chatbot that answers isolated questions.
The best interpretation is not that Anthropic is obviously right or that the government is obviously right. The evidence available today supports a narrower conclusion: Fable 5 and Mythos 5 exposed a regulatory mismatch. Model labs are shipping systems whose most valuable features are also the features that make export control and safety review difficult. A Friday-night access cutoff is a crude instrument for that problem.
For ML practitioners, the lesson is practical. Do not build critical workflows on a single frontier model without a fallback plan. Track model behavior, not just benchmark rankings. Treat safety classifiers as part of the product surface, because they will shape what your agent can and cannot do. And when a lab says a model is unusually capable, read the system card and deployment restrictions before reading the launch quotes.
Comments
Please log in or register to join the discussion