architect-loop is less an AI coding miracle claim than an attempt to make multi-agent software work auditable: specs first, isolated builders, external gates, and a reviewer that treats passing tests as evidence, not proof.
architect-loop is a GitHub project that packages a cross-vendor agent workflow as two Claude Code skills: /architect for implementation and /architect-research for research. The claimed pairing is Claude Fable 5 as the architect and reviewer, GPT-5.5 Codex as the builder and researcher, with the repository acting as the shared memory layer.
What's claimed
The project’s core claim is operational, not benchmark-driven: use the stronger planning model for specification and review, then send implementation work to Codex CLI workers in fresh contexts. The README describes a loop where Claude Fable writes the spec and acceptance gates first, splits the work into 1 to 4 lanes, dispatches isolated Codex builders in separate git worktrees, then reviews the resulting diffs and test evidence before integration.
That matters because most agentic coding failures are not just bad code generation. They are failures of scope control, stale context, weak review, and vague success criteria. architect-loop tries to constrain those failure modes with repo artifacts: docs/gates/, docs/lanes/, docs/HANDOFF.md, and git history. In this design, memory is not a hidden chat transcript. If the next run needs to know something, it has to be written into the repo.
The implementation loop is exposed through /architect. The research loop is exposed through /architect-research. Installation is intentionally ordinary: clone the repository, run the installer, and install the OpenAI Codex CLI at version 0.133 or newer. By default, the project says it relies on existing Claude Code and ChatGPT subscriptions rather than requiring direct API keys.
The model names are specific: Claude Fable 5 is positioned as planner, reviewer, and judge. GPT-5.5 Codex is positioned as builder and researcher. The practical target is not single-prompt code generation. It is longer-running repository work where one agent session decides what should happen, multiple fresh Codex sessions execute bounded slices, and a final review step determines whether the work should enter the branch.
There are no supplied benchmark results in the project description. No SWE-bench score, no pass@k result, no head-to-head table against Claude Code alone, Codex alone, Cursor agents, Devin-style systems, or human baselines. The closest thing to evaluation is procedural: frozen gates, worktree isolation, raw command output, tamper checks, file-boundary enforcement, and architect review. That is useful engineering discipline, but it is not a benchmark.
What's actually new
The interesting part is not that one model calls another model. That pattern is already common in agent frameworks and developer workflows. The more substantive idea is that architect-loop treats multi-agent coding as a repository protocol rather than a chat protocol.
In the /architect flow, the architect first writes acceptance gates to docs/gates/. Those gates are supposed to be read-only for builders. If a builder edits a gate file, the slice fails. That is a simple but meaningful guardrail. Visible tests can be gamed, intentionally or accidentally. Freezing them before implementation at least creates a stable target and gives the reviewer something concrete to compare against.
The lane model also addresses a real concurrency problem. When multiple agents edit the same repository, coordination falls apart quickly if they share mutable context and overlapping files. architect-loop splits the task into lanes with declared file sets, then runs each builder in a separate git worktree. That gives each Codex session a clean workspace and makes overlap detectable before merge time.
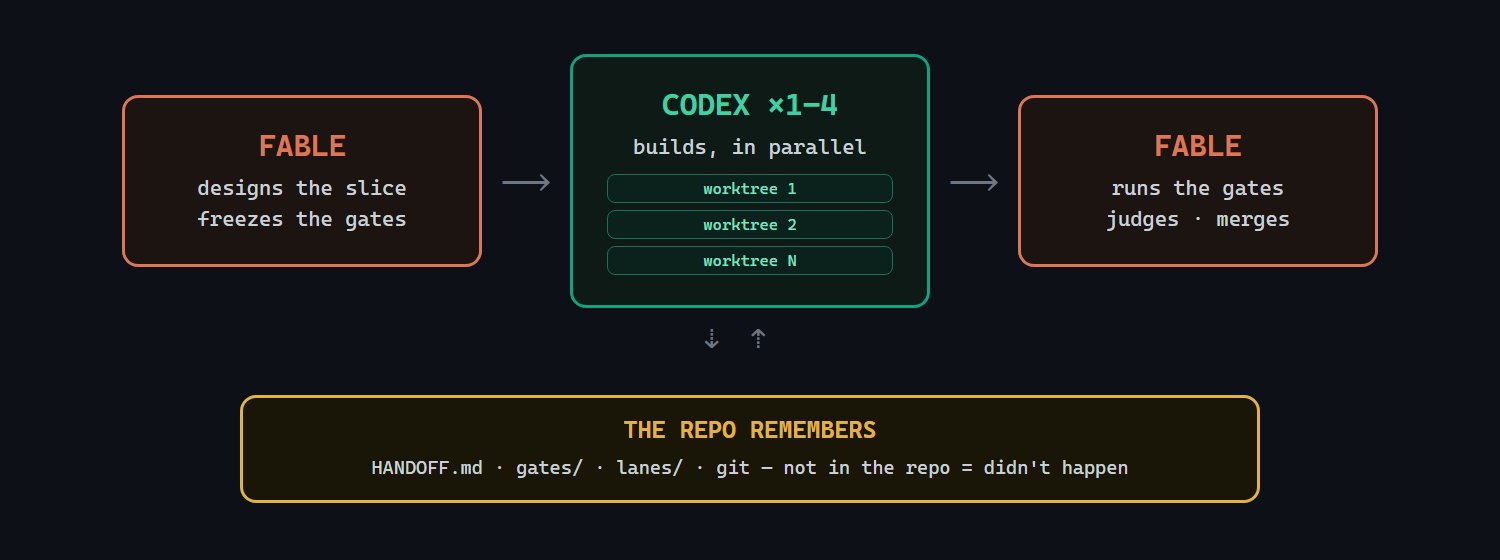
The builder role is deliberately narrow. Builders do not get commit access in the sandbox. They must report raw results. Their claims are treated as hearsay until the architect reruns or inspects the evidence. This is a healthy bias. Agent reports often sound more complete than the diff justifies. A passing test suite can still hide a bad abstraction, a missed edge case, or a change that technically satisfies a gate while violating the intended design.
The research side is more ambitious. /architect-research uses a scout pass to map a topic before assigning lanes. The scout looks for canonical terminology, important systems and papers, named people, and the fault lines in the topic. Then Fable designs 3 to 6 topic-specific lanes instead of using a fixed taxonomy. Codex researchers run in parallel with budgets, source constraints, and a findings format that requires URL, date, quote, and confidence tag.
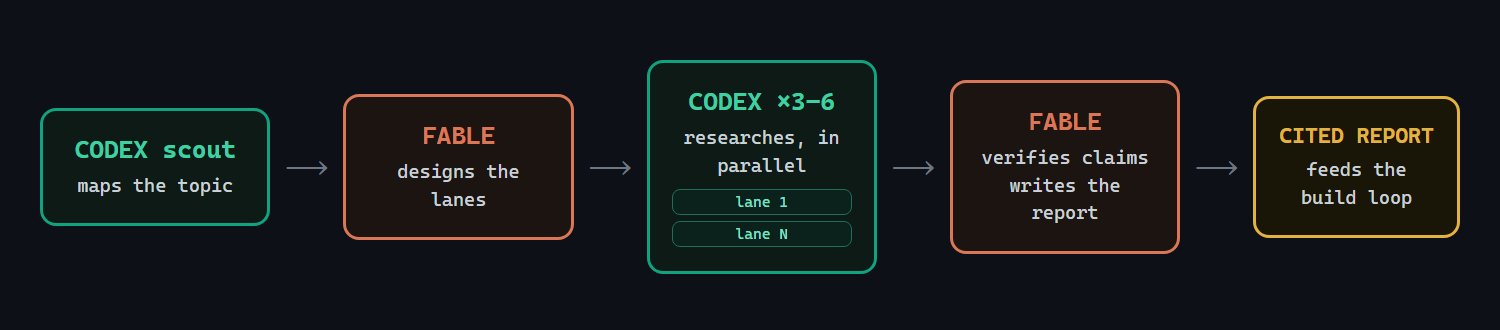
That design is sensible for technical research because the useful decomposition depends on the subject. A research plan for inference serving should not look like a research plan for synthetic data, evals, memory systems, or GPU scheduling. Fixed lanes tend to produce tidy reports that miss the load-bearing disagreements. architect-loop’s approach tries to map the topic first, then assign work.
The repo also includes a design rationale in DESIGN.md, skill definitions under skills/architect, and research orchestration under skills/architect-research. The test file tests/validate_skills.py appears aimed at repository sanity checks for the skill files, not end-to-end coding performance.
For practitioners, the most useful application is probably not replacing an engineer. It is structuring work that already benefits from explicit decomposition: refactors with measurable gates, multi-file feature slices, migration planning, bug investigation, technical due diligence, and research reports that need source discipline. The system is strongest where the task can be broken into bounded lanes and where the reviewer can verify concrete artifacts.
Limitations
The main limitation is that the project’s claims are process claims, not measured outcome claims. The README argues for a disciplined architecture, but it does not provide benchmark results showing improved merge rate, lower defect rate, shorter cycle time, or better research accuracy. Without those numbers, users should treat architect-loop as a workflow experiment with good instincts, not as validated evidence that Claude Fable 5 plus GPT-5.5 Codex beats simpler setups.
The second limitation is model and product availability. The project assumes access to Claude Code on a paid plan and Codex CLI signed into a ChatGPT plan. It also names specific frontier models. If those models are unavailable, renamed, rate-limited, or behaviorally different across accounts, the workflow may not reproduce the author’s experience. Subscription quota is another practical constraint. Parallel Codex workers can consume meaningful portions of usage windows during longer jobs.
The third limitation is that gate quality becomes the bottleneck. Frozen gates only help if they test the right behavior. Weak gates can create false confidence. Overly narrow gates can encourage local fixes that satisfy the test but damage the larger system. Overly broad gates can slow every lane until the loop becomes too expensive to use. The architect model still has to write good specs, pick useful acceptance checks, and recognize when a passing diff is not mergeable.
There is also a social limitation. A workflow that says “not in the repo equals didn’t happen” is excellent for auditability, but it requires discipline. Engineers have to keep the handoff file short, preserve useful lane records, and avoid turning repo memory into another stale documentation pile. The project tries to address that by pruning docs/HANDOFF.md and keeping detail in linked artifacts, but maintenance pressure remains.
The research mode has similar trade-offs. Requiring citations from fetched URLs, independent sources for load-bearing claims, and adversarial falsification searches is the right instinct. It also makes research slower and more expensive than a normal chat query. That is not a flaw if the output informs architecture or product decisions, but it is too heavy for routine lookups.
The best read of architect-loop is that it packages several mature engineering habits into an agent workflow: write the spec before the code, isolate parallel work, make success criteria external, distrust unverified status reports, review diffs against intent, and keep shared memory in version control. Those ideas are not flashy. They are exactly why the project is interesting.
Comments
Please log in or register to join the discussion