Bayer and Thoughtworks built PRINCE to help scientists query decades of preclinical study reports with retrieval, SQL, citations, retries, and expert review.
Bayer AG and Thoughtworks built the Preclinical Information Center, or PRINCE, to help researchers search, question, and draft from decades of preclinical safety study reports. The team describes the work in Building Reliable Agentic AI Systems, published June 16, 2026.
The system shows a pattern that many enterprise AI teams now face. A lab, bank, insurer, or manufacturer owns years of documents and tables. Researchers need answers across both. A chatbot alone cannot handle that job. Engineers need retrieval, SQL, workflow state, citations, evaluation, fallbacks, and human review.
Bayer’s team started with search over structured study metadata. Researchers could filter reports, but they still had to read large PDF files to answer compound, species, dose, route, and finding questions. The approved PDFs carried the source of record, while metadata from older migrations could contain gaps.
The team expanded PRINCE from search to natural language question answering, then to an agentic assistant that can plan work, call tools, inspect evidence, and draft structured answers for expert review.
The problem: preclinical data spans reports and tables
Preclinical researchers work across structured data and long scientific reports. A question about a study may need a row from a metadata table, a paragraph from a toxicology report, and a citation from a scanned PDF.
Keyword search breaks down in that setting. Scientists use terms with domain nuance. Historical reports use old phrasing. A user may ask whether piloerection, ataxia, eyes partly closed, and loose feces occurred in one study. A keyword engine may miss synonyms, context, or study-level constraints.
A single large language model prompt fails for another reason. Engineers cannot put decades of reports and schema into one context window and expect a useful answer. Larger context windows reduce pressure, but they do not remove the need for selection. The team had to decide which facts each model step should see.
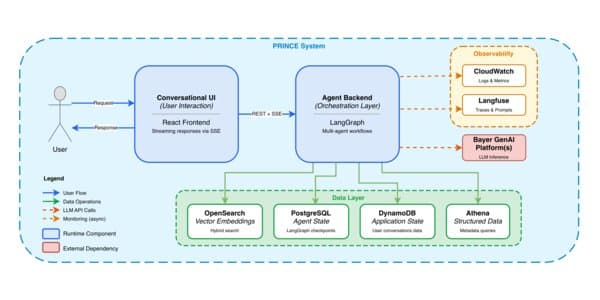
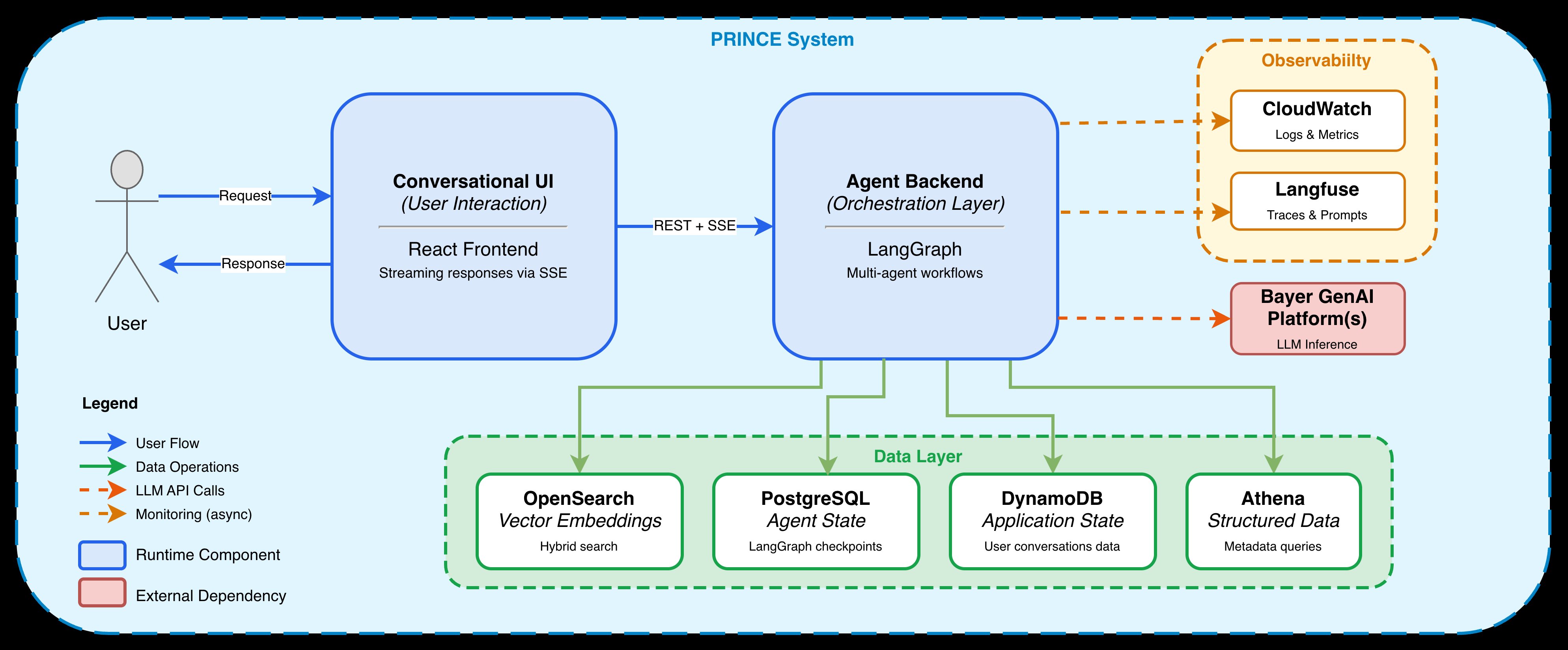
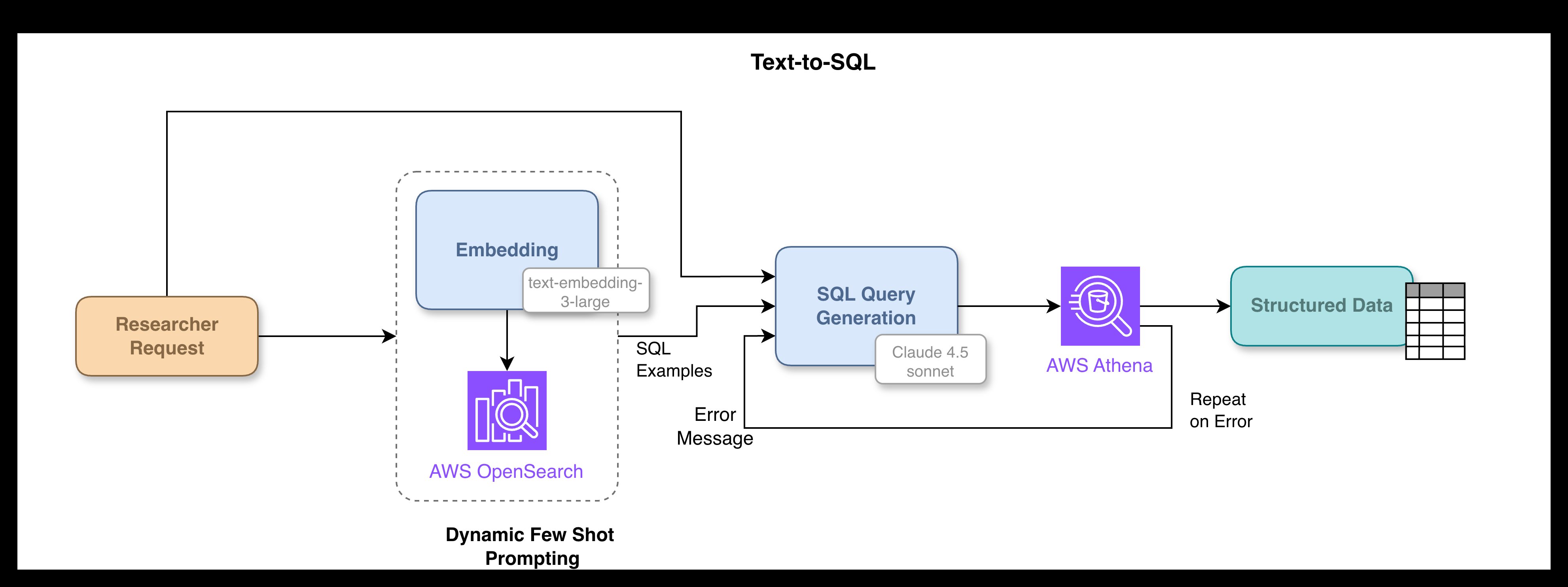
PRINCE uses two retrieval patterns. The team uses retrieval-augmented generation for unstructured reports and Text-to-SQL for structured metadata in Amazon Athena. Engineers use LangGraph to coordinate those steps and FastAPI to serve the backend. Users interact through a React interface.
The solution approach: divide the work into agents
Bayer and Thoughtworks split the workflow into steps with clear jobs: clarify intent, plan work, retrieve evidence, check data sufficiency, and write the answer.
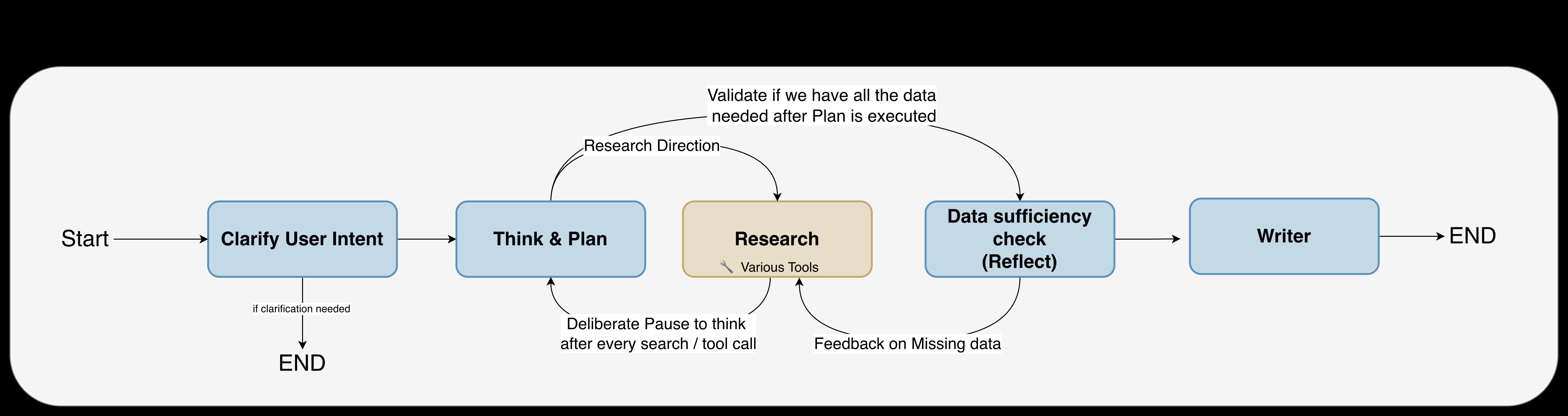
The clarify step asks the user for more detail when a question spans domains or lacks a source. A toxicology question and a pharmacology question may use the same word, such as study, but require different tables, indexes, and interpretation rules. Early clarification cuts wasted tool calls and reduces wrong-source answers.
The planning step gives the model a place to choose the next action. The team calls this process reflection. The agent checks whether it has selected the right tool, whether the last call moved the work toward the user’s request, and whether it needs another retrieval step.
The researcher step gathers evidence. For unstructured reports, engineers built a RAG pipeline over study PDFs. They extract text, normalize it into JSON, split it into chunks, add study and section metadata, embed the chunks, and index them in Amazon OpenSearch Service. At query time, the team extracts keywords, builds metadata filters, expands the query, runs hybrid search, reranks candidates, and sends selected chunks to the model with citation requirements.
For structured data, the researcher uses Text-to-SQL against Amazon Athena. The system gives the model the schema parts that match the user’s query. It retrieves few-shot examples from a semantic layer, asks the model to produce Athena SQL, blocks destructive statements, and limits results to 50 records. If Athena returns an error, the same model receives the error and tries a repair, with a cap on retries.
The reflection step checks evidence, not process. The reflection agent compares the gathered material with the original question. If the answer needs more data, it sends follow-up questions back to planning. If the evidence supports an answer, the workflow moves to writing.
The writer step turns evidence into the final response. The writer must cite source chunks and study IDs, follow the user’s requested format, and use domain answer patterns that Bayer scientists accept. For regulatory drafting, the team keeps expert review in the path. Qualified staff author and approve final submissions.
Context engineering gives each step a tighter job
PRINCE shows why production AI teams need context engineering. The team does not treat the prompt as a dumping ground. Engineers choose context for each step.
The planner sees user intent and tool descriptions. The researcher sees query details, schemas, examples, and retrieval targets. The reflection agent sees the original question and gathered evidence. The writer sees curated evidence and citation rules.
That separation helps engineers debug failures. If the system picks the wrong tool, the team can inspect the planning step. If it retrieves weak chunks, they can tune metadata filters, query expansion, search weights, or reranking. If the final answer omits a section, they can adjust the writer or add a draft review step.
This design also helps with consistency. A single agent with a flat tool list can confuse domains that share labels but differ in source of truth. The team plans domain sub-agents, such as toxicology and pharmacology agents, each with its own prompts, tables, indexes, and retrieval rules. The top-level researcher can route work while each domain team owns its data contract.
Harness engineering keeps the model inside bounds
The team built a harness around the models because production users need more than fluent text. Engineers need recovery, traceability, evaluation, and operational control.
PRINCE stores LangGraph execution state in PostgreSQL after each node. The application stores broader state, logs, intermediate steps, and citations in DynamoDB. If a node fails, the system can resume from that point rather than restart the whole workflow.
The team added retries at two levels. Individual model calls can retry after transient failures. Whole workflow nodes can retry when a step fails. If the primary model fails after retries, the application can call another model from a different provider through an internal OpenAI-compatible endpoint.
Engineers track production traces with Langfuse and monitor system health with Amazon CloudWatch. The team uses RAGAS for evaluation. Curated datasets with expert answers support regression checks when prompts, models, or workflow logic change. Production query samples help the team inspect faithfulness, answer relevance, and retrieval quality under real use.
Trust comes from citations and visible work
Scientists need to verify claims against source reports. PRINCE exposes intermediate steps, tool calls, retrieved chunks, and source links. Users can inspect the material the system selected before they trust the answer.
The answer includes citations back to report chunks, page numbers, and study identifiers. That matters in a regulated research setting. A plausible answer without traceable evidence creates review burden. A cited answer lets a scientist confirm or reject a claim.
The team also uses named entity recognition to improve metadata quality. Historical migrations left some metadata incomplete or wrong. Engineers built a utility that reads study PDFs and extracts entities such as study IDs, compound names, species, routes, doses, and clinical findings. High-confidence fields can enrich Athena records, while lower-confidence fields go to human review.
Trade-offs: more control adds system cost
PRINCE gains control by splitting work across agents and tools, but that design increases system complexity. Each workflow step adds latency, observability needs, evaluation targets, and failure modes.
Hybrid retrieval requires tuning. The team used metadata filters to cut the search space, semantic search to catch meaning, keyword search to preserve exact terms, and a cross-encoder reranker to select final chunks. That stack gives better recall and precision, but engineers must monitor each stage.
Text-to-SQL gives precision for structured questions, but schema selection and SQL validation matter. Too much schema confuses the model. Too little schema yields wrong joins or missing columns. The team removed an LLM review step after reviewers flagged valid SQL as wrong, which shows a useful lesson: extra model checks can hurt throughput when they lack a clear target.
Agentic workflows need reflection, but reflection can waste calls if engineers give it vague instructions. PRINCE separates process reflection from data reflection. The planner checks whether the workflow path makes sense. The reflection agent checks whether the evidence can answer the question. That split gives each check a concrete job.
The broader lesson
Bayer and Thoughtworks show that enterprise agentic AI depends on data plumbing and workflow control as much as model choice. The system works because engineers constrained context, narrowed tools by domain, persisted state, traced outputs, tested changes, and kept expert review in regulated work.
Teams building similar systems should start with source-of-truth mapping. Decide which tables, reports, indexes, and human roles carry authority for each question type. Then build retrieval and SQL paths around those boundaries. Add citations before users depend on answers. Add evaluation before prompt changes become guesses.
PRINCE gives the field a concrete architecture for agentic RAG in a regulated setting. The models answer questions, but the engineering around them makes the answers usable.
Comments
Please log in or register to join the discussion