
A small GitHub project points to a larger developer habit: turning local Markdown folders into inspectable, portable visual systems instead of another hosted knowledge app.

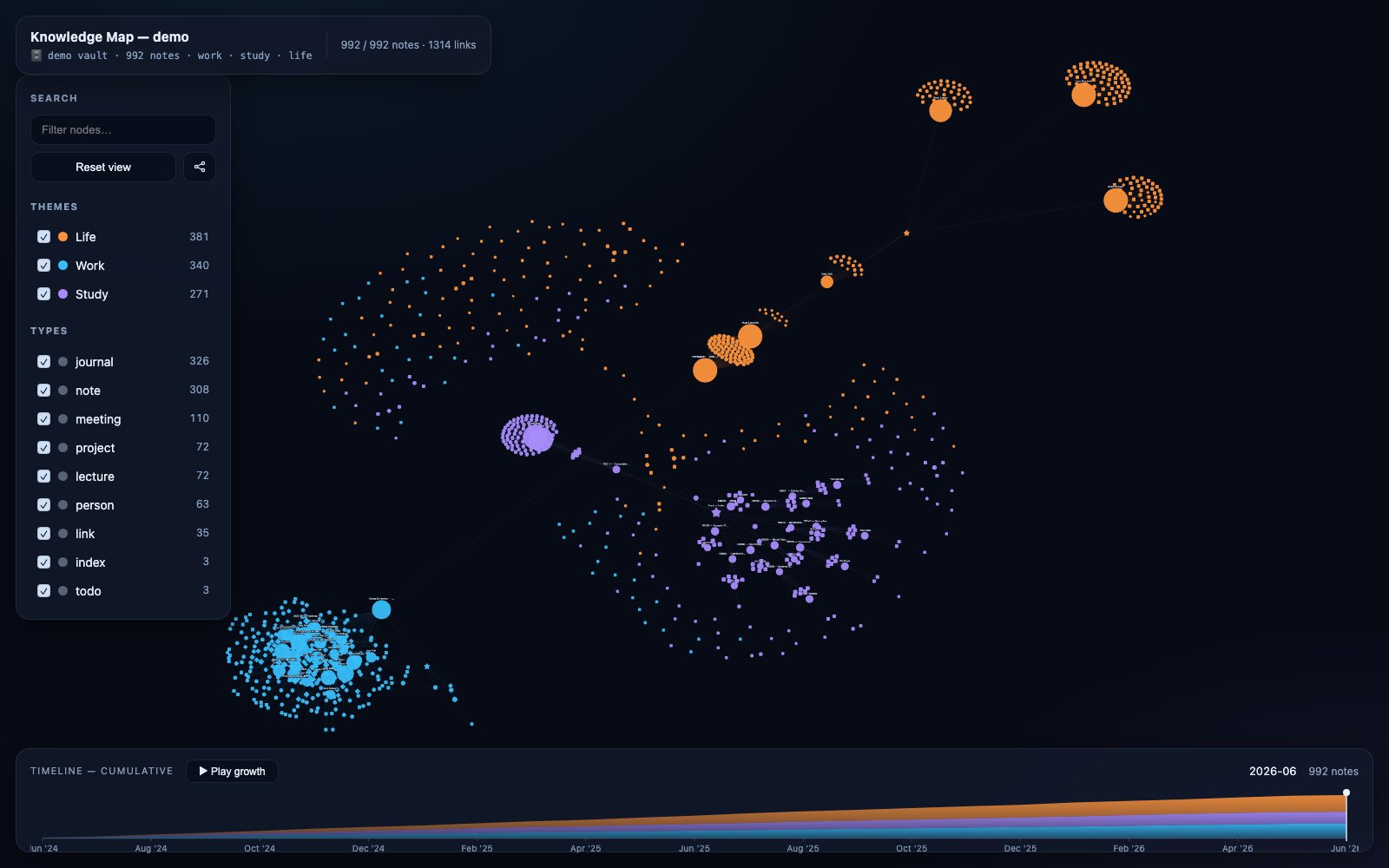
A new developer tool called brain-map-skill is less interesting as a single repository than as a signal. It turns a folder of Markdown notes, including an Obsidian vault or gbrain export, into a self-contained interactive HTML knowledge map. The output includes a force-directed graph, theme coloring, a scrub-able growth timeline, search, filters, and a click-to-inspect side panel.
The project sits in a familiar but increasingly visible pattern: developers want personal knowledge tools that are local-first, scriptable, portable, and easy for coding agents to operate. Instead of asking users to adopt a full database-backed app, brain-map-skill reads plain Markdown, YAML frontmatter, folder structure, tags, and wikilinks. That makes it compatible with habits many technical users already have.
The pitch is direct. Run python3 scripts/build_map.py <notes_dir> out.html --title "My Second Brain", then open the resulting HTML file. No server is required. Embeddings are not required. gbrain is not required. Python dependencies are optional. If NetworkX, NumPy, and SciPy are installed, the builder can precompute a cleaner layout. If not, the browser handles layout using Cytoscape's cose force graph approach, documented in Cytoscape.js.
That restraint matters. A lot of knowledge graph products turn note visualization into a platform decision. This repository treats it as a build artifact.
Trend observation
The developer and agent-tooling community has been circling back to a simple question: if AI assistants can write notes, summarize meetings, maintain project memory, and inspect codebases, what format should that memory live in? Proprietary workspaces are convenient, but they create friction when users want to audit, move, script, or regenerate their data. Markdown remains appealing because it is plain text, git-friendly, and easy for both humans and agents to parse.
brain-map-skill fits that direction. It is packaged not only as a script, but also as an agent skill for Claude Code, OpenAI Codex, Cursor, Gemini CLI, OpenClaw, or any assistant that can follow a SKILL.md instruction file. That framing is the real tell. The tool is not just for a person who wants a pretty map. It is for workflows where an agent may save notes into a predictable folder structure, then generate a visual index of the resulting knowledge base.
The README describes themes as top-level folders such as Work, Study, and Life. Types come from subfolders or tags, producing shapes for people, meetings, journals, lectures, projects, links, todos, index pages, and ordinary notes. Edges come from resolved [[wikilinks]]. Node size scales with link count, which gives hubs more visual weight. The timeline is built from created timestamps and bucketed by month.
That design turns a messy note folder into something closer to an observable system. The tool does not claim to understand your notes semantically. It reads the structure you already gave them. For many developers, that may be more trustworthy than an opaque embedding map, because the graph is based on explicit links and metadata rather than inferred similarity.
Evidence
The strongest adoption signal is the repository's shape. The project ships a prebuilt demo at demo/brain-map.html, so users can inspect the result without installing anything. That reduces evaluation cost. The demo corpus contains 992 fictional notes across work, study, and life themes, which is large enough to show timeline behavior, hubs, filters, and graph density under something closer to real use.
The second signal is the dependency story. The default path uses only the Python standard library. Optional dependencies improve layout quality and startup performance for larger maps, but they are not mandatory. That choice lines up with how many developer tools spread through communities: the first run needs to be cheap, understandable, and reversible.
The third signal is compatibility with existing ecosystems. The README explicitly names Obsidian vaults and gbrain exports as input sources. It also uses Markdown conventions that already exist in personal knowledge management: YAML frontmatter, tags, folders, and wikilinks. Nothing in the core workflow asks users to migrate into a new note format.
There is also a practical agent story. If a companion save-note skill writes notes with predictable frontmatter, tags, dates, and links, brain-map-skill can become the visualization layer. That is a useful division of labor. One skill records structured memory. Another renders it into a navigable artifact. The user can inspect what the assistant has accumulated instead of trusting an invisible memory store.
This is where the project touches a broader tension in AI tooling. Developers want agents that remember context, but they also want inspectability. A local HTML graph is not as magical as vector search, but it is easier to audit. You can see which notes exist, which topics are overrepresented, which nodes became hubs, and where links are missing. The timeline adds another dimension by showing how the base grew over time rather than flattening it into a static pile.
The repository also avoids a common trap in personal knowledge tools: making the graph the product. Graph views can be seductive but noisy. brain-map-skill adds filters, search, live counts, timeline scrubbing, node details, and neighborhood highlighting. Those features matter because a force graph without controls often becomes a decorative tangle. The project appears to understand that useful visualization requires reduction, not just more nodes.
Why it matters
For individual developers, the appeal is straightforward. A Markdown vault can outgrow folder browsing. Search finds exact terms, but it does not always show structure. Backlinks help, but they are usually local to one note. A generated map gives a different view: clusters, hubs, orphans, time periods, and cross-theme links.
For teams, the idea is more speculative but still relevant. Many internal knowledge bases fail because they become either too rigid or too unstructured. A script that reads ordinary Markdown and produces a visual artifact could sit inside documentation workflows, onboarding packs, research notes, or project retrospectives. Because the output is static HTML, it can be shared without running a service.
For AI-assisted development, the project points at a more durable pattern: agent outputs should be legible artifacts. A coding agent can modify source files, but it can also maintain project notes, decision logs, architecture records, meeting summaries, and research trails. If those notes are saved as plain files and visualized by a deterministic tool, the human retains a clearer path to review.
The technical trade-off is also instructive. brain-map-skill does not need semantic embeddings to be useful. That does not make embeddings bad. It suggests there is still a lot of value in explicit structure. Wikilinks, tags, timestamps, and folder names are boring in the best way. They are predictable. They can be edited by hand. They can be reviewed in git. They fail visibly.
Counter-perspectives
The main counter-argument is that graph views often overpromise. A beautiful knowledge map does not guarantee better thinking. If notes are poorly linked, inconsistently tagged, or dumped into folders without care, the graph will reflect that mess. The README says richer cross-linking makes the map more legible, which is both honest and a warning. The tool rewards disciplined note habits.
Another concern is scale. The demo has 992 notes, and optional precomputed layout helps large maps open quickly. Still, force-directed graphs can become difficult to read as node counts rise. Filtering by theme and type helps, but a large knowledge base may need stronger clustering, saved views, or query-driven subgraphs. A single all-notes visualization can become less useful as the archive grows.
There is also a question about meaning. Because edges come from explicit wikilinks, the graph shows declared relationships, not necessarily conceptual similarity. That is a feature for auditability, but it can miss hidden connections. Embedding-based systems can surface related notes that were never manually linked. The ideal tool may combine both approaches: explicit links for trust, semantic suggestions for discovery, and a clear way to distinguish the two.
Some users may also resist the skill framing. Agent skills are useful for repeatable workflows, but they can make simple scripts feel tied to specific assistant ecosystems. brain-map-skill partly avoids that by keeping the script runnable on its own. The agent integration is additive rather than required, which is the right balance for a developer audience that does not want every utility trapped inside a chat interface.
The strongest reading of brain-map-skill is not that it solves personal knowledge management. It does something narrower and more useful: it turns an existing Markdown folder into an inspectable artifact with low setup cost. That restraint is why the project is worth watching. The current wave of AI tooling has created pressure for memory systems, but the community is still deciding what kind of memory deserves trust. Plain files plus generated views remain a serious answer.
Comments
Please log in or register to join the discussion