Uber Engineering has transformed its MySQL infrastructure by replacing external failover mechanisms with MySQL Group Replication, reducing cluster downtime from minutes to under 10 seconds while maintaining strong consistency across thousands of clusters.
Uber Engineering has fundamentally redesigned its MySQL infrastructure to dramatically improve cluster uptime, replacing external failover mechanisms with MySQL Group Replication (MGR) to reduce failover times from minutes to seconds while maintaining strong consistency across thousands of clusters.
The Problem with Traditional MySQL Failover
Previously, Uber operated MySQL clusters using a single-primary, asynchronous replica model. In this architecture, external systems were responsible for detecting failures and promoting replicas to primary status. This approach created several challenges:
- Extended downtime: Failover times measured in minutes due to detection and promotion delays
- Manual intervention: Required human oversight for complex failover scenarios
- Inconsistent states: Risk of data inconsistencies during the promotion process
- Limited scalability: Difficulty managing thousands of clusters with varying workloads
The traditional model worked for smaller deployments but became increasingly problematic as Uber scaled its operations to handle millions of transactions across its global platform.
The Consensus-Based Solution
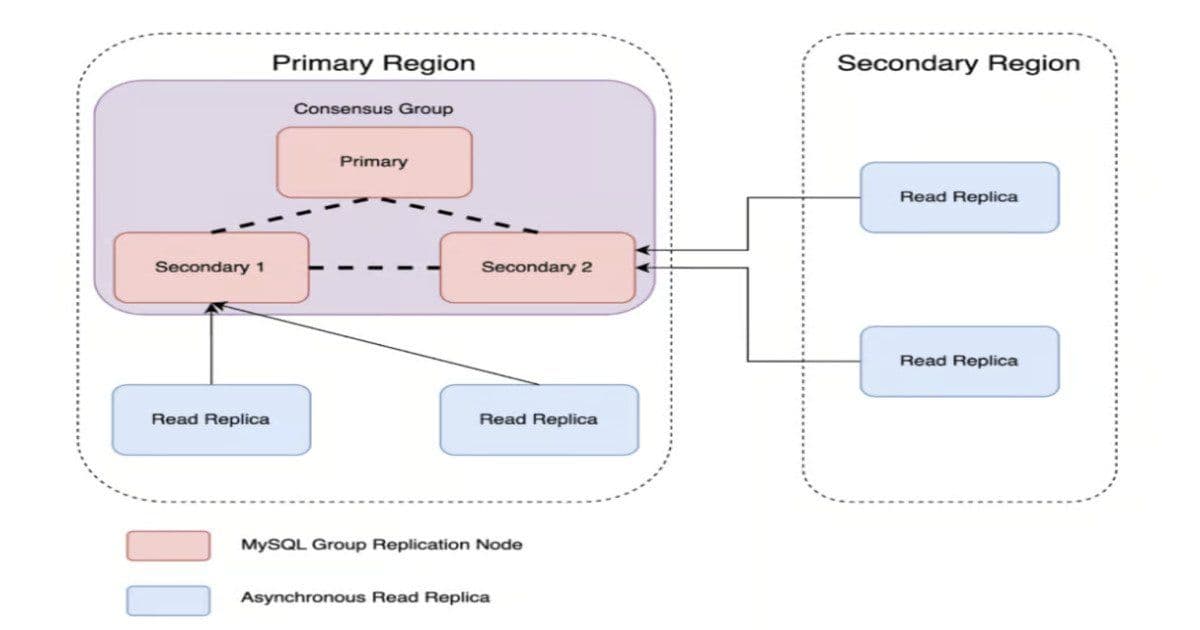
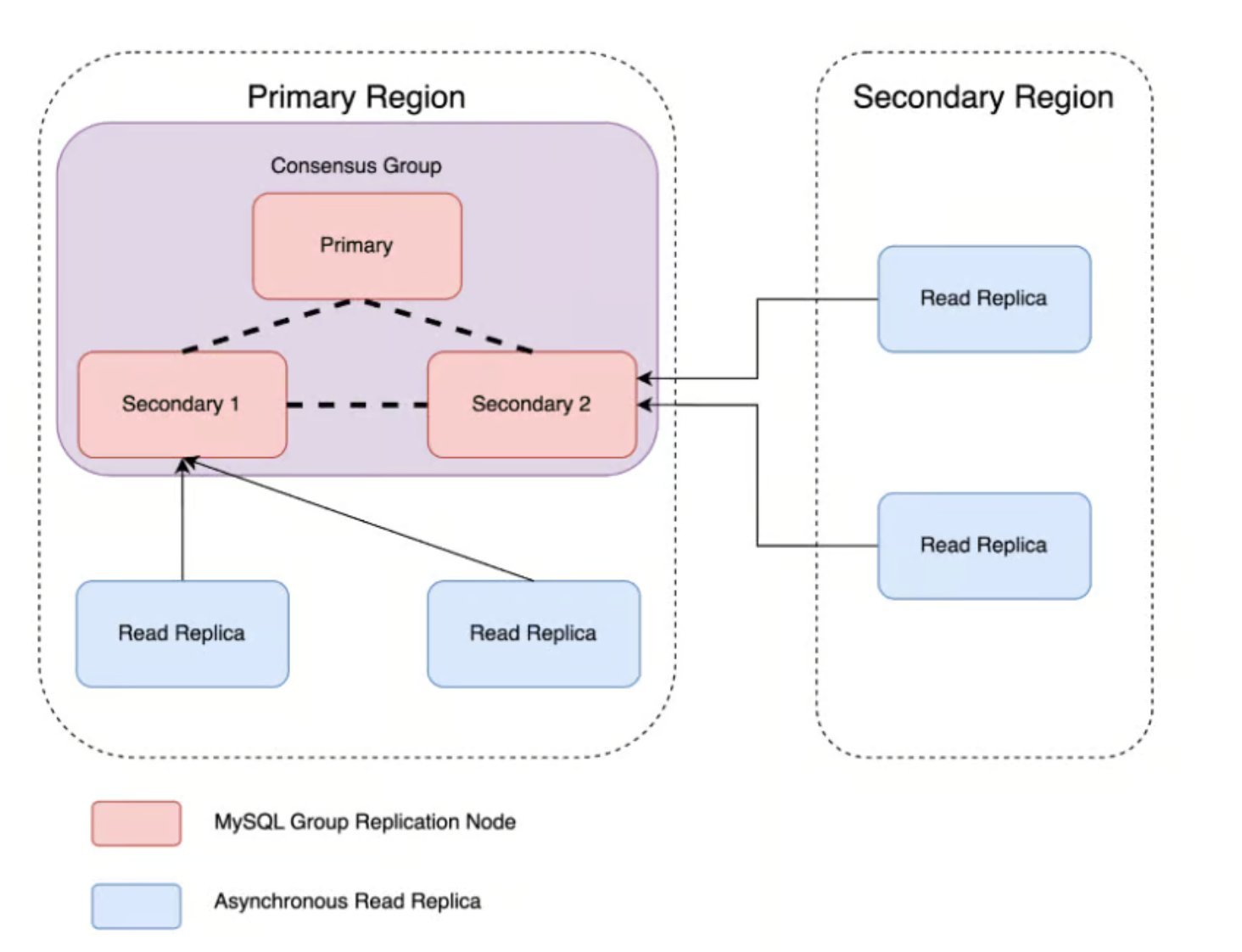
To address these limitations, Uber adopted MySQL Group Replication, a Paxos-based consensus protocol that embeds consensus directly within the database layer. The new architecture forms a three-node MGR cluster where:
- One node serves as the primary for write operations
- Two secondary nodes participate in consensus without accepting direct writes
- All nodes maintain synchronized data through the consensus protocol
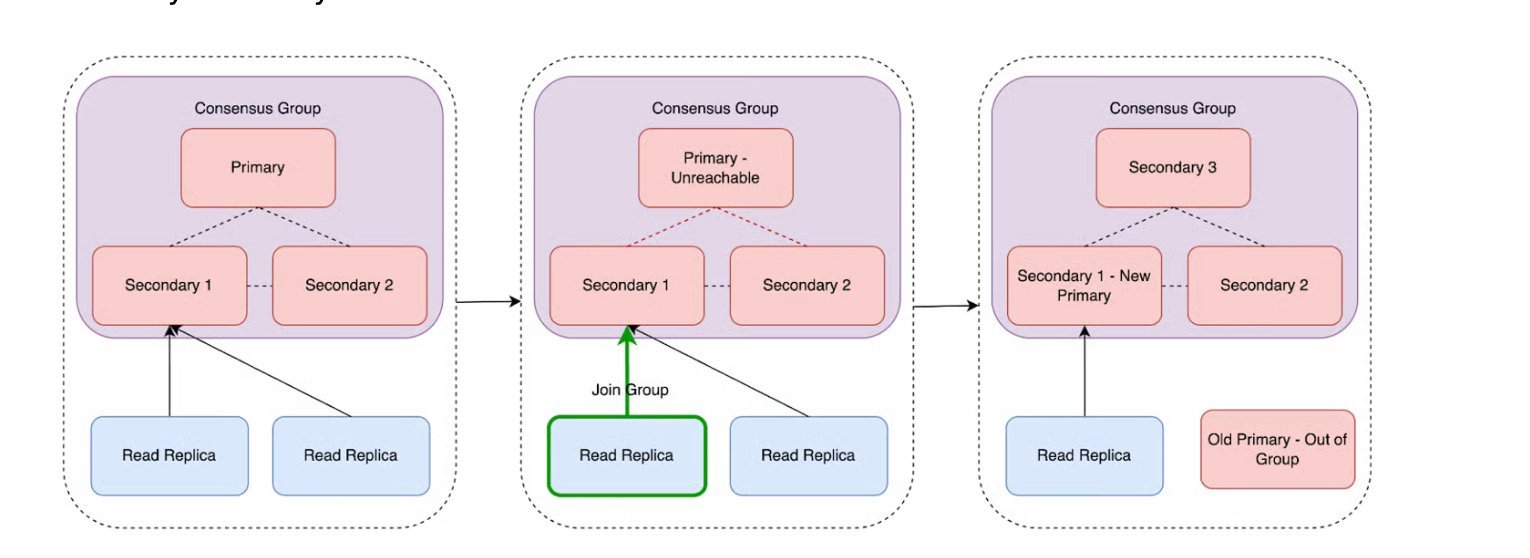
- Automatic primary election occurs when failures are detected
This design ensures that all nodes have up-to-date data and can seamlessly take over as primary when needed, eliminating the need for external failover systems.
Key Architectural Components
Flow Control for Replication Consistency
A critical innovation in Uber's implementation is the flow control mechanism within MGR. This system monitors transaction queues on each secondary node and signals the primary to pause or throttle writes as needed. This prevents nodes from falling behind and maintains replication consistency.
The flow control mechanism provides several benefits:
- Prevents replication inconsistencies during high-load periods
- Reduces write downtime during failover scenarios
- Avoids errant GTID (Global Transaction Identifier) propagation outside the cluster
- Maintains data integrity across all nodes
Scalable Read Replica Architecture
To separate read scaling from write availability while preserving fault tolerance, Uber implemented a fan-out architecture where scalable read replicas branch from the secondary nodes. This approach:
- Maintains strong consistency for read operations
- Allows independent scaling of read capacity
- Preserves fault tolerance through the consensus layer
- Reduces load on the primary node
Automated Control Plane
Uber scaled the consensus architecture using an automated control plane that handles:
- Cluster onboarding and offboarding
- Node management and rebalancing during topology changes
- Graceful and ungraceful node replacements
- Configuration management for consensus parameters
The control plane ensures that the complex consensus operations remain manageable at scale while maintaining high availability and consistency guarantees.
Performance Trade-offs and Benefits
Write Latency Impact
Benchmarking revealed a slight increase in write latency of hundreds of microseconds compared to asynchronous replication. While this represents a measurable performance cost, Uber determined that the benefits of improved availability and consistency outweighed this minor latency increase.
Failover Time Reduction
The most dramatic improvement came in failover time reduction. Total write unavailability during primary failures dropped from minutes to under 10 seconds, including:
- Primary election time
- Routing updates
- Consensus protocol completion
This represents a 10-100x improvement in availability for write operations during failure scenarios.
Read Performance
Read latencies remained consistent with the legacy model since local replica performance matched the previous architecture. This means applications experience no degradation in read performance while gaining significant improvements in write availability.
Operational Safeguards and Configuration
Split-Brain Prevention
Uber implemented several safeguards to prevent split-brain scenarios:
- group_replication_unreachable_majority_timeout: Configuration parameter that helps detect and handle network partitions
- Single-leader mode: Selected over multi-primary for simplicity and operational predictability
- Careful bootstrap handling: Meticulous management of group_replication_bootstrap_group to prevent split-brain scenarios
Dynamic Topology Management
The automated system includes dynamic topology health analysis that:
- Adds new nodes when a group drops below quorum
- Removes excess nodes to reduce overhead
- Repoints downstream replicas during node deletion
- Optionally blocks backlog application to maintain strict external consistency
Implementation Insights and Lessons Learned
Performance Schema Monitoring
Uber engineers discovered that monitoring MGR plugin performance through performance_schema.memory/group_replication was essential for understanding and optimizing cluster behavior. This visibility into memory usage and replication performance helped identify bottlenecks and optimize configurations.
Multi-Primary vs Single-Primary Trade-offs
The decision to use single-primary mode over multi-primary was driven by several factors:
- Simplicity: Easier to reason about and debug
- Operational predictability: More predictable behavior during failures
- Reduced conflict potential: Eliminates write conflicts between primaries
- Simplified conflict resolution: No need for complex conflict resolution mechanisms
Multi-primary mode, while offering potential performance benefits, introduces higher conflict potential and requires robust conflict resolution for transactional ordering, making it less suitable for Uber's use case.
Scaling to Thousands of Clusters
The consensus-based architecture has been successfully deployed across thousands of MySQL clusters at Uber. The combination of:
- Consensus-based replication for strong consistency
- Automated workflows for operational efficiency
- Scalable read replicas for performance
- Comprehensive safeguards for reliability
enables high availability, strong consistency, and reduced manual intervention at massive scale.
Industry Context and Related Developments
Uber's implementation of MySQL Group Replication represents a significant advancement in distributed database architecture for large-scale operations. Similar challenges are being addressed across the industry:
- Netflix has automated RDS PostgreSQL to Aurora PostgreSQL migrations across 400 production clusters
- Pinterest reduced database latency from 24 hours to 15 minutes using CDC-powered ingestion
- OpenAI scales single primary PostgreSQL instances to millions of queries per second for ChatGPT
These developments highlight the industry-wide focus on improving database availability, consistency, and scalability for modern applications.
Conclusion
Uber's transition from external failover to consensus-based MySQL replication demonstrates how fundamental architectural changes can dramatically improve system reliability. By embedding consensus within the database layer and automating operational workflows, Uber has achieved:
- Failover time reduction from minutes to seconds
- Maintained strong consistency across thousands of clusters
- Scalable read performance without compromising write availability
- Reduced manual intervention and operational complexity
The success of this implementation provides a blueprint for other organizations facing similar challenges with distributed database systems at scale.
The post From Minutes to Seconds: Uber Boosts MySQL Cluster Uptime with Consensus Architecture appeared first on InfoQ.
Comments
Please log in or register to join the discussion