
GitHub has fundamentally redesigned the search architecture in Enterprise Server, moving from clustered Elasticsearch deployments to Cross Cluster Replication (CCR) to improve reliability and simplify administration in high-availability environments.
Search functionality serves as the backbone of the GitHub platform, powering everything from the obvious search bars and filtering experiences to core features like the releases page, projects page, and issue counts. Given this critical role, GitHub has invested significant resources over the past year to enhance the durability of its search capabilities in Enterprise Server deployments.
The Challenge with Previous Architectures
For GitHub Enterprise Server administrators managing High Availability (HA) setups, search indexes have long presented maintenance challenges. These specialized database tables optimized for searching required careful attention during maintenance and upgrade processes. When administrators didn't follow procedures in precisely the right order, search indexes could become damaged or locked, causing complications during upgrades.
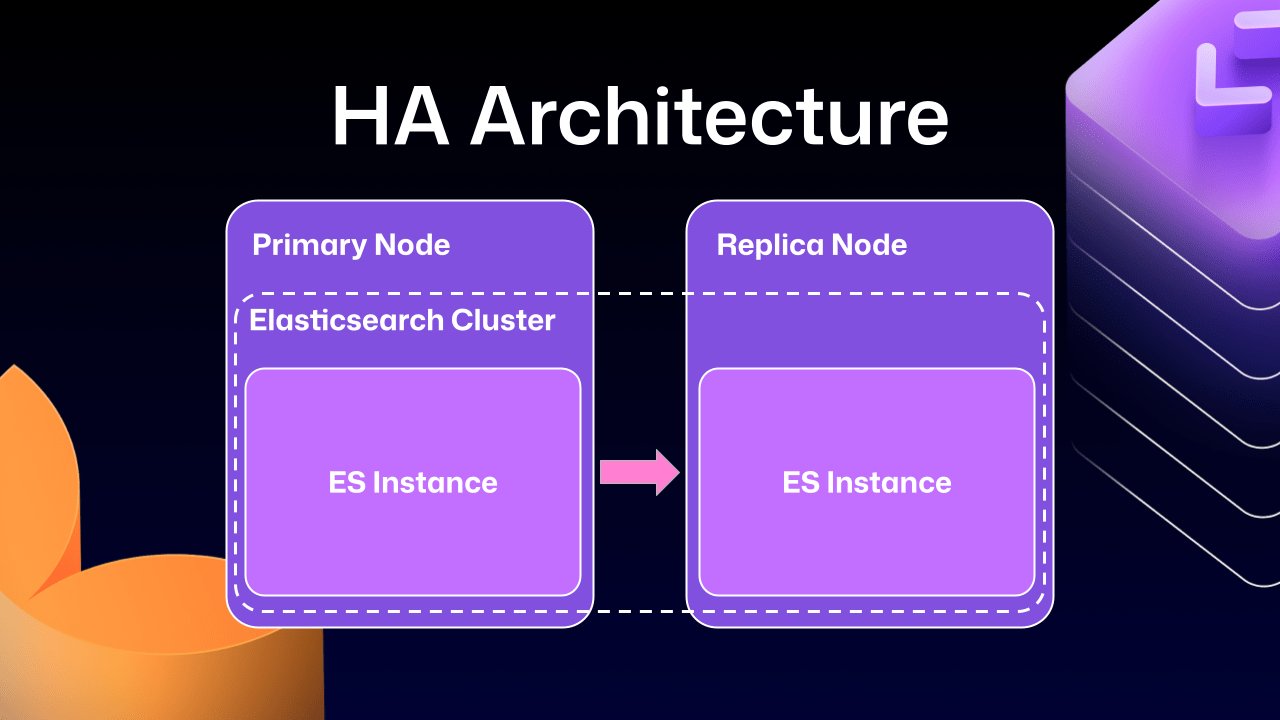
In HA configurations, GitHub Enterprise Server traditionally employs a leader/follower pattern where the primary node handles all writes and traffic while replica nodes maintain synchronization and can take over during failures. The previous implementation integrated Elasticsearch across both primary and replica nodes as a single cluster, which created several operational complications.
This approach, while initially straightforward for data replication and offering performance benefits by allowing each node to handle search requests locally, eventually introduced more problems than it solved. A critical issue was Elasticsearch's tendency to move primary shards (responsible for receiving and validating writes) to replica nodes. When such a replica node was taken offline for maintenance, GitHub Enterprise Server could become locked in a problematic state—the replica would wait for Elasticsearch to become healthy before starting, but Elasticsearch couldn't achieve health status until the replica rejoined the cluster.
GitHub engineers attempted to address these stability concerns through multiple approaches. They implemented health checks for Elasticsearch and processes to correct drifting states, and even developed a "search mirroring" system to transition away from clustered mode. However, database replication proved exceptionally challenging, requiring consistency that was difficult to maintain.
The Architectural Shift to Cross Cluster Replication
After years of development, GitHub has now implemented Elasticsearch's Cross Cluster Replication (CCR) feature to support HA deployments more effectively.
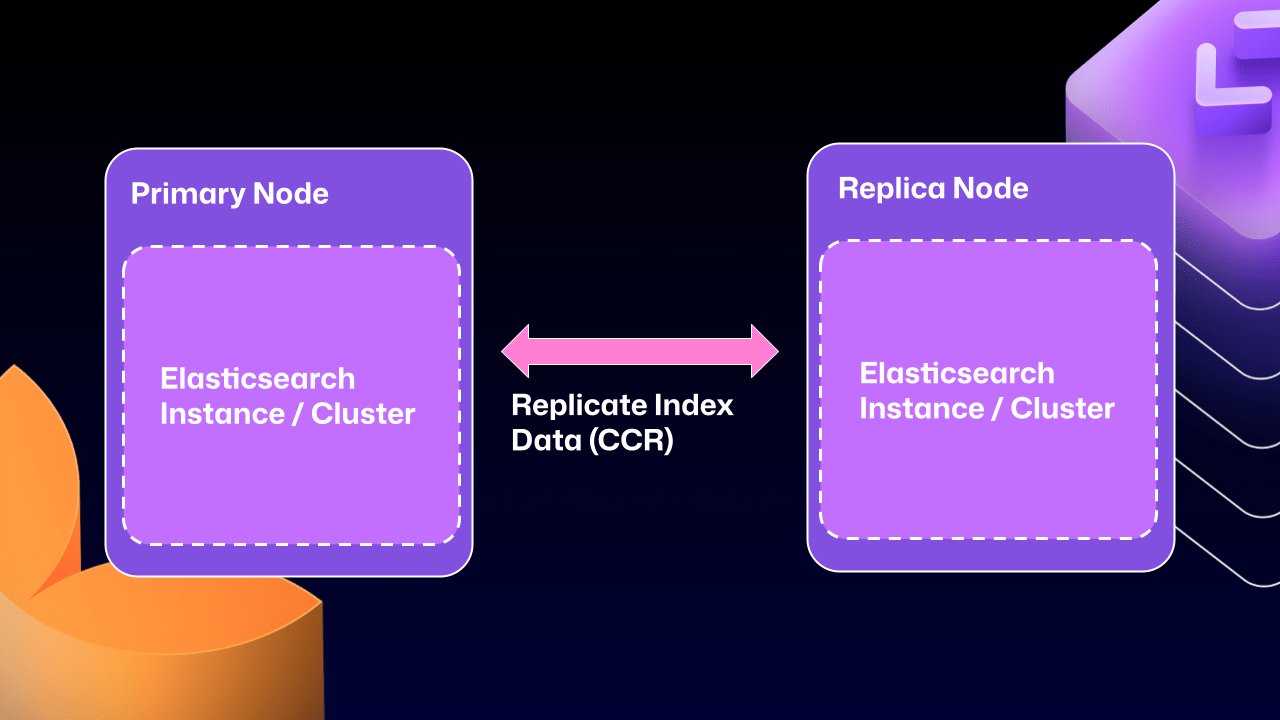
This architectural shift moves from a single Elasticsearch cluster spanning multiple nodes to several independent single-node Elasticsearch clusters. CCR enables controlled, native data sharing between these clusters, copying data only after it has been durably persisted to Lucene segments—Elasticsearch's underlying data store. This approach ensures that critical data no longer resides on read-only nodes, addressing a fundamental limitation of the previous architecture.
The implementation required careful engineering of custom workflows beyond Elasticsearch's native capabilities. While Elasticsearch provides an auto-follow API for indexes created after a policy exists, GitHub Enterprise Server HA installations contain long-lived indexes that needed a bootstrap process. This process attaches followers to existing indexes before enabling auto-follow for future indexes.
The bootstrap workflow involves several key steps:
- Fetching current indexes on both primary and replica clusters
- Filtering out system-managed indexes
- For each managed index without a follower pattern, initializing that relationship
- Ensuring existing indexes follow their primary counterparts
- Setting up auto-follow policies for newly created indexes
GitHub engineers have also developed custom workflows for failover, index deletion, and upgrades, as Elasticsearch only handles document replication while GitHub manages the rest of the index lifecycle.
Implementation and Migration Path
Organizations interested in adopting the new CCR-based HA mode must contact GitHub support to obtain the required license. Once obtained, administrators need to set ghe-config app.elasticsearch.ccr true and apply the configuration or upgrade to version 3.19.1, which first supports this architecture.
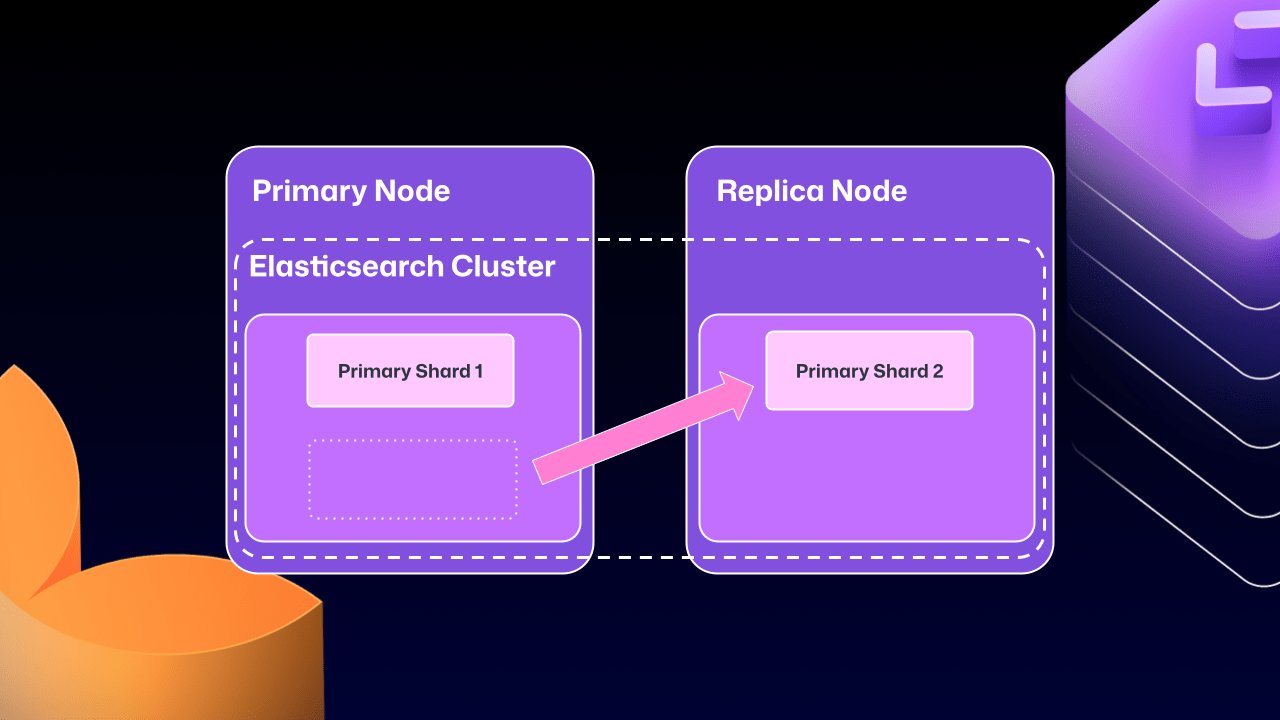
During the migration process, GitHub Enterprise Server restarts Elasticsearch, consolidating all data onto primary nodes, breaking cross-node clustering, and initiating replication using CCR. The duration of this update varies based on the size of the GitHub Enterprise Server instance.
While currently optional, GitHub plans to make CCR mode the default approach over the next two years, providing administrators ample time to evaluate and provide feedback on the new architecture.
Business Impact and Strategic Considerations
This architectural redesign delivers several significant benefits for organizations running GitHub Enterprise Server in HA configurations:
Reduced Administrative Overhead: The elimination of complex cross-node Elasticsearch clustering simplifies maintenance procedures and reduces the risk of index corruption during upgrades.
Improved Reliability: By ensuring data is only replicated after durable persistence and preventing primary shards from residing on replica nodes, the new architecture reduces the likelihood of service disruptions.
Future-Proof Foundation: The adoption of Elasticsearch's native CCR feature positions GitHub Enterprise Server for future enhancements and simplifies compatibility with upcoming Elasticsearch versions.
Operational Simplicity: The separation of concerns between Elasticsearch's document replication and GitHub's index lifecycle management creates a more maintainable system.
For organizations evaluating enterprise code collaboration platforms, this improvement strengthens GitHub Enterprise Server's position by addressing a historical pain point in HA deployments. The approach demonstrates GitHub's commitment to maintaining feature parity between cloud and on-premises offerings while leveraging open source capabilities to solve complex operational challenges.
Administrators considering multi-cloud or hybrid strategies should note that this architecture enhancement specifically benefits on-premises deployments, potentially narrowing the operational gap between cloud and self-hosted GitHub instances.
For more information about implementing this new architecture, administrators can contact GitHub support or refer to the GitHub Enterprise Server documentation.
Comments
Please log in or register to join the discussion