
MIT researchers built DAAAM, a robot memory framework that lets a mobile robot attach object descriptions to 3D maps and answer plain-language questions about where it last saw something.
MIT researchers have built a robot memory framework that lets a machine record object descriptions with locations and observation times, then retrieve that memory from a plain-language request.
Describe Anything, Anywhere, at Any Moment, or DAAAM, links detailed captions to 3D map regions as a robot explores. Lead author Nicolas Gorlo worked with Lukas Schmid and Luca Carlone, director of the MIT SPARK Laboratory. The team presented the research at the Conference on Computer Vision and Pattern Recognition and posted the paper on arXiv.

Keys make the headline concrete. The engineering target reaches factories and campuses, where a robot must remember the state of a world that changes across a shift. A worker may leave a component in a storage bin at night. A robot assistant needs a memory of the component's appearance and storage bin, plus the time it last saw the part.
A robot can use a floor plan for walls and corridors. With DAAAM, the robot can retain richer details: a red bicycle with a flat tire outside the Stata Center, or a sculpture near a campus building. That difference moves robot memory from geometry toward usable recall.

Researchers in robot perception have pursued two pieces of this problem. Multimodal vision models describe image regions with detail. Mapping systems build 3D representations of spaces such as apartments or campuses. DAAAM connects those lines so a robot can ask for an object by language and recover a location.
Vision models such as the Describe Anything Model can caption a selected image region with context. Robot mapping stacks give a machine the geometry it needs for navigation. DAAAM attaches the caption to the map, so a description stays grounded in a place.
DAAAM starts during exploration. A mobile robot collects images and builds a 3D map. The system groups nearby objects into regions. It selects key frames with clear views and sends those frames through a captioning model.
Key frames matter because one good view can cover several objects. Older rich-caption pipelines can spend seconds on a small object set, and a robot that sees hundreds of objects can fall behind its camera stream. The MIT team says DAAAM annotates each object once and reaches a 10-fold speedup for online processing.
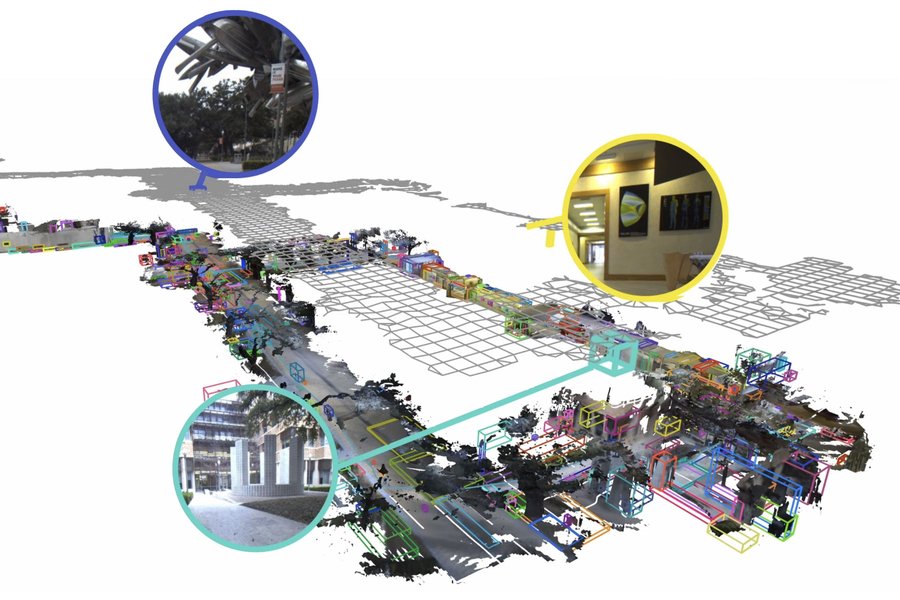
The researchers store descriptions inside a map-based representation organized by region. A user can ask about a sculpture near a building. The robot can search for the term "sculpture." It can then filter by building location and return the stored observation.
The large language model calls retrieval tools against the stored map. Those tools narrow the search by semantics or location. Tool calls reduce hallucination risk because the model queries stored observations rather than inventing an answer from prompt context.
The team reported DAAAM answered benchmark questions with 21% to 53% higher accuracy than top comparison methods, depending on question type. The arXiv paper also reports gains on OC-NaVQA and SG3D, two benchmarks that test long-horizon visual question answering and task grounding.
Real-time memory lets a person give a robot commands that match normal workplace speech. A factory worker could ask for the component from last night. A maintenance crew could ask an augmented-reality system to find equipment that looked abnormal during a prior inspection. A campus robot could guide a visitor back to an artwork or misplaced bag.
The same approach could help autonomous vehicles and service robots handle open-ended scenes. A delivery robot may need to remember a blocked entrance from an earlier trip. A home robot may need to recall that a mug sat on the desk before someone moved it. DAAAM gives the robot a structure for those memories without forcing the user to name map coordinates.
DAAAM depends on what the robot saw. Occlusion can hide the object. Bad lighting can weaken the caption. If someone moves the keys after the robot leaves, the stored map can mislead the user. A captioning model can assign the wrong color or attach a phrase to the wrong object.
MIT researchers plan to add event capture and confidence estimates. A robot could then say whether it saw an object, inferred its location or lacks support for an answer. Teams that deploy this class of memory robot also need rules for privacy and data retention, since useful recall often means storing rich descriptions of shared spaces.
The U.S. Army Research Laboratory and the Office of Naval Research helped fund the work. MIT said the article describes research performed at MIT and has no Amazon affiliation, though Carlone holds a sabbatical role as an Amazon Scholar.

DAAAM shows a clear direction for robot memory: language alone does not give a robot common sense about space, and maps alone do not give it useful recall. MIT's system brings the two together by tying descriptions to places the robot can revisit.
Comments
Please log in or register to join the discussion