
Wiwynn became one of the first server makers to show a working Nvidia SCADA system, a GPU-controlled storage platform that hands I/O control to RTX Pro 6000 Blackwell GPUs instead of the CPU. With 96 liquid-cooled E3.S drives, it reaches 2.949 PB and a claimed 528 million 4K random read IOPS over PCIe 6.x.
Wiwynn used Computex 2026 to put hardware behind one of Nvidia's more abstract storage ideas. The company demonstrated one of the industry's first SCADA (SCaled Accelerated Data Access) servers, a class of machine that pushes storage I/O control off the CPU and onto the GPU. The headline figures are large: up to 96 liquid-cooled E3.S solid-state drives, a maximum of 2.949 petabytes of usable capacity, and a claimed aggregate random read rate of 528 million 4K IOPS. Those numbers matter less as bragging rights than as evidence that Nvidia's Storage Next roadmap has reached shipping silicon.

What SCADA actually changes
The problem SCADA targets is structural. Modern inference and training jobs routinely work with datasets that dwarf the on-package memory of any accelerator. An RTX Pro 6000 or an H-class part has tens of gigabytes of HBM or GDDR, while the working set for vector search, retrieval-augmented generation, graph analytics, or KV-cache retrieval can run into terabytes. The GPU has to reach out to storage constantly, and the access pattern is unfriendly: fine-grained random reads, frequently smaller than 4KB, issued by thousands of GPU threads in parallel.
Traditional I/O paths choke on that pattern. In a CPU-centric design, the host processor issues every command, manages every request queue, and supervises every transfer. Even GPUDirect Storage, which already lets data move directly from an SSD into GPU memory without a bounce through system DRAM, keeps the CPU on the control path. The data path is short, but the GPU still has to ask the CPU to set up each operation. At millions of tiny requests per second, that handshake becomes the bottleneck.
SCADA removes the CPU from the control path entirely. The GPU initiates and controls the storage operations itself, deciding what to fetch and managing the data movement. Nvidia previewed the architecture in late 2025 and has since opened it up so customers can assemble their own systems from commercially available PCIe 6.x components. Broadcom supplies switching and Micron supplies the drives. What had been a reference concept is now something an OEM like Wiwynn can build and put on a show floor.
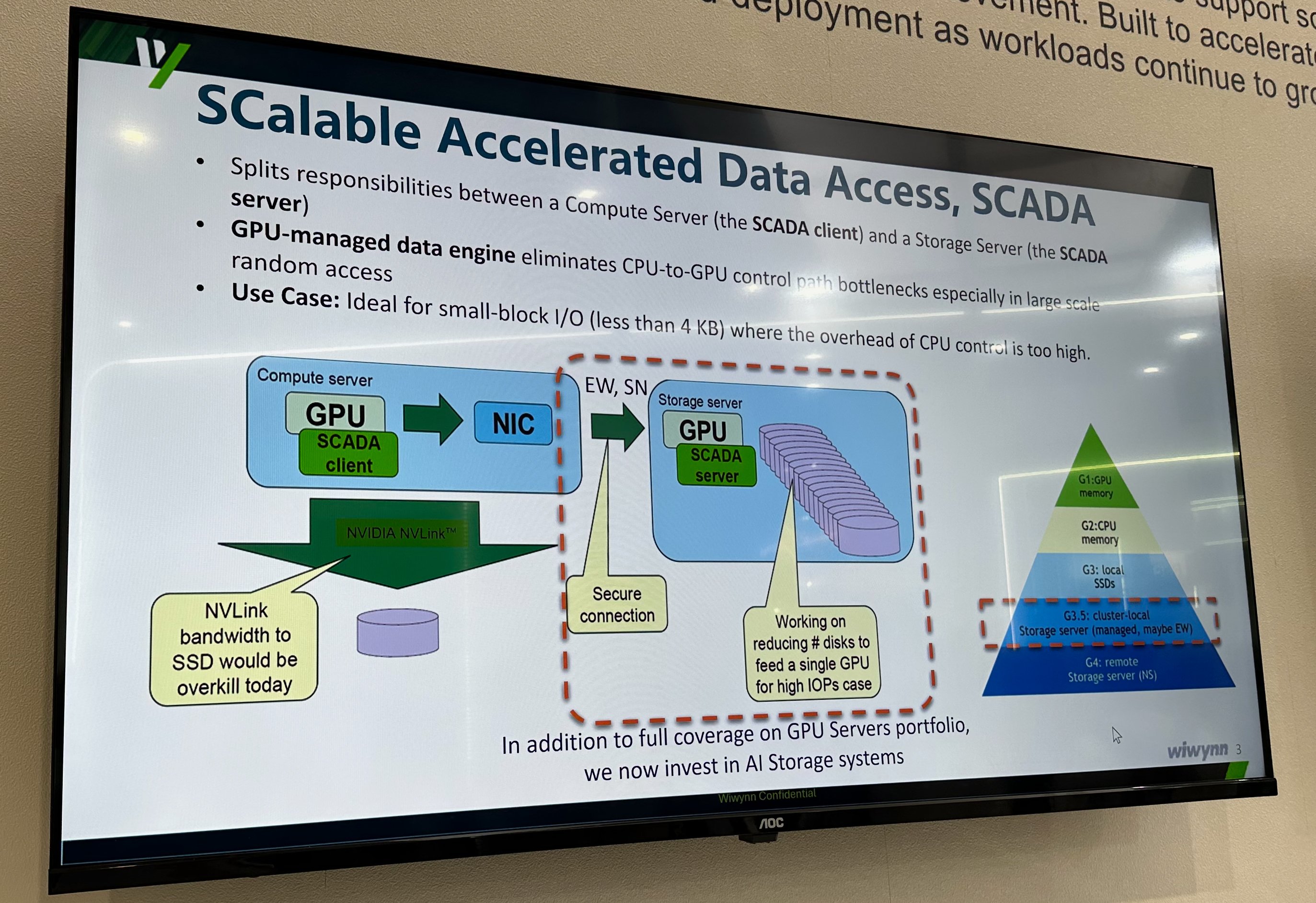
Inside Wiwynn's build
The demonstration system is an Nvidia MGX rack-compliant chassis in a 6RU form factor, drawing up to 9 kW. It is built around Nvidia's Vera CPU, four RTX Pro 6000 Blackwell GPUs, four PCIe 6.x switches, and four ConnectX-9 SuperNICs. The GPUs here are not doing conventional compute. They function as storage processors, fielding millions of small requests on behalf of remote compute nodes, then shipping results out through the ConnectX-9 cards. The SSDs and their controllers still handle the actual reads and writes; the GPU orchestrates the traffic.
Filled with 96 Micron 9650 Pro drives at 30.72 TB each over a PCIe 6.0 interface, the box reaches 2.949 PB. The 528 million 4K IOPS figure is an aggregate random read number across all drives, and Wiwynn notes that sequential throughput is gated by the PCIe switches and network cards rather than the NAND. That detail is the interesting part for anyone sizing a deployment: the drives are no longer the limiting factor, so capacity and performance both scale as E3.S SSDs improve.
Thermals get serious attention. Every major component is liquid cooled, and the 96 drives are served by six separate cold plate modules tied into the system loop, injecting coolant to all SSDs simultaneously. The goal is consistent performance under sustained load rather than the throttling that air-cooled dense flash arrays tend to suffer.

Where it sits in the hierarchy
Nvidia frames SCADA as a tier 3.5 layer. It lives behind the local SSDs attached directly to compute servers but ahead of tier 4 remote storage, which still leans on hard drives. The job is to feed compute nodes at very high transfer rates in small blocks, acting as a fast intermediary that turns a large flash pool into something close to an extension of GPU memory. That positioning is the whole point of Nvidia's broader Storage Next effort, which aims to make storage behave less like a separate subsystem and more like addressable memory for AI workloads.
Adoption is early. Wiwynn appears to be among the first vendors to even showcase a SCADA server, and the category has not yet spread. Pricing is undisclosed, which is unsurprising given that the bill of materials swings with 3D NAND, DRAM, and SSD pricing, plus purchase volume. A Vera-based system with four Blackwell-generation RTX Pro 6000 GPUs and nearly 3 PB of high-end flash will not be inexpensive under any configuration.
The significance is less about this single machine and more about the architectural shift it represents. For two decades the storage stack has assumed a CPU sits in the middle, brokering access. SCADA challenges that assumption for a specific, increasingly common workload, and the fact that an OEM can now buy the parts and build one suggests the idea is moving from Nvidia's slide decks into data center procurement plans. More detail on the supporting technologies is available through Nvidia's developer resources, and Micron documents the 9650 Pro line used in the demonstration.
Comments
Please log in or register to join the discussion