A backend engineer's account of two internship tasks that converge on the same hard truth: components that pass their own tests can still fail together. One task was finding a single auth model two very different clients could share. The other was hunting the seams where separate code refused to agree.
Most authentication bugs are not really authentication bugs. They are integration bugs wearing an authentication costume. Two pieces of a system each behave correctly in isolation, and the failure only appears when a real request has to travel through both of them. That pattern, the gap between "works alone" and "works together," runs through both of the backend tasks described here, and it is worth pulling apart because the same instinct that solves it shows up everywhere in distributed systems.
The problem: one security model for two clients that authenticate in opposite ways
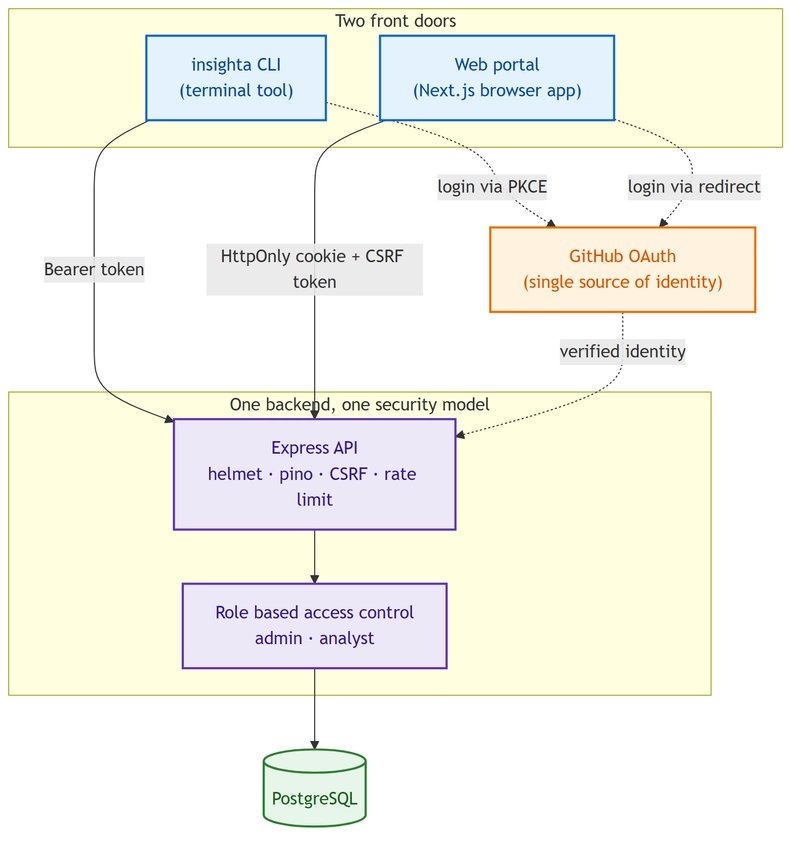
The first task was a backend for an analytics product that had to serve two clients at once. One was a command line tool an analyst installs and runs from a terminal. The other was a web portal they log into from a browser. Same data, same permissions, two entirely different ways of arriving at the door.
The naive framing is "build an API." The real problem is harder: build one security model that two clients with opposite assumptions can both trust. A browser is comfortable with cookies, redirects, and server held sessions. It has somewhere to store state and a URL the server controls. A command line tool has none of that. No cookie jar, no redirect target, no safe place to stash a session. The browser carries context the terminal simply does not have.
When two clients diverge this sharply, you face a fork. You can build two independent auth systems and accept the cost of keeping them consistent forever, which is a consistency problem you will lose eventually. Or you can find the one model underneath that both clients can express, and pay the cost up front in design effort. The second path is almost always correct, because divergent auth systems drift, and drift in security code is how you end up with a CLI that quietly trusts a token the API would have rejected.
The approach: a shared identity source and one verification path
The design used GitHub OAuth as the single source of identity, which removes raw password storage from the product entirely. On top of that sat role based access control with two roles, admin and analyst, so a token could be verified the same way regardless of which client sent it. That last point is the whole game. If the API checks every request through one code path, the question of "which client are you" never leaks into authorization logic. The client is just a transport.
The web portal got the standard browser treatment: HttpOnly cookies, a double submit CSRF token, and everything served from a single origin through rewrites so the cookie rules stayed simple. Keeping the API and the portal on one origin is an underrated decision. Cross origin cookie handling is a reliable source of subtle bugs, and collapsing it to same origin removes a whole category of them. The UI also refreshed its token automatically on a 401 rather than dumping the user back to login, which is the difference between a session model that respects the user and one that punishes them for token expiry they cannot see.
The production hygiene around it was unremarkable in the best way: helmet for headers, pino for structured logging, CSRF protection, rate limiting, and an explicit API version header so clients could not be surprised by a breaking change. None of that is interesting until it is missing.
The trade-off the CLI forced: PKCE instead of stored secrets
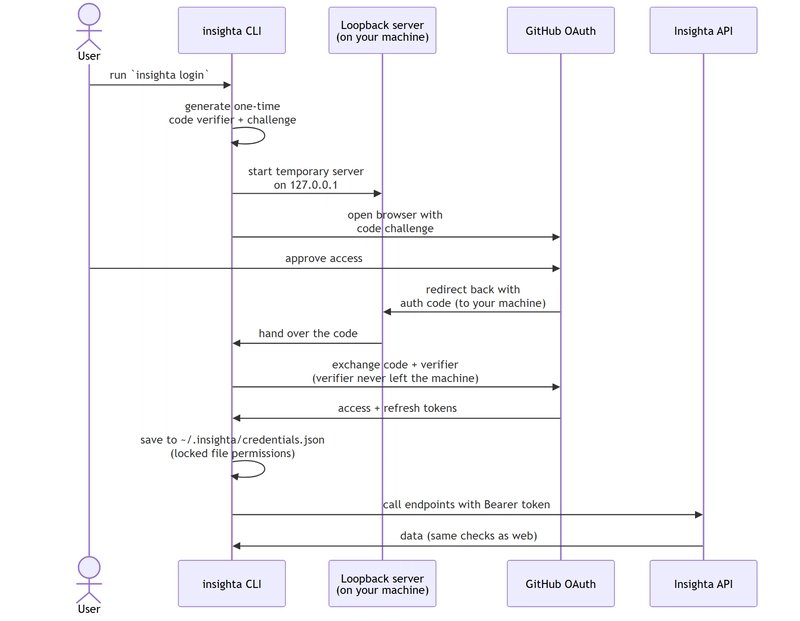
The terminal client is where the design actually got tested. OAuth's authorization code flow assumes a browser. The entire dance redirects a user to a login page and then back to a URL the server controls. A terminal has no such URL. The early attempts tried to bend the web flow onto the CLI and it did not fit. Either login could not complete, or the path of least resistance was to drop a long lived token into a plaintext config file, which is exactly the failure mode you are trying to avoid. A secret sitting in a dotfile is a secret waiting to be committed, logged, or copied.
The answer is the authorization code flow with PKCE, the variant built specifically for clients that cannot keep a secret. The mechanism is clean once you see it. The login command spins up a tiny local web server bound to a loopback address and uses that as the redirect target. The browser opens to GitHub, the user authenticates, and GitHub redirects the authorization code back to the loopback server running on the user's own machine. The CLI then exchanges that code using a one time code verifier that never leaves the computer. Only after that exchange do tokens exist, and they get written to a credentials file in the home directory with locked down permissions so other local users cannot read them.
The trade-off here is honest. PKCE adds moving parts: a local server, a generated verifier, a browser handoff, file permission management. In exchange you eliminate the long lived stored secret entirely. For a public client, a tool whose binary anyone can inspect, that exchange is not optional. A public client cannot hold a confidential secret by definition, so PKCE substitutes a per session secret that proves possession without ever being stored. The cost is complexity in the login command. The benefit is that there is no standing secret to steal.
Once that clicked, both clients spoke the same language. Identity came from one place, the API verified every request identically, and no raw password or long lived secret lived in plaintext anywhere. The API was deployed on AWS App Runner so it had a stable home rather than running on a laptop.
The broader lesson generalizes well beyond this product. Authentication is not one problem. It is a different problem per client type, and the engineering work is finding the shared model underneath that all of them can map onto. Get that right and authorization stays simple. Get it wrong and you maintain N security systems that slowly disagree.
The second problem: bugs that live in the seams
The second task was a team build, a NestJS backend several engineers worked on in a shared repository with direct write access. The ticket covered login, logout, and session management. On paper it is small. Registration, login, and logout each already existed and had each been merged. The actual work was making the full lifecycle usable end to end.
This is the distinction that matters: "each endpoint works on its own" and "the flow works end to end" are different claims, and the distance between them was the entire ticket. The approach started with reading other people's code rather than writing new code. Trace one user from registration, to login, to a protected route, to a token refresh, to logout. Walk the whole path before touching anything.
Two failures hiding in the gaps between people's code
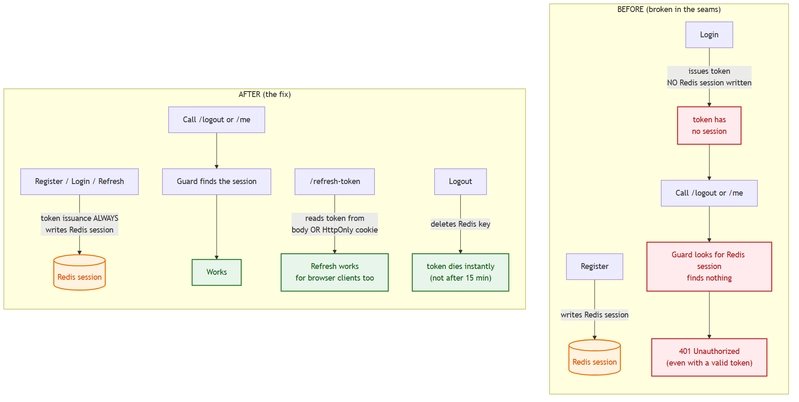
The first broken thing: protected routes required a session record in Redis, but only the registration endpoint wrote that record. Log in normally and your token was valid, yet the moment you hit logout or loaded your profile you got a 401. The login path and the guard had been built by different people, and nobody had walked the path connecting them. Each component was internally correct. The contract between them was never established. The fix was to make token issuance always write the Redis session regardless of whether you arrived through register, login, or refresh, so the guard always had something to find.
The second was subtler and more instructive. Login set the refresh token as an HttpOnly cookie, which is the secure choice precisely because JavaScript cannot read it. But the refresh endpoint only knew how to read the token from the request body, and the login response echoed it nowhere a client could reach. So the secure cookie design and the refresh endpoint were each individually correct and mutually incompatible. There was no path a real browser client could take to actually refresh a token. The fix added cookie parsing on the server, made the refresh endpoint accept the token from either the body or the cookie, and made logout delete the Redis key so an access token died immediately on logout instead of lingering for its full fifteen minute lifetime.
For the lockout feature itself, the schema already carried unused columns: a failed attempts counter and a locked until timestamp. The policy wired up was five failed attempts locking an account for one hour, with a locked account returning a clear 423 status rather than a generic error, and a successful login resetting the counter and stamping the last login time. Every branch got unit tests, which is the right call for lockout logic specifically, because the failure mode is locking out a legitimate user, and you only discover that in production if you did not test it.
What both tasks share
Neither set of bugs was dramatic. They were the kind that only surface when you stop testing one endpoint at a time and start testing the way a real user moves through the system. In a team, the bugs usually are not inside any one person's code. They live in the spaces between, where one engineer's assumptions and another's quietly disagree. Everyone can be individually correct and the product can still be broken.
This is the same shape as the CLI problem from the first task, viewed from the other side. The solo task was about finding one model two clients could share. The team task was about finding the seams where separate pieces failed to agree. Both reduce to a single discipline: do not trust that things work together because they work apart. Walk the whole path yourself.
That instinct maps directly onto distributed systems work, where almost every hard failure is an integration failure. Services pass their own tests. The contract between them is where the incident comes from. The most valuable engineering move in both tasks was not writing code. It was reading carefully across boundaries and tracing the full request before trusting that the boundary held. Strict standards, pre-commit hooks, automated scanners, and reviewers who reject oversized pull requests feel slow in the moment. They are the only reason a shared codebase with many hands in it stays coherent.

The takeaway worth keeping is portable. Components are easy to verify in isolation and that verification tells you almost nothing about whether the system works. The interesting, hard, and genuinely valuable work is making independent pieces trust each other across the seams. You get good at that by reading more than you write, and by refusing to believe a path works until you have walked every step of it yourself.
Comments
Please log in or register to join the discussion