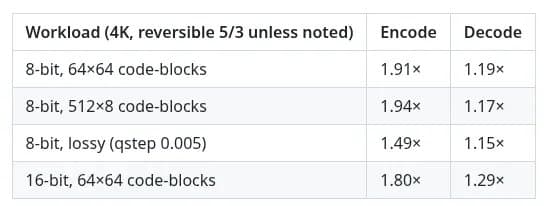
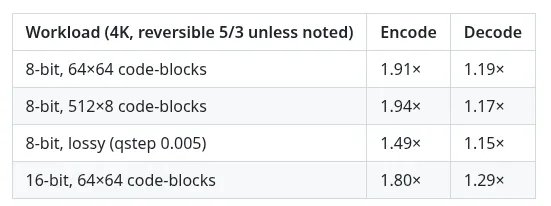
The open-source High-Throughput JPEG2000 implementation OpenJPH just shipped version 0.28 with hand-tuned AVX2 paths for its block coder, pushing encode and decode throughput as high as 1.9x on modern Intel and AMD x86_64 silicon. For anyone running HTJ2K pipelines on commodity homelab hardware, that is free performance with nothing but a recompile.
OpenJPH is one of those projects that quietly sits underneath a lot of imaging work without getting much attention, and the 0.28 release is worth a closer look if you push pixels through High-Throughput JPEG2000. The headline number is up to 1.9x faster encode and decode, delivered entirely through new AVX2 optimizations in the block coder contributed by Prof Osamu Watanabe.
That speedup comes from vectorizing the hottest part of the codec on x86_64 hardware, so there is no new hardware to buy and no exotic accelerator involved. If your CPU shipped in the last decade or so, it almost certainly has AVX2, and you get the gains by rebuilding against the new release.
What HTJ2K Actually Is
High-Throughput JPEG2000, formally JPEG2000 Part-15 (also called HTJ2K or JPH), is a 2019-era amendment to the original JPEG2000 standard. The classic JPEG2000 codec was always praised for its image quality, wavelet-based scalability, and region-of-interest coding, but it carried a reputation for being slow. The arithmetic entropy coder at its core, the so-called Tier-1 block coder, was the bottleneck and it was stubbornly serial.
HTJ2K replaces that entropy coding stage with the FBCOT (Fast Block Coding with Optimized Truncation) algorithm. The practical result is an order-of-magnitude throughput improvement over legacy JPEG2000 while keeping the same wavelet structure, the same scalability features, and bitstream compatibility at the codestream level. You keep the resolution and quality layers, you keep lossless and lossy modes, and you lose the painful encode and decode latency.
That block coder is exactly where AVX2 helps. FBCOT is built around bit-plane operations and magnitude refinement passes that map well onto SIMD lanes once someone does the careful work of restructuring the data flow. Watanabe's contribution does that restructuring for the 256-bit AVX2 registers, processing multiple coefficients per instruction instead of one at a time.
Why AVX2 Is The Right Target
AVX2 has been present on Intel since Haswell in 2013 and on AMD since Excavator and then properly since Zen in 2017. It gives you 256-bit vector registers and, importantly for an entropy coder, integer SIMD operations across those wide lanes. That makes it a sensible baseline for an optimization that needs to run on whatever the user already owns rather than demanding AVX-512, which remains fragmented across consumer parts.
The trade-off with hand-vectorized code paths is always maintenance and correctness. A scalar reference path has to stay in the tree for CPUs without the extension and for validating that the vectorized output is bit-identical. OpenJPH keeps that fallback, so older hardware still works, it just does not get the 1.9x.
{{IMAGE:2}}
Who Benefits
The obvious consumers are anyone moving large, high-bit-depth imagery. HTJ2K has been picking up adoption in digital cinema, medical imaging where JPEG2000 already had a strong foothold via DICOM, remote sensing, and increasingly in streaming and interactive imagery protocols like JPIP. In all of those, encode and decode throughput directly limits how many frames or how many concurrent streams a single box can handle.
For a homelab perspective, the math is straightforward. If you are batch-transcoding an archive or running a tile server that decodes regions on demand, a 1.9x improvement nearly halves your CPU time per image at the top end. On a power-constrained always-on server, that is the difference between a job finishing inside a maintenance window or spilling over, and it is watt-for-watt free efficiency since the silicon was already sitting there with idle vector units.
The realistic expectation is that 1.9x is the best case, not the average. SIMD speedups depend heavily on image characteristics, bit depth, the number of coding passes, and how much of the runtime was actually spent in the block coder versus the wavelet transform and I/O. Quoting the peak is fair for an enthusiast release note, but plan your capacity around measured numbers on your own workload.
Build Recommendations
If you want to try OpenJPH 0.28, grab the release from the GitHub repository and build it with a compiler that emits AVX2 codegen for the relevant translation units. The project uses CMake, so a standard out-of-source build works, and you will want a release configuration with optimizations enabled rather than a debug build, otherwise you give back much of the SIMD advantage to unoptimized scaffolding.
A few practical notes for getting clean numbers:
- Confirm AVX2 is actually present on your target with
grep avx2 /proc/cpuinfobefore assuming the fast path is in play. - Pin your benchmark to a fixed clock or at least account for boost behavior, since a short encode can finish entirely inside a turbo window and overstate steady-state throughput.
- Test with representative images. A synthetic gradient and a noisy photographic frame will exercise the block coder very differently.
- Compare against your existing 0.27 or earlier build on the same machine rather than trusting the headline figure, so you know the real delta for your data.
The full technical detail on the new code lives in the upstream pull request linked from the release, which is the right place to look if you want to understand exactly which passes were vectorized and how the fallback dispatch is handled.
Releases like this are easy to overlook because there is no new feature to demo, just the same codec doing the same job faster. For infrastructure that runs continuously, though, that is precisely the kind of update worth picking up. The performance is real, the hardware requirement is already met by most x86_64 deployments, and the cost of adopting it is a rebuild.
Comments
Please log in or register to join the discussion