
This article explores how Apache Camel serves as a robust orchestration framework for agentic and multimodal AI systems, addressing common production challenges through enterprise integration patterns. It demonstrates a support ticket triage system that combines LLM reasoning, RAG, and image classification while maintaining reliability and observability.
Introduction
As AI adoption accelerates across enterprises, systems are evolving beyond simple model calls into complex multi-step workflows that combine reasoning, retrieval, and action. Agentic AI describes systems where a model acts as a reasoning agent, deciding which tools to use, what information to look up, and in what order to carry out tasks. Multimodal AI adds the ability to work with different input types like text, images, and structured data within the same pipeline.
Both patterns are becoming common in enterprise settings, but they also make engineering significantly more challenging. Most modern AI systems do not fail because the model is weak. Instead, they fail when the system around the model is not properly designed. As more teams implement large language models, vector databases, and vision models, the same problems keep appearing in production: fragile pipelines, unclear failures, high costs, and limited control.
A 2026 Fivetran benchmark of five hundred enterprise leaders found that ninety-seven percent reported pipeline failures slowing their AI programs, with fifty-three percent of engineering capacity spent just maintaining pipelines. MIT's 2025 NANDA report showed that ninety-five percent of generative AI pilots fail to deliver measurable business impact, with flawed enterprise integration, not model quality, identified as the core issue. An S&P Global Market Intelligence survey found that forty-two percent of companies abandoned most of their AI initiatives in 2025, up from seventeen percent in 2024.
The main problem is not the models' intelligence, but how everything is managed together. This article shows how agentic and multimodal AI systems can be engineered as reliable software rather than treated as experiments. We will use Apache Camel as the control system and LangChain4j as the agent runtime.

From Model-Centric AI to System-Centric AI
Most AI tutorials focus on simply calling a model, but real-world production systems need a broader approach that includes efficient management and containment of the model. In enterprise AI workflows, this translates into deciding when to use a large language model, choosing which tools it can access, adding non-LLM models for reliable, rule-based tasks, handling partial failures smoothly to keep things stable, and creating structured outputs that can be audited for compliance and review.
It is at this point where AI pipeline orchestration with an embedding agent becomes especially useful. An agent is more than simply an LLM running in a loop; it acts as a reasoning component that fits into a larger, well-managed execution system. In this setup, proven integration methods from traditional systems continue to help ensure the system remains strong and efficient.
Why Apache Camel Fits Agent-Based AI Workloads
In most traditional agentic AI implementations, the LLM acts as both the reasoning engine and the execution controller. Frameworks like LangChain, CrewAI, and AutoGen let the agent decide which tools to call, manage conversation memory, and sequence actions, all within the agent runtime itself. These frameworks offer basic retry capabilities at the API call level, but they do not natively provide enterprise-grade resilience patterns like circuit breakers, payload validation, or deterministic fallback routing.
This works well for prototypes and single-user applications, but in production environments, it creates challenges. Error handling requires custom code layered into agent logic, making failures harder to trace. There is no clear separation between what the agent decides and how that decision gets executed. While external tools like LangSmith can add observability, it is not built into the execution model itself. Scaling, versioning, and governance become difficult because the control logic lives inside the AI layer.
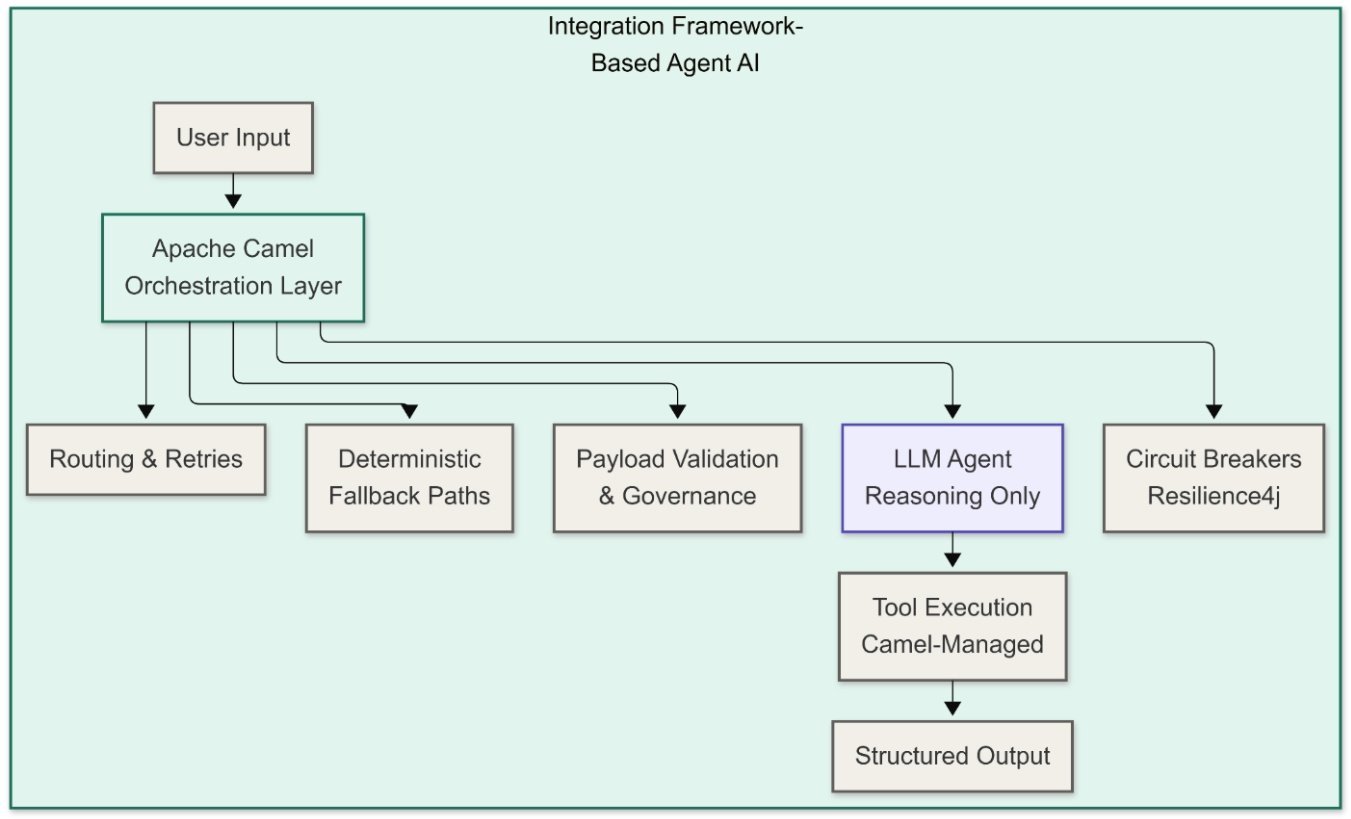
An integration framework-based approach changes this by pulling the execution control out of the agent and into a proven orchestration layer. In this model, the LLM agent still handles reasoning and deciding what to do, but a framework like Apache Camel handles how and when it gets done. Routing, retries, circuit breakers, payload validation, and sequencing are managed by Camel routes, not by the agent. This approach gives engineering teams the same operational control over AI workflows that they already have over traditional enterprise integrations.
Figure 1 below illustrates this difference:
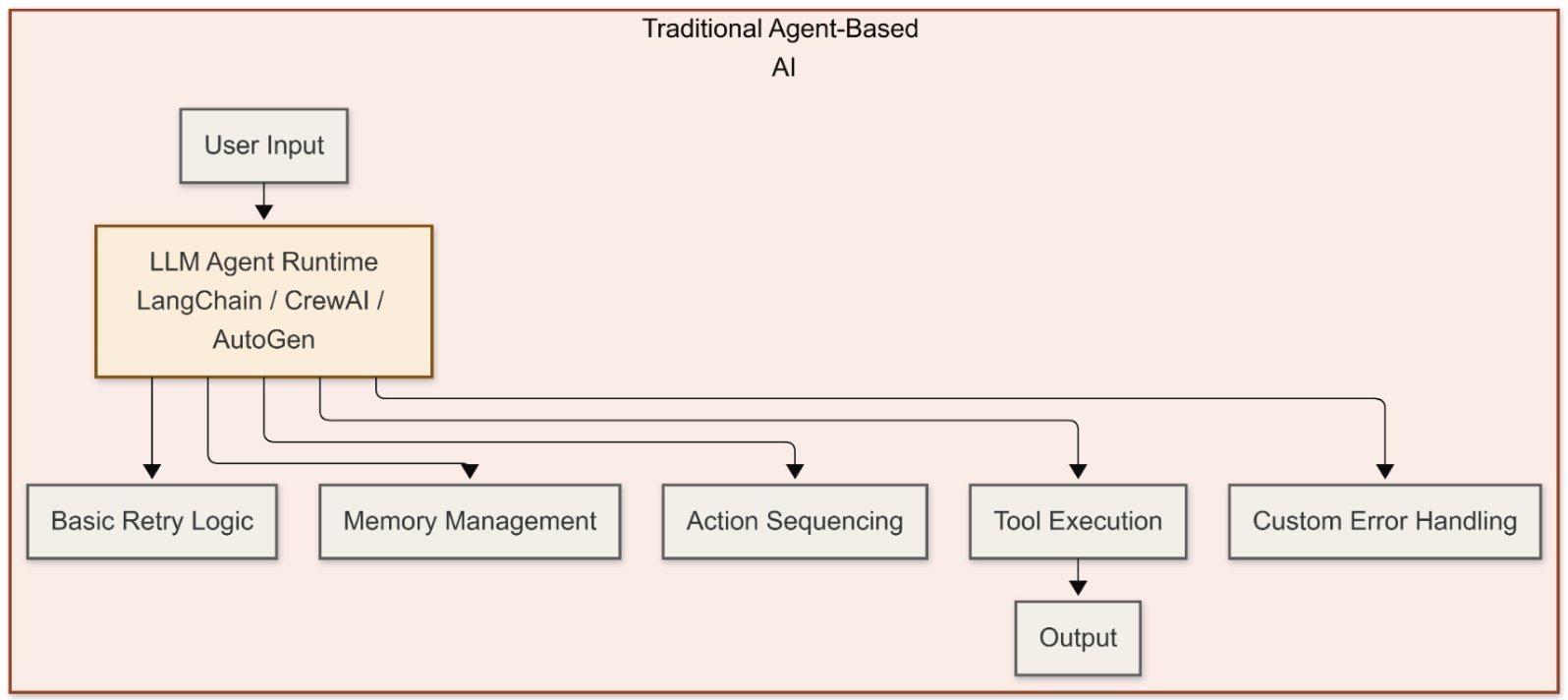
Apache Camel is often seen as an integration framework, but in AI-heavy systems, it takes on a more strategic role as an AI control plane. It offers key features such as clear routing choices, context enrichment, failure isolation with circuit breakers and retries, and deterministic sequencing for steps that are often unpredictable. Camel also clearly separates reasoning and execution tasks. Rather than hiding logic inside prompts or SDK callbacks, Camel moves the control flow into modular routes that are easy to test, monitor, and update. In this setup, the LLM does the reasoning, but Camel makes the final decisions.
However, using Apache Camel for agent-based AI workloads comes with tradeoffs worth acknowledging. Camel is a Java-based framework, which implies that teams working primarily in Python, the dominant language in the AI and ML ecosystem, will face a steeper adoption curve and a narrower selection of AI libraries compared to the wider Python AI tooling landscape. Camel routes are powerful for structured, deterministic workflows, but they are less suited for highly dynamic agent actions where the execution path is not known in advance and needs to emerge from multi-turn LLM reasoning. Debugging Camel routes that wrap AI interactions can also be more complex than debugging a simple Python script that calls an LLM directly.
The Real-World Problem: Support Ticket Triage System
The case study featured in this article revolves around a production-grade customer support ticket triage system designed for real-world deployment. When processing a given ticket, which includes a title and description, optional screenshots, and associated metadata such as the submitter's details and ticket ID, the system is programmed to deliver a structured JSON decision encompassing key elements like the ticket's category, ranging from bugs and incidents to access requests and beyond, along with a priority level scaled from P0 to P3, a recommended team for handling, suggested ensuing actions to advance resolution, citations drawn from internal documentation for reference, and any optional signals derived from image analysis.
Importantly, this setup operates not as a chatbot but as a streamlined, non-conversational process without a user interface, ensuring that outputs remain deterministic, easily consumable by machines, and fully auditable for accountability and oversight.
Architecture Overview: An Agent Inside a Deterministic Pipeline
The support ticket triage system handles a mix of structured and unstructured inputs, text descriptions, metadata fields, and optional screenshot attachments, each calling for different processing strategies. Classifying a ticket into the right category and priority level requires reasoning across these inputs, not just pattern matching on keywords. The text content needs to be matched against internal documentation through retrieval-augmented generation to surface applicable context and citations. Screenshots, when attached, need to be analyzed separately using a vision model to extract signals such as error dialogs or UI failures that inform the triage decision.
A rule-based system alone cannot handle this range of inputs effectively, and sending everything to a single LLM without structure leads to unpredictable costs and unreliable outputs. What makes the use case a good fit for a multimodal agentic approach is that the system needs an agent that can reason about which capabilities to invoke for each ticket, combined with dedicated models for particular tasks like image classification, all managed within a deterministic pipeline that ensures every decision is auditable and every failure is handled.
Figure 2 below illustrates the high-level control flow of the agent-driven multimodal AI pipeline, showing how Apache Camel orchestrates LLM reasoning, retrieval-augmented generation, and model serving within a deterministic execution flow.
The system consists of several main parts:
- Apache Camel routes act as the main orchestration layer
- A LangChain4j agent handles reasoning and tool selection
- A vector database such as Qdrant supports RAG
- TensorFlow Serving hosts a ResNet50 model for image processing
- An external LLM provider, compatible with OpenAI standards, is also used
Instead of letting the agent interact directly with the infrastructure, it calls specialized tools. Each tool runs as a Camel-managed operation, and Camel uses enterprise integration patterns to make AI interactions even more reliable. This setup follows a key design principle: LLMs handle reasoning, dedicated models do the serving, while Camel manages the whole process.
AI Agents in Practice: Tools, Not Magic
The LangChain4j agent in this system has limited access. It can only use a small, clearly defined set of tools:
searchDocs(query)provides semantic search via vector DB lookupRunbook(team, category)provides static operational guidancecallModelServer(imagePath)is responsible for image classificationcreateJiraStub(summary, priority, team)performs downstream action
The agent focuses on planning, not carrying out tasks. It chooses which tools to use and in what order. Camel then carries out these choices, handling timeouts, retries, and validation. This setup helps prevent a common problem in agent systems: endless tool-use loops.
RAG as an Integration Problem
Although RAG is often presented as a core AI technique, in real-world applications it is more of a critical integration challenge. Within this system, documents are ingested into Qdrant during startup, embeddings are generated just once for efficiency, queries pull in the Top-K relevant context chunks, and the retrieved content is seamlessly attached to the exchange through an enrichment process. The LLM never interacts directly with the vector database; instead, Camel takes charge of the retrieval process, enforcing limits on payload size and deliberately incorporating citations, ensuring that context injection remains fully observable and constrained.
As a result, RAG becomes a predictable mechanism, achieved through structured routing rather than ad hoc improvisation. Figure 3 below illustrates how Camel manages each step of this process, from document retrieval to context enrichment to the final structured output.
Multimodal AI Without Multimodal Models
One key takeaway from this project is that you can build multimodal systems without needing multimodal models. Instead of sending images straight to a LLM, we send screenshots to TensorFlow Serving. There, a ResNet50 model creates labels and confidence scores. We use these results as structured signals, so the agent can reason based on the image insights instead of the raw images.
This approach is more cost-effective, efficient, and easier to manage. It also keeps LLMs focused on what they do best, which is especially important in production settings. Figure 4 below shows the happy-path execution of a support ticket through the agent-driven pipeline, from initial routing and agent reasoning to RAG, image inference, and structured output generation.
Hands-On Implementation
The project is structured as a multi-module Gradle application with the following components:
common/- DTOs and shared domain modelinfra/- Docker-based vector DB and model servingtriage-service/- Main service containing:routes/- Camel routesllm/- LLM client abstractionstools/- Agent toolsvectordb/- Vector DB access
Infrastructure is started locally via Docker Compose with Qdrant providing vector retrieval for RAG and TensorFlow Serving providing image inference for the multimodal path. The full source code is available in this GitHub repository.
The triage-service sub-project implements two main Camel routes:
DocumentIngestionRouteBuilder.java- Route for ingesting sample documents into vector database at startupTriageRouteBuilder.java- Main Camel route for ticket triage
AI elements are implemented in several classes that the TriageRouteBuilder class calls:
TriageTools.java- Tools exposed to the LLM agent for ticket triageOpenAiCompatibleChatClient.java- LLM Chat client with REAL OpenAI API integrationQdrantVectorDbClient.java- Qdrant vector database client implementation
Failure Is the Default: Designing for It Explicitly
One of the most valuable parts of this project was learning from the failures, not just the successes. Those challenges taught important lessons for real-world deployment. There were multiple practical issues, such as the differences between TensorFlow Serving's Docker images and model versions, large REST payloads (about 900KB for tensors) that caused silent connection failures, cold-start latency on the model servers, and undocumented HTTP limits in TensorFlow Serving.
Instead of hiding these problems, the architecture is built to expect and handle them, making the system more robust in uncertain situations. To accomplish this, Camel wraps every external call with safeguards such as Resilience4j circuit breakers, sets timeouts and retry strategies, and provides fallback options to protect key operations. So, even if image classification fails, the system still provides a reliable triage decision based only on text analysis and RAG. This is an intentional design choice that shows careful, resilient engineering.
Why These Tradeoffs Were Chosen
The architecture of this system was influenced by a series of deliberate choices aimed at balancing functionality, reliability, and maintainability:
- TensorFlow Serving - Chosen for model availability and ecosystem maturity, despite REST limitations
- Qdrant - Lightweight local setup, fast iteration, and simple operational model
- Agent with tools over pure RAG - Because reasoning about when to retrieve or classify is as important as retrieval itself
- No autonomous loops - Every execution path terminates deterministically
- No fine-tuning - The focus is on system architecture, not model optimization
These constraints keep the system understandable and operable by engineering teams, not just AI specialists.
Conclusion
Agentic and multimodal AI are not just ideas for the future. They are real architectural challenges that organizations face today. The main takeaway goes beyond any single framework or model. It is about adopting a new way of thinking: Treat AI components as unreliable dependencies that require thorough management, use proven integration patterns to handle probabilistic systems, keep reasoning and execution clearly separated, and design for partial failures rather than expecting perfect intelligence.
Combining Apache Camel with modern AI tools delivers a practical way forward. This approach respects decades of integration experience while making the most of new technologies. In the end, strong architecture matters more than raw intelligence in production environments.
About the Author

Vignesh Durai is a software engineering manager at Sentry Insurance, focusing on building and operating large-scale enterprise systems. He leads teams working on Java-based platforms, integration architectures, and AI-enabled workflows, with responsibility for translating emerging technologies into reliable, maintainable production systems. His work spans Guidewire, Apache Camel, distributed systems, and applied AI, with particular emphasis on agentic AI orchestration, retrieval-augmented generation, and multimodal pipelines that meet real-world requirements around reliability, governance, and team ownership. Vignesh writes about helping engineering teams move from experimentation to production by applying sound architectural principles to modern AI systems.
Comments
Please log in or register to join the discussion