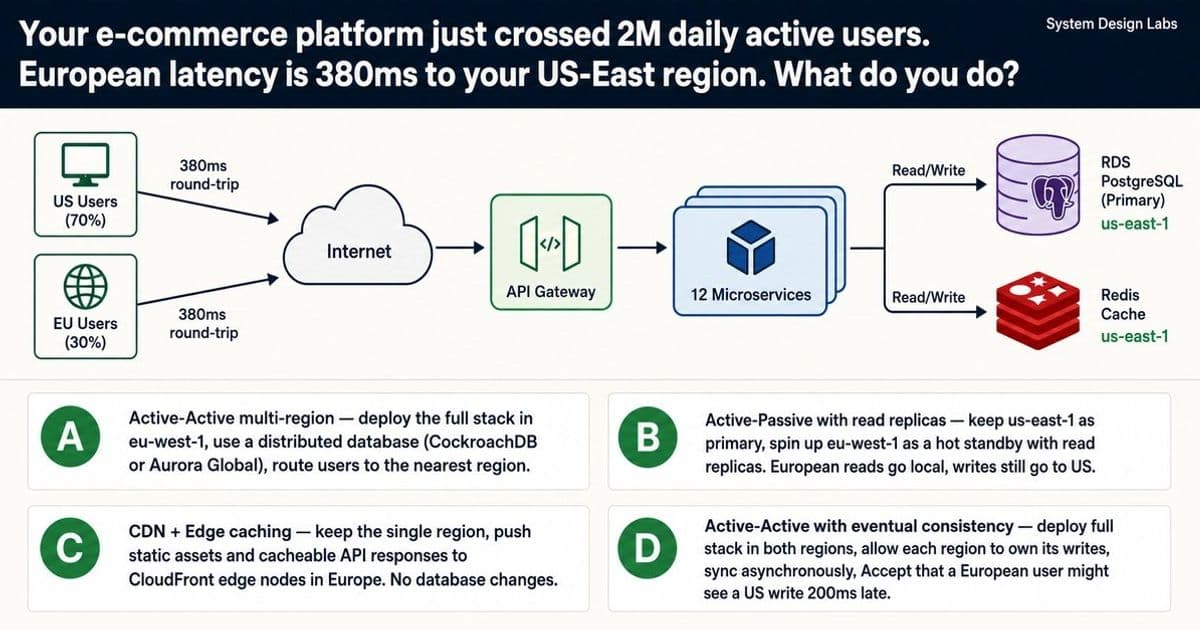
When European users experience 380ms latency on your e-commerce platform, choosing the right multi-region approach becomes critical. This analysis examines four architectural patterns under real-world constraints.
The Global Latency Challenge: Choosing the Right Multi-Region Strategy
When your e-commerce platform crosses 2M daily active users with a significant portion in Europe, latency isn't just a technical metric—it directly impacts business outcomes. The scenario is familiar to many scaling teams: 380ms average round-trip time from Europe to your US-East region, 40% spike in support tickets, and Black Friday looming in just six weeks. Your infrastructure consists of a single AWS region (us-east-1), RDS PostgreSQL as your primary database, Redis caching, and 12 microservices behind an API gateway. The goal is clear: get European latency under 80ms without a full database rewrite and before the shopping season begins.
Understanding the Problem
Latency complaints typically come from two sources:
- Read latency: European users waiting for product listings, order history, or account information
- Write latency: Users experiencing delays during checkout or cart updates
In most e-commerce scenarios, read operations significantly outnumber write operations. European users experiencing 380ms delays are likely frustrated primarily with browsing experiences, cart management, and order status checks—all read-heavy operations. While checkout (write) latency matters, users generally tolerate slightly higher write latency for critical transactions.
Evaluating the Multi-Region Options
Let's examine the four approaches under consideration, analyzing their technical implications, implementation complexity, and alignment with our constraints.
Option A: Active-Active Multi-Region with Distributed Database
Architecture: Deploy the full stack in eu-west-1, use a distributed database (CockroachDB or Aurora Global), route users to the nearest region, and write to both regions simultaneously.
Technical Implementation:
- Requires migrating from RDS PostgreSQL to a globally distributed database
- Implementing cross-region transactions with proper conflict resolution
- Setting up global load balancing and request routing
- Managing global clocks and handling clock skew
- Implementing sophisticated monitoring for distributed systems
Pros:
- True multi-region capability with low latency for both reads and writes
- High availability with automatic failover
- No single point of failure
Cons:
- Violates the no-rewrite constraint: Migrating from RDS PostgreSQL to a distributed database is a fundamental architecture change
- Implementation timeline: This is a multi-quarter project, not a six-week solution
- Operational complexity: Introduces new failure modes requiring extensive testing
- Expertise requirement: Requires specialized knowledge in distributed systems
Why it's not the right choice: While architecturally sound for long-term global scaling, this approach fundamentally violates the constraint of avoiding a database rewrite and cannot be implemented within the six-week timeline before Black Friday.
Option B: Active-Passive with Read Replicas
Architecture: Keep us-east-1 as the primary region, spin up eu-west-1 as a hot standby with read replicas, route European reads locally while writes still go to the US, and enable failover in minutes if the US goes down.
Technical Implementation:
- Provision RDS read replica in eu-west-1
- Configure application routing to send European read requests to the local replica
- Implement connection pooling to route appropriate queries to primary or replica
- Set up monitoring for replica lag and health
- Configure automated failover procedures
Pros:
- Solves the primary problem: Reduces European read latency from 380ms to ~15ms
- Meets constraints: No database rewrite required, implementation in 1-2 days
- Disaster recovery: Provides immediate failover capability
- Cost-effective: Lower than full active-active implementations
- Minimal risk: Leverages well-understood RDS replica functionality
Cons:
- Write latency remains high for European users
- Potential data loss during failover (though minimal with proper configuration)
- Replication lag could affect some real-time features
- Single point of failure at the primary region
Why it's the optimal choice: This approach directly addresses the core issue—European read latency—without violating constraints. The implementation timeline aligns perfectly with the six-week window before Black Friday, and it provides immediate disaster recovery benefits.
Option C: CDN + Edge Caching
Architecture: Keep the single region, push static assets and cacheable API responses to CloudFront edge nodes in Europe, with no database changes.
Technical Implementation:
- Configure CloudFront distribution with European edge locations
- Implement proper cache headers for static and semi-static content
- Set up cache invalidation strategies
- Configure origin request routing
- Implement edge computing for simple transformations
Pros:
- Quick implementation: Can be deployed in hours
- Low cost: Minimal additional infrastructure expense
- Improves static content delivery: Images, CSS, JavaScript load faster
- No database changes: Preserves existing architecture
Cons:
- Limited effectiveness: Only addresses static content, not dynamic user data
- Cache invalidation complexity: Managing stale data for personalized content
- Doesn't solve write latency: Checkout remains slow for European users
- Limited applicability: Many e-commerce operations are dynamic and user-specific
Why it's insufficient: While CDN is a valuable component of any global architecture, it addresses only part of the problem. European users are likely experiencing latency with dynamic content (cart, personalized recommendations, order status) that CDN cannot solve.
Option D: Active-Active with Eventual Consistency
Architecture: Deploy full stack in both regions, allow each region to own its writes, sync asynchronously, and accept delayed visibility of cross-region writes.
Technical Implementation:
- Deploy complete application stack in both regions
- Implement application-level conflict resolution
- Set up asynchronous replication between regions
- Modify business logic to handle eventual consistency
- Implement sophisticated monitoring for replication lag
Pros:
- Low latency for both reads and writes in each region
- No single point of failure
- Potentially simpler than strongly consistent active-active
Cons:
- High business risk: Potential for overselling, duplicate charges, or confusing user experiences
- Complex conflict resolution: Application-level handling of inconsistencies
- User experience challenges: Users might see different data in different regions
- Implementation complexity: Requires significant application changes
- Testing requirements: Extensive testing needed to handle edge cases
Why it's dangerous for this scenario: Eventual consistency introduces business logic complexities that cannot be properly addressed in a six-week timeline before Black Friday. The risk of overselling during peak shopping season or creating confusing user experiences outweighs the benefits.
The Winning Approach: Active-Passive with Read Replicas
Under the given constraints and timeline, Option B (Active-Passive with read replicas) provides the optimal balance of problem-solving, implementation speed, and risk management.
Implementation Roadmap
Week 1: Provision RDS read replica in eu-west-1
- Configure replica with appropriate instance type for expected read load
- Set up proper security groups and network connectivity
- Initialize replica from latest primary backup
Week 1: Configure application routing
- Implement geolocation-based routing in API gateway
- Modify connection pooling to route read queries to replica for European users
- Ensure write queries always go to primary
Week 2: Performance testing and optimization
- Test replica performance under expected load
- Monitor replication lag and optimize as needed
- Fine-tune query routing for optimal performance
Week 3: Failover testing and documentation
- Conduct failover drills to ensure smooth transition
- Document failover procedures for on-call engineers
- Set up monitoring alerts for replica health and lag
Weeks 4-6: Monitoring and refinement
- Monitor performance metrics in production
- Make adjustments based on observed behavior
- Prepare for Black Friday traffic
Expected Outcomes
- European read latency reduced from 380ms to ~15ms
- Support ticket volume should return to normal levels
- European users experience improved browsing and cart management
- System maintains existing write consistency guarantees
- Disaster recovery capability in place
Long-term Considerations
While the active-passive approach solves the immediate problem, teams should plan for eventual migration to a more sophisticated architecture. As the platform continues to scale:
- Monitor replication lag: As read volume increases, monitor for increased lag
- Plan database migration: When feasible, begin planning for migration to a globally distributed database
- Implement application-level optimizations: Consider strategies to reduce write volume from European users
- Evaluate sharding strategies: Regional data partitioning may become appropriate at larger scale
The Trade-offs That Matter
Every architectural decision involves trade-offs. In this scenario, the key trade-offs were:
- Speed vs. perfection: The active-passive approach provides an 80% solution in days rather than waiting for a 100% solution that would miss the Black Friday deadline
- Read optimization vs. write optimization: By optimizing for reads (which constitute the majority of operations), we accept higher write latency for a small percentage of transactions
- Operational simplicity vs. architectural elegance: The chosen approach leverages well-understood AWS functionality rather than cutting-edge distributed systems
Conclusion
When facing global latency challenges with tight deadlines, the optimal solution often involves pragmatic trade-offs rather than architecturally perfect but impractical approaches. In this scenario, the active-passive architecture with read replicas directly addresses the core problem—European read latency—without violating constraints or introducing unacceptable risk.
The key insight is that constraints often reveal the right answer. The inability to rewrite the database and the six-week timeline before Black Friday weren't limitations but guiding principles that led to the most effective solution. By focusing on the specific problem (read latency) rather than pursuing a comprehensive multi-region strategy, the team can deliver immediate value while planning for future architectural evolution.
For teams facing similar decisions, remember that the best architecture is one that solves the actual problem at hand within operational constraints, not the one that looks best on a whiteboard.
Comments
Please log in or register to join the discussion