Streambed lets developers capture PostgreSQL WAL changes via logical replication, write them as Parquet files to S3, and expose the resulting Iceberg tables through the PostgreSQL wire protocol. The project promises low‑overhead analytics without Spark or heavy ETL pipelines, but its trade‑offs around query performance, operational complexity, and ecosystem lock‑in invite scrutiny.
Streambed’s Claim: CDC from Postgres to Iceberg with Zero‑ETL Overhead
The open‑source project Streambed positions itself as a thin bridge between a production PostgreSQL instance and an Iceberg data lake on S3. By subscribing to PostgreSQL’s logical replication stream, it decodes WAL entries, batches rows into Parquet files, and commits Iceberg metadata. A built‑in query server, powered by DuckDB, speaks the PostgreSQL wire protocol so developers can keep using psql or any client they already trust.
Why the Community Is Paying Attention
- Cost‑focused analytics – Teams that already run PostgreSQL for OLTP often spin up a separate Spark or Flink cluster for reporting. Streambed promises to eliminate that extra layer, reducing both infrastructure spend and operational overhead.
- Familiar tooling – The ability to query Iceberg tables with familiar PostgreSQL syntax lowers the learning curve for data engineers who are uncomfortable with HiveQL or Spark SQL.
- Open‑source transparency – The codebase is written in Go, uses standard Docker‑Compose for local testing, and provides a clear CLI (
streambed sync,streambed query, etc.). This makes it easy to audit the replication logic and adapt it to custom environments.
Evidence from the Repository and Demo
- The quick‑start guide walks users through a Docker‑Compose stack that runs PostgreSQL and MinIO, then builds the binary with
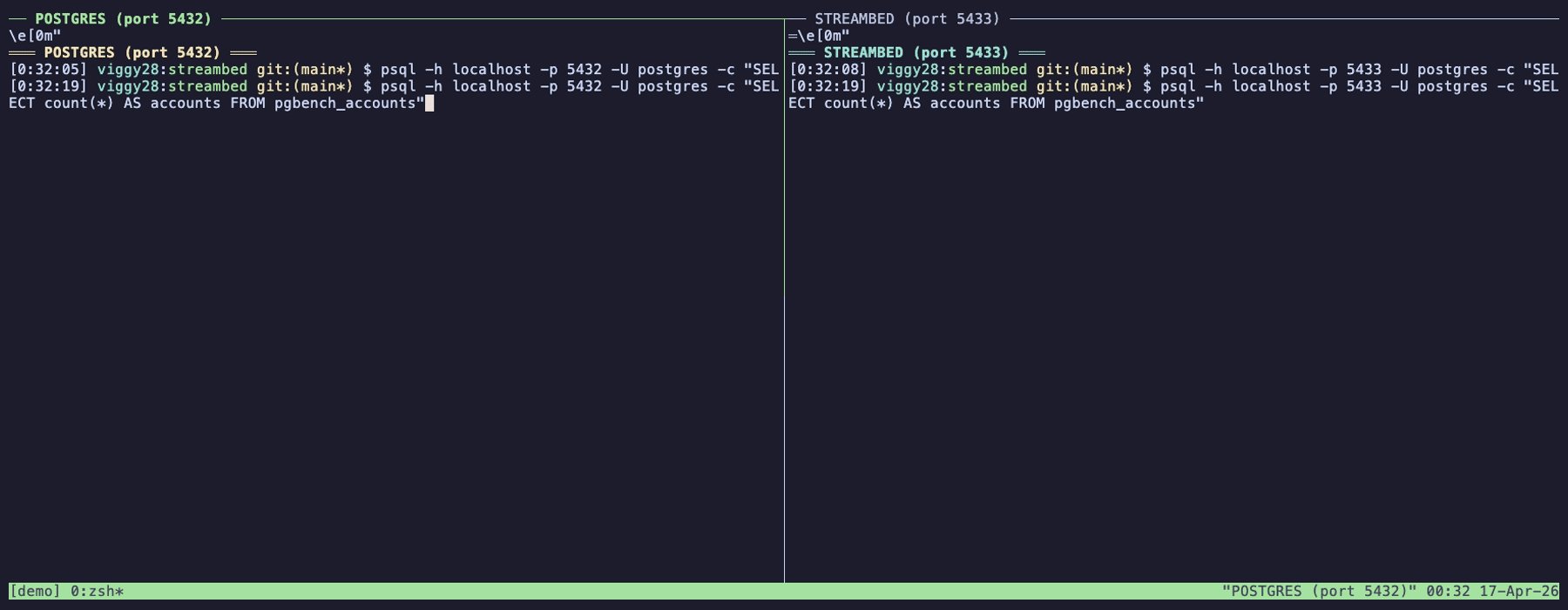
go build. A single command (./streambed sync …) starts both the CDC pipeline and the query server on port 5433. - A demo GIF shows a side‑by‑side comparison of a pgbench analytical query run directly on PostgreSQL versus the same query executed against the Iceberg view created by Streambed. The latency appears comparable for the modest dataset (1 M accounts, 500 K history rows), suggesting the pipeline adds little overhead for read‑heavy workloads.
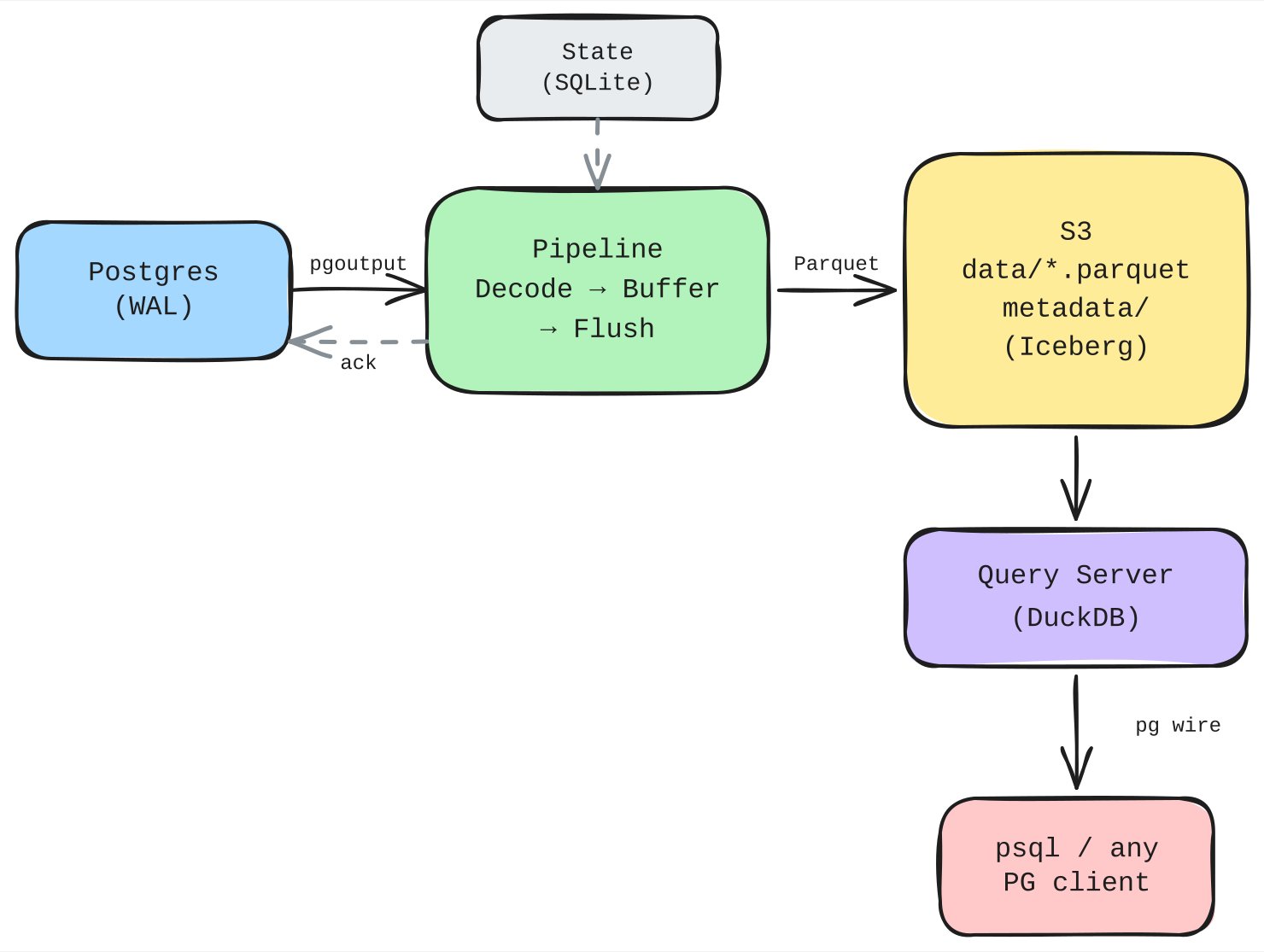
- The architecture diagram outlines a straightforward flow: Postgres WAL → Decode → Buffer → Parquet → S3 → Iceberg Commit with DuckDB acting as the query engine. No Spark, no Flink, no external orchestration.
Counter‑Perspectives: Where the Promise Meets Reality
1. Query Performance vs. Dedicated Engines
While DuckDB is impressive for single‑node analytics, it does not scale horizontally. For workloads that exceed a single node’s memory or CPU, the built‑in query server may become a bottleneck. Users needing sub‑second latency on large fact tables might still gravitate toward distributed engines like Trino or Presto, which can also read Iceberg tables directly.
2. Operational Complexity Hidden in Simplicity
Streambed abstracts the CDC pipeline, but it still requires careful configuration of:
- Logical replication slots on PostgreSQL (slot management, retention policies).
- S3 bucket lifecycle to prune old Parquet files and avoid storage bloat.
- Iceberg catalog consistency when multiple writers are involved (e.g., if you run several Streambed instances for different schemas). These concerns are not unique to Streambed, yet they reappear under a different veneer, and teams must still allocate time for monitoring and alerting.
3. Data Consistency Guarantees
The project uses a copy‑on‑write approach for updates and deletes, merging new Parquet files against existing ones. However, the documentation does not detail how it handles out‑of‑order WAL entries, network partitions, or replay after a crash. In high‑throughput environments, missing or duplicated rows could silently corrupt the analytical view, forcing users to implement additional validation layers.
4. Ecosystem Lock‑In Concerns
Although Iceberg is an open format, the current implementation ties the query surface to DuckDB’s PostgreSQL protocol shim. If a team later decides to switch to a different query engine, they will need to re‑expose the Iceberg tables via that engine’s connector, effectively duplicating the effort Streambed saved initially.
The Bigger Picture: A Niche Yet Valuable Tool
Streambed fills a clear gap for small‑to‑medium teams that want to offload reporting from their primary PostgreSQL instance without adopting a heavyweight data pipeline. Its minimal dependencies (Go, Docker, MinIO) make it attractive for rapid prototyping and for environments where Spark‑style ETL pipelines are overkill.
For organizations with large‑scale analytics requirements, the project is likely a stepping stone rather than a final solution. They may start with Streambed to validate the CDC‑to‑Iceberg workflow, then migrate to a more robust, distributed query engine as data volume grows.
What to Watch Next
- Community traction – The number of stars, forks, and issue activity will indicate whether Streambed gains a sustainable contributor base.
- Feature roadmap – Requests for multi‑node query servers, better failure recovery, and tighter integration with cloud‑native Iceberg catalogs (e.g., AWS Glue) could broaden its appeal.
- Comparative benchmarks – Independent performance tests against Trino, Spark, and Flink will help teams decide where Streambed fits in their stack.
If you’re curious, the repository includes a full integration test suite (./scripts/test-integration.sh) that spins up PostgreSQL and MinIO containers, providing a safe sandbox to evaluate reliability before committing to production.
In short, Streambed offers a pragmatic, low‑friction path to analytical queries on Iceberg, but its suitability hinges on workload size, tolerance for operational nuance, and the long‑term data strategy of the organization.
Comments
Please log in or register to join the discussion