
Tensordyne says Napier trades multiplier-heavy AI silicon for logarithmic math, more SRAM, and a 120kW rack design aimed at large-model inference in 2027.

Tensordyne announced Napier, a 3nm AI processor and rack-scale inference platform that targets large-model inference with logarithmic mathematics, dense SRAM, and an air-cooled TDN72 rack design.
The company wants buyers to judge Napier by tokens per rack and tokens per megawatt. That framing fits the current AI infrastructure problem. Model serving teams need throughput, memory capacity, and predictable power budgets as much as raw accelerator math.
Tensordyne says its logarithmic math approach converts multiplication work into addition work. Adders consume less die area than multipliers, so Tensordyne says Napier can devote more silicon to SRAM and data movement.

Tensordyne lists a 138 billion-transistor TSMC 3nm chip with 2.1 petaflops of compute per die, a 1.33GHz accelerator core, a 1.5GHz CPU, 256MB of SRAM, and 144GB of HBM3E. The company also claims Napier carries five times the SRAM of NVIDIA Blackwell.
That SRAM claim deserves attention because inference performance often turns on memory locality. If Tensordyne can keep more working data near the compute fabric, model serving teams could spend less rack power moving data across the system.
Tensordyne also has to prove accuracy and model support. New numerical approaches can create porting work, profiling gaps, and accuracy questions. Customers will want third-party benchmarks across PyTorch graphs, Triton kernels, long-context decode, and mixture-of-experts routing before they move production traffic.
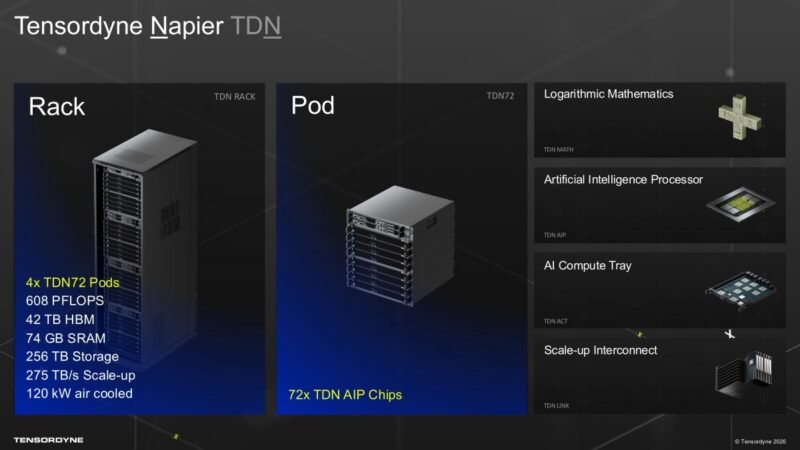
Tensordyne plans a full TDN72 system around 72 Napier chips, 68 petaflops of total compute, and 42TB of HBM. The company says the rack targets models with 10 trillion to 20 trillion parameters, where memory footprint and expert routing can define the deployment cost.
The company compares one 120kW TDN72 rack against larger configurations for two-trillion-parameter GPT mixture-of-experts models. Tensordyne says its rack can deliver 1,300 tokens per second per user, while NVIDIA and Groq require nine racks and 1.5MW, and AWS plus Cerebras require 14 racks and 800kW.

Those comparisons give builders a useful checklist. Ask for the prompt length, batch size, precision format, active parameter count, expert routing pattern, and service-level target. A vendor can make a rack look strong with favorable serving assumptions, so buyers need workload-level disclosures.
At the tray level, Tensordyne puts nine Napier chips into a 1RU AI Compute Tray with 1.3TB of HBM3E, 8TB of storage, Intel Xeon host CPUs, and dual 200GbE front-end networking. Four trays form a TDN72 pod, and four pods fill a standard 52RU rack.
Tensordyne targets air cooling for the rack. That design choice matters for data centers that have spare electrical capacity but lack warm-water loops or rear-door heat exchangers. A 120kW air-cooled rack still asks a lot from facility airflow, floor layout, and containment.
The dual 200GbE front end also raises a platform question. A PCIe Gen6 host path can drive 800Gbps across an x16 link, but Tensordyne’s listed interface suggests the Xeon host CPUs may not use that class of front-end bandwidth. Buyers should look at host-to-accelerator ingress rates, token streaming behavior, and network oversubscription before they model cluster throughput.
Tensordyne calls its scale-up interconnect TDN Link. The company says TDN Link provides sub-microsecond chip-to-chip latency and 1TB/s of bandwidth across the 72-chip system.
That interconnect claim matters because mixture-of-experts inference spends time routing activations and coordinating experts across devices. A fast accelerator loses ground if the serving stack stalls on cross-chip traffic. Builders should ask for latency distributions, failure-domain behavior, and real model traces rather than peak link figures alone.
Tensordyne says operators can group chips for workloads with topology-free failover. That feature could help teams place large models, isolate bad components, and keep service running during maintenance. The software stack has to make those decisions transparent enough for production teams.
Software will decide much of Napier’s fate. Tensordyne says it plans a Hugging Face-hosted model hub, an SDK, direct compilation for PyTorch and Triton models, and a Python eDSL called tensordyne.nn.
NVIDIA built CUDA into a broad base of kernels, profilers, deployment guides, and operator habits. Tensordyne needs a path that lets teams test existing models without months of kernel work. Good hardware can lose deals if developers cannot profile bottlenecks or recover from serving failures.

Partners help, but they do not remove execution risk. Tensordyne says it works with HPE and Juniper Networks for chassis and infrastructure components. The company also says Broadcom helped route the 3nm tape-out through TSMC.
Those names give Tensordyne a stronger systems story than a chip-only launch. Rack-scale AI products need board validation, firmware, cooling validation, service logistics, and field support. Customers buying 120kW racks will judge the platform as a cluster product.
Tensordyne says beta programs will begin in the first quarter of 2027, with system shipments expected by the end of the second quarter of 2027. That schedule puts Napier into a market that NVIDIA, AMD, Cerebras, Groq, AWS, and hyperscale internal silicon teams will keep changing.
Napier gives homelab and data center builders an architecture worth tracking because Tensordyne attacks inference cost through math, memory, and rack design at the same time. The 3nm tape-out, 256MB SRAM claim, 42TB HBM rack, and air-cooled 120kW target create a clear technical pitch.
The next proof points need numbers from real workloads. Buyers should ask Tensordyne for tokens per second per user, watts per token, accuracy deltas, time-to-first-token, decode throughput, and failure recovery tests on the models they plan to serve. If Napier meets those tests in 2027, Tensordyne could give inference clusters a new option for dense, power-aware large-model serving.
Comments
Please log in or register to join the discussion