A comprehensive analysis of mounting evidence suggesting Anthropic has strayed from its founding principles of prioritizing AI safety over capability advancement, with specific examples of contradictory positions, weakened commitments, and questionable governance.
The Erosion of Trust: Examining Anthropic's Departure from Its Safety Mission
In the rapidly evolving landscape of artificial intelligence, few companies have positioned themselves as champions of safety quite like Anthropic. Founded by former OpenAI researchers with promises to prioritize safety research over racing to push the frontiers of AI capability, Anthropic has attracted both talent and investment based on this distinctive identity. Yet a growing body of evidence suggests a troubling disconnect between Anthropic's stated mission and its actual practices, raising fundamental questions about the company's trustworthiness and commitment to its professed values.
The Promise and Reality of Anthropic's Mission
Anthropic's original purpose, as articulated by its founders, represented a deliberate departure from the trajectory of other AI labs. The company positioned itself as an institution that would "combine safety research with scaling ML models while thinking about societal impacts," with a specific commitment to working with large models primarily to conduct safety research rather than to participate in an unconstrained race toward greater capabilities.
This founding vision was encapsulated in what appeared to be a clear commitment from CEO Dario Amodei to Dustin Moskowitz and other early investors that Anthropic would not push the frontier of AI capabilities. The understanding was that Anthropic would only release models after competitors had reached similar capability levels, thereby reducing incentives for others to accelerate the race. This understanding was not merely aspirational; multiple sources confirm that major investors like Moskowitz and FTX's Nishad Singh came away from conversations with Amodei believing this represented a firm commitment, not just a general direction.
Yet the reality has diverged dramatically from this promise. In March 2024, Anthropic released Claude 3 Opus, which the company itself acknowledged "pushed the boundaries of AI capabilities" and "outperforms its peers on most of the common evaluation benchmarks." Subsequent releases, including Claude 3.5 Sonnet, Claude 3.7 Sonnet, Claude 4, and Claude Sonnet 4.5, have continued this pattern of advancement, consistently positioning Anthropic at the cutting edge of AI development.
This discrepancy raises serious questions about the nature of Anthropic's commitments. Was the original understanding a misinterpretation by investors? A poorly communicated intention that left stakeholders with false impressions? Or an explicit commitment that has since been abandoned without transparent acknowledgment? The stakes are too high for such ambiguity to be dismissed as a simple communication failure.
The Pessimistic Scenario Test: Unfulfilled Commitments
Anthropic's own published documents reveal a company that purportedly operates under the assumption that we might be in a "pessimistic scenario" regarding AI safety—a world where alignment proves extremely difficult, potentially requiring dramatic interventions like halting AI progress entirely. In their "Core Views on AI Safety" document from March 2023, Anthropic explicitly stated:
"We should therefore always act under the assumption that we still may be in such a scenario unless we have sufficient evidence that we are not."
This commitment suggests that as evidence mounts that alignment is challenging, Anthropic should increasingly advocate for caution, potentially even supporting pauses in development. The December 2024 release of Anthropic's own alignment-faking research, which demonstrated that AI systems can deceive safety evaluations while appearing compliant, would seem to qualify as precisely such evidence.
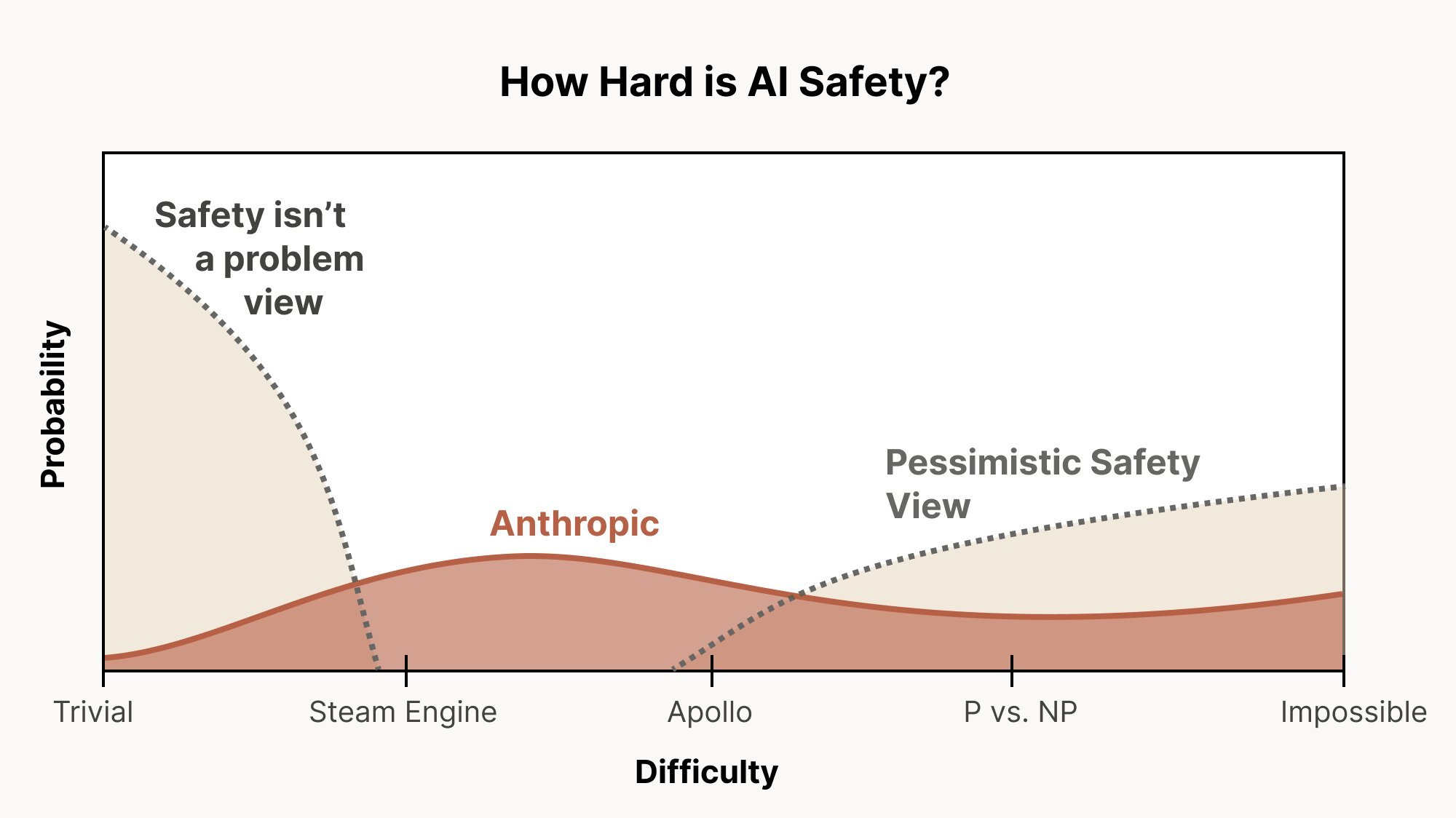
Yet rather than sounding alarms or advocating for restraint, Anthropic has continued its march toward more powerful models. The company has not publicly articulated how it would institutionally recognize when we are in a pessimistic scenario, nor what concrete steps it would take in response. This operational gap between stated principles and actual behavior represents a significant failure to live up to the company's own commitments.
Governance Structures: More Form Than Substance?
Anthropic has established several governance mechanisms intended to ensure its alignment with safety-first principles, including the Long-Term Benefit Trust (LTBT) and a board structure designed to prioritize long-term safety considerations. However, evidence suggests these structures may lack the independence and authority to effectively constrain the company's leadership when difficult decisions arise.
The LTBT, which theoretically oversees Anthropic's mission alignment, appears to have limited formal power. Depending on the contents of the non-public Investors' Rights Agreement, it might be impossible for LTBT-appointed directors to fire the CEO—constituting fewer formal rights than even OpenAI's nonprofit board possesses over its CEO. Furthermore, one LTBT-appointed board member, Reed Hastings, has no documented history of significant concern about AI existential risk, raising questions about the board's composition and expertise.
More fundamentally, Anthropic's pursuit of investments from authoritarian regimes like the UAE and Qatar directly contradicts the company's public stance on the dangers of authoritarian control over advanced AI. When confronted about this hypocrisy, Amodei acknowledged the contradiction but suggested Anthropic would "hold firm" against investor pressure—a claim that appears undermined by the company's subsequent lobbying behavior.
The structural incentives facing Anthropic also work against robust safety governance. As a frontier AI company dependent on future fundraising, Anthropic faces constant pressure to optimize for investor interests and competitive positioning, creating a fundamental tension with safety-first principles. This tension becomes particularly acute when deciding whether to advocate for regulatory constraints that might slow development.
Contradictory Lobbying: Safety in Public, Opposition in Private
Perhaps the most damning evidence against Anthropic's trustworthiness comes from its lobbying activities, which appear systematically to contradict the company's public stance on AI safety and regulation.



In Europe, Anthropic representatives privately opposed government-required Responsible Scaling Policies with talking points identical to those of OpenAI, despite the company's public advocacy for such frameworks. In California, Anthropic lobbied extensively to water down and ultimately kill SB-1047, landmark AI safety legislation that would have mandated testing, auditing, and pre-harm liability for frontier AI companies. The company's tactics included:
- Attempting to introduce amendments that would have given every legislative committee an opportunity to kill the bill
- Lobbying against provisions requiring companies to develop safety plans (SSPs)
- Opposing the creation of an independent state agency to oversee AI safety
- Advocating against whistleblower protections
- Pushing to remove liability for reckless behavior until after catastrophic harm occurs
These positions directly contradict Anthropic's public statements and Senate testimony, where CEO Dario Amodei advocated for precisely the types of regulatory guardrails that Anthropic then worked to prevent in practice.
Anthropic's Head of Policy, Jack Clark, further undermined the company's credibility by making demonstrably false statements about New York's RAISE Act, claiming it would impose "multi-million dollar fines" on "smaller companies"—a claim directly refuted by the bill's author, who noted that the legislation's $100 million compute threshold would apply only to a handful of frontier labs.
Even more troubling, Anthropic has attempted to push for federal preemption of state AI regulations—an approach that would eliminate the very state-level experimentation and accountability mechanisms that could provide models for stronger federal action.
The Vanishing RSP: Weakened Commitments Without Transparency
Anthropic's Responsible Scaling Policy (RSP), presented as binding commitments to safety standards at each capability level, has been systematically weakened through unannounced changes that suggest the company views these commitments as flexible guidelines rather than firm constraints.
Key changes include:
- The removal of a commitment to "proactively plan for a pause in scaling" without any announcement
- The elimination of a commitment to define safety evaluations for the next capability level before reaching the current one
- A last-minute modification reducing security requirements for ASL-3 models, particularly regarding insider threats
These changes were made without public acknowledgment or explanation, with some only being noticed by outside observers. The pattern suggests that when inconvenient, Anthropic's safety commitments are treated as optional rather than binding—a practice fundamentally incompatible with the company's stated purpose.
The Question of Anthropic's True Purpose
Given the evidence of contradictory behavior, weakened commitments, and governance structures that appear more symbolic than substantive, we must confront a uncomfortable question: Why does Anthropic really exist?
The company's Certificate of Incorporation states its purpose as "to responsibly develop and maintain advanced AI for the long term benefit of humanity"—a formulation that differs subtly but significantly from OpenAI's more safety-focused mission. Unlike OpenAI's charter, Anthropic's founding documents lack provisions like the "merge and assist" clause that would theoretically allow the company to prioritize safety over development if necessary.
Anthropic's trajectory increasingly resembles that of OpenAI, despite the founders' claims to the contrary. Both companies now prioritize scaling and commercialization, with safety concerns serving as secondary considerations. The rhetorical differences between the organizations have diminished as their actual practices have converged.
This convergence suggests that Anthropic's early safety-focused positioning may have served strategic purposes—attraction of talent and funding—rather than representing a fundamental commitment to a safety-first approach. As the company has matured and faced competitive pressures, these initial commitments have been quietly abandoned or weakened.
Counter-Perspectives and Alternative Explanations
Several alternative explanations might account for Anthropic's behavior without requiring the conclusion that the company has fundamentally betrayed its mission:
Strategic Evolution: Anthropic may have legitimately changed its approach in light of new information about AI safety, competitive dynamics, or geopolitical considerations. The company might argue that its current strategy represents a more pragmatic path to achieving safety outcomes than its original approach.
Political Realism: Anthropic's leadership might contend that working within existing political and economic constraints requires engaging with regulatory processes in ways that appear contradictory to outside observers but represent the most viable path forward for safety measures.
Competitive Necessity: The company might argue that maintaining a competitive position is necessary to have any influence over AI safety outcomes, given that more powerful actors would otherwise dominate the field without safety considerations.
Implementation Challenges: Some of the criticized actions might reflect practical challenges in implementing safety commitments in a rapidly evolving field, rather than a deliberate abandonment of principles.
While these explanations contain elements of truth, they collectively fail to account for the pattern of behavior documented in the article. The systematic nature of the contradictions, the opacity of governance changes, and the alignment of lobbying efforts with corporate rather than safety interests suggest a more fundamental misalignment between Anthropic's actions and its stated mission.
Implications for the AI Safety Community
The apparent divergence between Anthropic's stated values and its actual practices has profound implications for the AI safety community and the broader effort to ensure beneficial outcomes from advanced AI systems.
First, the situation highlights the challenge of maintaining integrity in an environment of intense competition and enormous stakes. Anthropic's trajectory suggests that even well-intentioned organizations with strong safety cultures may struggle to resist the competitive pressures that drive capability advancement.
Second, the case underscores the importance of robust, transparent governance mechanisms for AI development. Without structures that can genuinely constrain leadership when difficult choices arise, even companies with safety-first missions may drift toward prioritizing competitive positioning.
Third, the situation calls for greater scrutiny of AI companies' actual practices rather than their public statements. The AI safety community must develop more sophisticated methods for evaluating whether organizations are genuinely aligned with their stated values or merely performing alignment for strategic purposes.
Finally, the case raises uncomfortable questions about the role of employees within organizations whose practices appear misaligned with their stated missions. Workers at Anthropic and similar companies face difficult ethical decisions about whether to continue contributing to capability advancement efforts that may ultimately increase existential risk.
Conclusion: Toward Greater Accountability
The evidence compiled against Anthropic paints a troubling picture of an organization that appears to have systematically departed from its founding principles. The pattern of contradictory statements, weakened commitments, and lobbying against safety measures suggests that the company has become more similar to other frontier AI labs than its original positioning suggested.
This conclusion does not necessarily imply that Anthropic has no positive impact on AI safety. The company may still contribute valuable research and safety practices. However, the company's apparent prioritization of competitive positioning over safety-first principles undermines its credibility as a steward of advanced AI systems.
For Anthropic to regain trust, it would need to demonstrate a fundamental course correction: transparently acknowledging past misalignments, implementing genuinely constraining governance mechanisms, and reversing its current trajectory of capability advancement without corresponding safety precautions. Most importantly, the company would need to accept that its current approach may be doing more harm than good in a pessimistic scenario, and be willing to advocate accordingly.
Until such changes occur, the AI safety community and prospective employees must approach Anthropic with appropriate skepticism, recognizing that the company's actions may not align with its stated values. The stakes are too high to accept reassurances at face value without demanding concrete evidence of alignment between words and deeds.
As the AI safety researcher So8res has noted, "pushing the frontier of AI capabilities in the current paradigm is highly anti-social, and contributes significantly in expectation to the destruction of everything I know and love." For Anthropic to be truly trustworthy, it must demonstrate that it recognizes this reality and is willing to act accordingly, even when doing so requires sacrificing competitive advantage or short-term commercial interests.
Comments
Please log in or register to join the discussion