A recent experiment reveals that top-tier AI language models from different providers are producing strikingly similar outputs, raising questions about model diversity and the future of AI creativity.
The Great AI Convergence: Why All LLMs Sound the Same
In the rapidly evolving landscape of artificial intelligence, we've come to expect diversity and innovation from the various large language models (LLMs) developed by tech giants. However, a recent experiment suggests a surprising trend: these models, despite their different architectures and training methodologies, are beginning to converge on remarkably similar outputs. This raises critical questions about the future of AI creativity and the potential homogenization of artificial intelligence.
The Experiment: Testing the Boundaries of Randomness
The experiment, conducted by Jérémie Pinte, involved querying three of the most advanced LLMs—Claude Haiku 4.5, GPT-5 Mini, and Gemini 2.5 Flash—with simple, open-ended prompts designed to elicit varied responses. The goal was to determine whether these models, trained on different datasets and with different approaches, would produce distinct outputs or whether they would converge on similar answers.
The Joke Test
The first test asked each model to tell a joke. The results were striking:
- Claude Haiku 4.5: Repeated the same joke three times: "Why don't scientists trust atoms? Because they make up everything! 😄"
- GPT-5 Mini: Told the same joke twice, then offered a different joke: "Why did the scarecrow win an award? Because he was outstanding in his field."
- Gemini 2.5 Flash: Repeated the same joke three times: "Why don't scientists trust atoms? Because they make up everything! 😁"
Out of nine joke requests across three models, only two unique jokes were generated.
The Random Selection Test
To further test the models' creativity, the experiment asked each model to pick a random fruit and a random color. The results showed limited diversity:
Random Fruit Selection:
- Only two fruits were selected across all trials: "Apple" and "Mango"
- GPT-5 Mini exclusively chose "Mango" in all five trials
- Claude and Gemini showed slight variation but heavily favored these two options
Random Color Selection:
- The results were dominated by shades of blue, particularly "Teal" and "Turquoise"
- Gemini showed the most variation by occasionally selecting "Blue" and "Red"
- Despite the request for randomness, the models consistently chose from a narrow palette
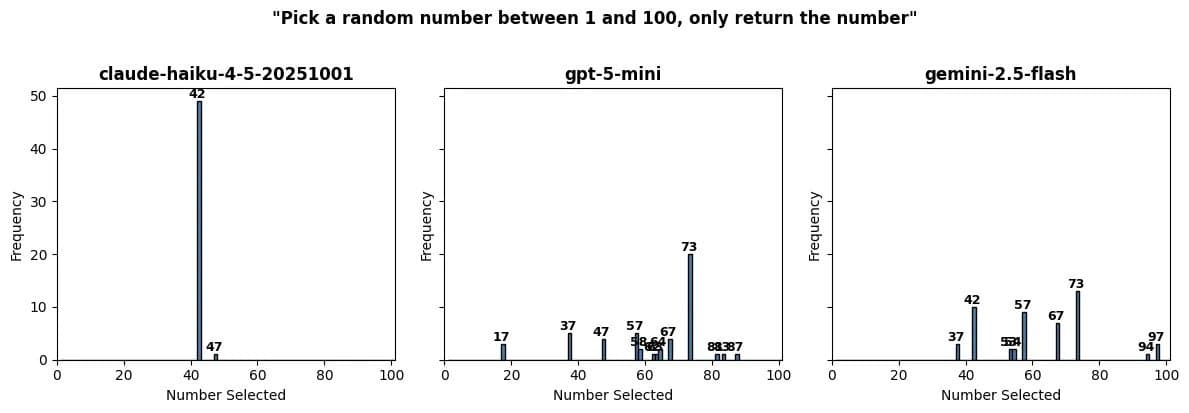
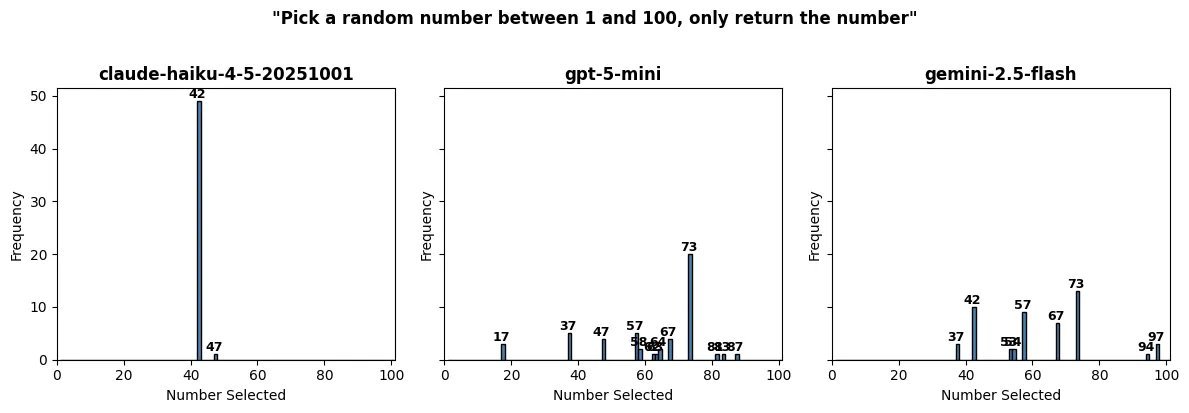
The Random Number Test
Perhaps most telling was the random number test, where each model was asked to pick a number between 1 and 100. When run 50 times per model, the results showed a clear bias toward specific numbers:
- 42: The famous "Answer to the Ultimate Question of Life, the Universe, and Everything" from The Hitchhiker's Guide to the Galaxy appeared with disproportionate frequency
- 73, 57, and 47: These numbers also appeared with surprising regularity
{{IMAGE:2}}
Analysis: Why Are Models Converging?
Several factors could explain this convergence:
Benchmark Culture and Overfitting: The AI industry places significant emphasis on benchmark performance. This pressure may lead developers to optimize models for specific tasks and datasets, resulting in similar outputs across different architectures.
Common Training Data Sources: Major AI companies often rely on similar large-scale datasets scraped from the internet. If these datasets contain the same jokes, examples, and patterns, the models trained on them will inevitably produce similar outputs.
Model Distillation: There's evidence that companies may be distilling (or copying) aspects of each other's models, either directly or through reverse engineering, leading to architectural and output similarities.
Safety and Alignment Constraints: As models become more integrated into everyday applications, developers implement stricter safety and alignment measures. These constraints may limit the diversity of outputs, particularly for creative or random tasks.
Implications for the Future of AI
This convergence raises several concerns:
Reduced Creativity and Diversity: If all major AI models produce similar outputs, we risk a future where AI-generated content becomes homogeneous and predictable.
Echo Chambers and Bias Amplification: Similar models trained on similar data may reinforce existing biases and create echo chambers in AI-generated content.
Innovation Stagnation: The AI field thrives on diversity of thought and approach. Convergence could stifle innovation and lead to incremental rather than breakthrough advancements.
User Experience Fatigue: Users may grow tired of AI systems that provide the same answers and suggestions, regardless of which provider they choose.
The Path Forward
The AI industry must recognize the importance of diversity in both model architecture and training data. Companies should:
- Develop unique approaches to model training and data curation
- Encourage creativity and randomness in AI systems
- Foster open research on the causes and effects of model convergence
- Consider the long-term implications of homogenized AI outputs
As we continue to integrate AI into every aspect of our lives, ensuring that these systems remain diverse, creative, and unpredictable is not just a technical challenge—it's a societal imperative. The future of AI shouldn't be a choice between different shades of beige; it should be a vibrant spectrum of possibilities, each as unique as the human minds that create and use these systems.
Comments
Please log in or register to join the discussion