Canonical is quietly rebuilding Ubuntu 26.10's archive against the x86-64-v3 micro-architecture level, and Phoronix put the amd64v3 packages head-to-head against stock amd64 on a Strix Halo box. The gains are real in the right code paths, modest in most, and worth understanding before you flip your repos.
Canonical keeps poking at the same question every cycle: should Ubuntu's baseline move past the 2003-era x86-64 floor? For Ubuntu 26.10 development, the answer is once again an experimental amd64v3 package archive that rebuilds the distribution targeting the x86-64-v3 micro-architecture feature level. It is not an official deliverable. There is no promised amd64v3 ISO, no guarantee any of this lands as a supported tier. But the repository exists, it installs cleanly on top of a stock daily build, and that makes it testable. Michael Larabel ran exactly that test, and the results are a useful reality check on what raising the baseline gets you in 2026.
What x86-64-v3 Actually Means
The x86-64 micro-architecture levels are a way to bucket CPU capability so compilers and distributions can target something newer than the original 2003 instruction set without hand-picking individual -march flags. The levels stack up like this:
| Level | Key additions | Roughly available since |
|---|---|---|
| x86-64 (v1) | Baseline SSE2, original AMD64 | 2003 |
| x86-64-v2 | SSE3, SSSE3, SSE4.1/4.2, POPCNT | ~2008-2009 (Nehalem) |
| x86-64-v3 | AVX, AVX2, FMA, BMI1/2, MOVBE, F16C | Intel Haswell (2013), AMD Excavator (2015) |
| x86-64-v4 | AVX-512 family | Skylake-X / Zen 4 |
When Ubuntu builds an amd64v3 package, the compiler is free to assume AVX2 and FMA are present. That matters most in code that vectorizes well: anything doing dense floating-point math, wide integer SIMD, or hashing where the autovectorizer or hand-written AVX2 paths can finally be the default rather than a runtime-dispatched fallback. RHEL 10 already moved its baseline to x86-64-v3, and CachyOS and other distributions ship v3/v4 archives, so Canonical is not breaking new ground here so much as deciding whether to follow.
The catch is that not all code vectorizes. A package full of branchy control flow, pointer chasing, or syscall-bound work sees almost nothing from a v3 rebuild. The instructions are available, but the compiler has nothing useful to do with them. This is why a distribution-wide rebuild produces a bimodal result: a handful of workloads jump, most barely move, and the question becomes whether the average is worth the cost of maintaining a second archive.
The Test Bench
The hardware here is the interesting part for homelab readers, because it is the kind of small high-density box a lot of us are eyeing for compute nodes. Larabel used a Framework Desktop with the AMD Ryzen AI Max+ 395 "Strix Halo," 64GB of LPDDR5-8000, a 2TB NVMe SSD, and the integrated Radeon 8060S graphics. Strix Halo is a Zen 5 part, so it sits well above the v3 baseline. It has full AVX-512, meaning a v3 build technically leaves AVX-512 on the table while still capturing the AVX2/FMA gains.
The methodology was clean and the part worth copying if you want to replicate it: install the Ubuntu 26.10 amd64 daily ISO from 8 June, benchmark it, then upgrade every package in place to the amd64v3 variants and re-run on the identical system. Same kernel behavior, same hardware, same thermal envelope. The only variable that moves is the compiled instruction set of userspace. That isolation is what makes the numbers trustworthy.
Where The Gains Show Up
The test matrix spanned nine pages of workloads, and the spread is exactly what the theory predicts. The categories that benefit are the math- and SIMD-heavy ones:
- Imaging pipelines like Darktable and GEGL, where pixel operations map directly onto AVX2 lanes.
- Scientific and DSP code such as GNU Radio, GNU Octave, and GraphicsMagick, where FMA and wide vectors do real work.
- Compression with Zstd and LZ4, where the hashing and matching loops can pick up MOVBE and BMI gains depending on build.
- Crypto through OpenSSL, Botan, GnuPG, and cryptsetup, though here the story is muddier because many crypto libraries already do runtime CPU dispatch and ship hand-tuned AVX2 paths regardless of compiler baseline. When a library already detects your CPU and jumps to its fastest kernel at runtime, a v3 rebuild changes little. That is the single most important caveat in the whole comparison.
{{IMAGE:5}}
Workloads like POV-Ray ray tracing, R, RawTherapee, and the Python and PHP scripting tests round out the lower-variance end. Interpreted-language benchmarks in particular tend to show small deltas, because the interpreter loop is the bottleneck and it is not the kind of code that vectorizes into a v3 win.
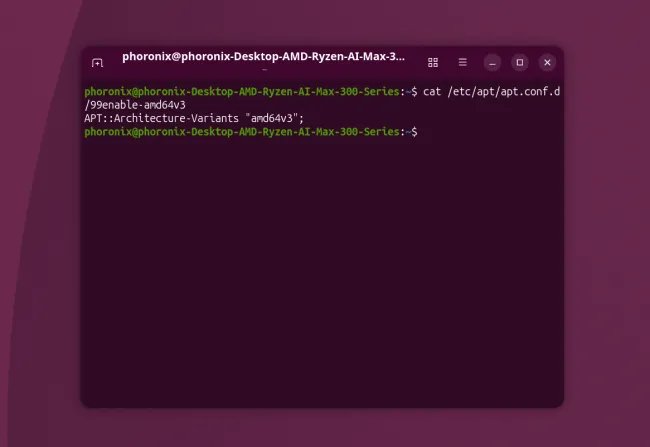
Build Recommendations
If you run a homelab and you are tempted to flip your Ubuntu boxes to the amd64v3 archive, here is how I would frame the decision after reading through the results.
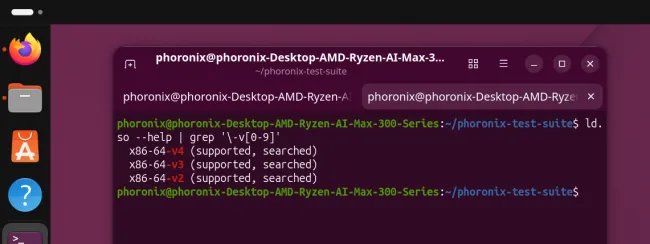
First, check that every machine you would touch is genuinely v3-capable. Anything older than Haswell on Intel or Excavator on AMD will fail to run these binaries, and a mixed fleet means you cannot share one archive. For most people running Zen 2 or newer mini-PCs and recent Xeons or Core parts, this is a non-issue, but verify with /lib/ld-linux-x86-64.so.2 --help | grep supported, which prints the highest micro-architecture level glibc detects.
Second, match the rebuild to your actual workload. If your node spends its life transcoding, running image pipelines, doing scientific compute, or compressing backups, a v3 archive is a free single-digit-to-better percentage uplift on the work that matters. If your node mostly serves a database, runs containers doing I/O-bound web traffic, or sits in OpenSSL paths that already dispatch at runtime, the win rounds to noise and you are adding archive-management risk for nothing.
Third, treat this as experimental, because it is. There is no support commitment, no guaranteed security-update cadence matching the main archive, and no ISO. For a production homelab service you care about, stay on amd64 and watch whether Canonical promotes v3 to a supported tier. For a throwaway compute node where you want to squeeze the Strix Halo or a Zen 4 part, the amd64v3 repo is a reasonable thing to experiment with.
The broader pattern is the one to keep an eye on. RHEL 10 already moved its floor to v3, and each cycle Canonical gets a little closer to a decision. The honest read of these benchmarks is that x86-64-v3 is not a free lunch large enough to justify a forced ecosystem-wide jump on its own merits, but it is a steady, real gain in the workloads that happen to be the ones enthusiasts and compute users care most about. When the baseline does eventually move, the machines doing heavy math will notice and the machines pushing packets will not, and that asymmetry is the whole story these nine pages of results tell. The full benchmark breakdown is up at Phoronix for anyone who wants the per-test numbers.
Comments
Please log in or register to join the discussion