A deep look at Faros.ai’s telemetry data reveals that while large language models boost individual developer output, they also slow system‑level flow and raise defect rates, prompting a debate over the true value of AI‑assisted coding.
When Speed Beats Quality: How LLMs Are Reshaping Software Development Operations
Talk is cheap, but data isn’t.
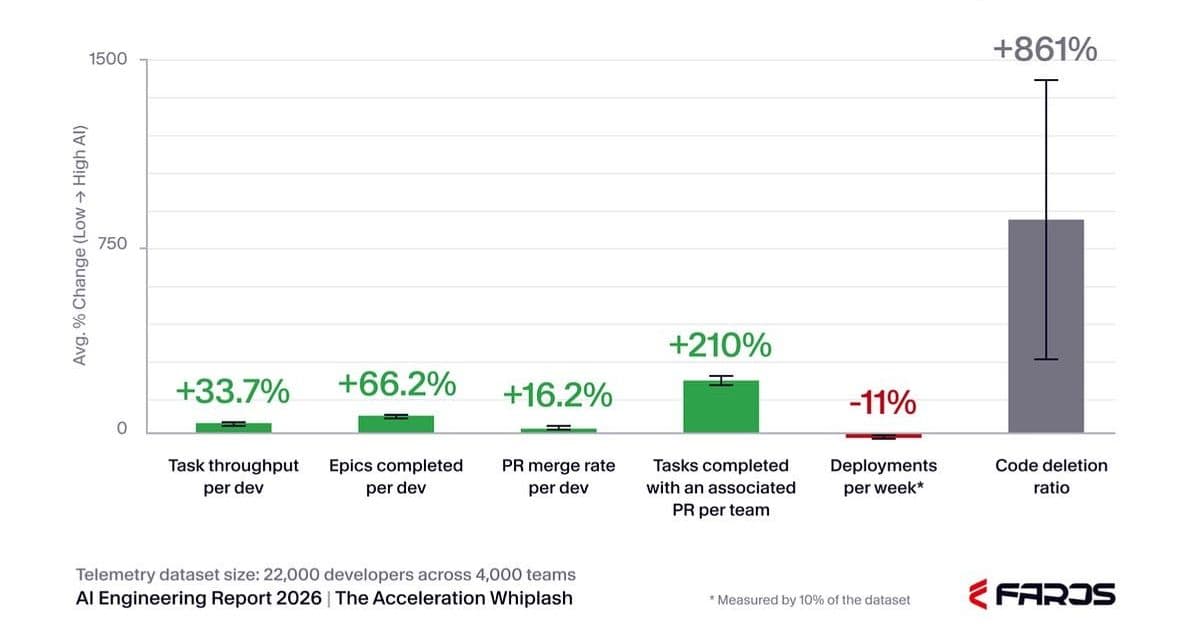
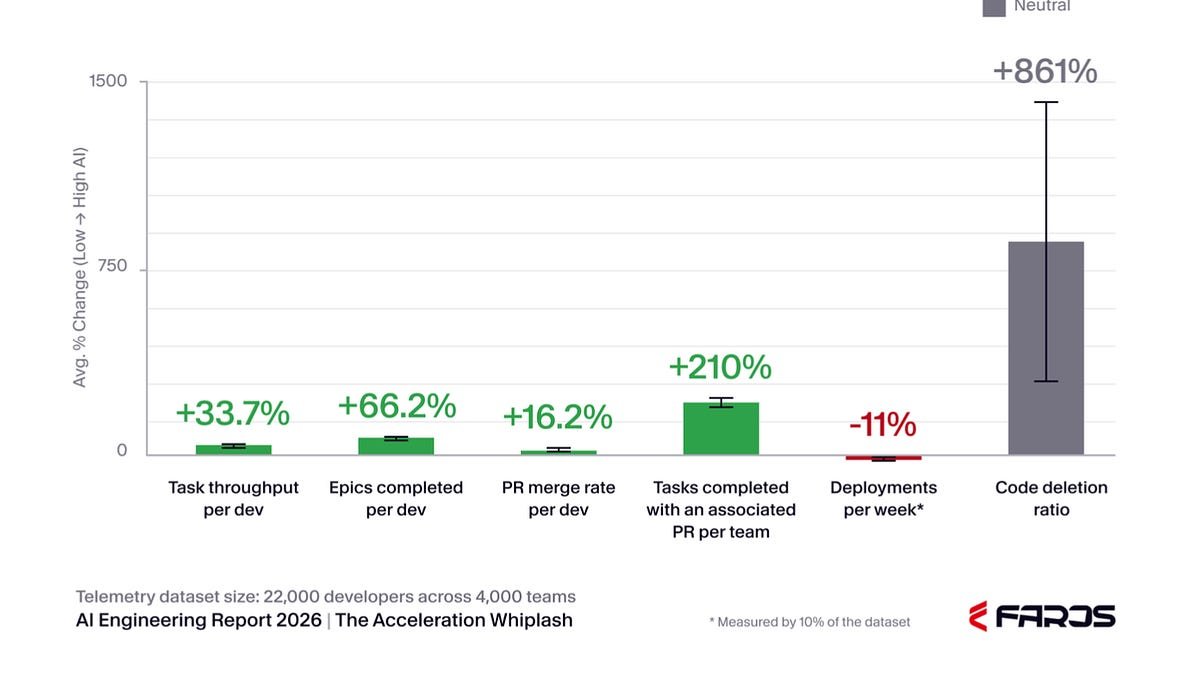
In a recent Faros.ai telemetry report covering 22,000 developers across 4,000 teams, the operational impact of AI‑assisted coding was measured directly against teams that do not use large language models (LLMs). The numbers are stark and challenge the prevailing optimism that LLMs will automatically translate into higher business value.
The headline findings
| Metric | Teams using LLMs | Teams without LLMs |
|---|---|---|
| Developer‑level productivity (tasks per person) | +10‑15 % | baseline |
| Deployment frequency (releases per week) | ‑11 % | baseline |
| Defect rate per developer | +50 % | baseline |
| System‑level throughput (features shipped per unit time) | ‑71 % to ‑80 % | baseline |
Source: Faros.ai “AI‑Assisted Development Telemetry Report”, March 2026.
1. Individual productivity does rise
The data confirms what many anecdotal accounts have suggested: developers who tap an LLM for code snippets, test generation, or documentation finish more tasks per day. The boost, however, tops out around 2× at best, far short of the “10× programmer” narrative that circulates on social media.
2. System flow collapses
Deployment frequency—a direct proxy for how quickly value reaches customers— fell 11 % on average. When the report’s authors applied Little’s Law (L = λ × W) to estimate overall throughput, the implied drop ranged from 20 % to 29 % in the arrival rate of completed work, translating to a 71 %–80 % reduction in finished‑goods output. In plain terms, teams are working faster on individual tickets but shipping slower.
3. Quality erodes dramatically
Defect density per developer climbed 50 %. Because defects propagate through CI/CD pipelines, the cost of rework escalates non‑linearly. The report flags a steep rise in code‑deletion ratios, suggesting that many AI‑generated changes are being undone after the fact.
Why the paradox?
The “first‑draft” trap
Many engineers treat the LLM as a drafting tool—they let the model write the initial implementation and then edit the output. This shifts the cognitive load of design onto the model, while the human reviewer inherits the responsibility for hidden bugs. The result is a higher defect rate and longer verification cycles, which explains the slowdown in deployment frequency.
Amplification of existing weaknesses
A separate study, DORA’s 2025 State of AI‑Assisted Software Development, argued that strong engineering foundations protect against AI‑induced downsides. Faros’ telemetry contradicts that claim: high‑performing teams still see the same degradation, indicating that the technology’s unreliability overwhelms even mature processes.
Counter‑perspectives
Optimists point to the productivity gain
Proponents argue that a 10‑15 % rise in individual output can be leveraged if organizations redesign workflows. They cite Azeem Azhar’s analogy to the early electricity grid—initial inefficiencies eventually gave way to massive productivity gains once the ecosystem adapted.
Critics warn of a structural mismatch
Others note that unlike physical infrastructure, LLMs are inherently stochastic. Their outputs are not repeatable, making deterministic testing and backward compatibility harder to guarantee. This fundamental unreliability means that the “grid‑like” maturation curve may never materialize; the technology may remain a productivity aid rather than a foundational platform.
What can teams do?
- Restrict LLM use to augmentation, not generation – Treat the model as a search‑assistant that suggests snippets, not as a primary author.
- Institute rigorous post‑generation review – Pair every AI‑written change with a mandatory peer review focused on design intent and edge‑case testing.
- Measure system‑level outcomes – Track deployment frequency, lead time, and defect escape rates alongside individual productivity metrics to catch negative trends early.
- Invest in tooling that surfaces AI‑induced risk – Plugins that flag high‑confidence code changes lacking test coverage can help mitigate the hidden cost of drafts.
Bottom line
The Faros data paints a nuanced picture: LLMs do make developers faster, but the speed is largely illusory when you consider the full delivery pipeline. Without disciplined usage patterns and system‑wide safeguards, the net effect is a destruction of value—slower releases, more bugs, and higher rework costs.
The conversation now shifts from “Will LLMs make us more productive?” to “How do we integrate them without sacrificing system throughput and quality?”. The answer will likely determine whether AI‑assisted coding remains a niche productivity boost or becomes a sustainable pillar of modern software engineering.
For the full Faros report, see the official PDF.
Comments
Please log in or register to join the discussion