The post argues that for many AI‑driven workloads, a local SQLite file backed by Litestream offers enough durability without the overhead of a full‑blown database service. It explains the mechanics, shows where the approach shines, and outlines the trade‑offs compared with Postgres‑based orchestration.
SQLite Is All You Need for Durable Workflows
Published on 2026‑05‑29
Obelisk – a lightweight workflow engine – has been used to demonstrate that a local SQLite file, replicated with Litestream, can replace a traditional orchestration stack for a surprisingly large class of AI‑centric pipelines.
What the claim is
The blog post contends that durable execution does not require a separate database service.
If the workflow state is stored transactionally in a file, the compute nodes can be cheap, throw‑away containers.
The author extends the earlier DBOS argument that “Postgres is all you need” and pushes it further: for many AI agents, SQLite + Litestream = sufficient durability.
How it actually works
1. Workflow state lives in SQLite
- Transactional guarantees – SQLite’s ACID semantics ensure that each step of a workflow is either fully recorded or not recorded at all.
- Zero network hop – The database file resides on the same VM or container that runs the task, eliminating latency and a separate control plane.
- Simple inspection – Because the state is a regular file, developers can copy it, open it with any SQLite client, and replay the log without special tooling.
2. Litestream provides asynchronous backup
Litestream watches the SQLite write‑ahead log and streams changes to an S3‑compatible bucket.
This gives you:
- Point‑in‑time snapshots – You can restore a recent version of the file if the local volume disappears.
- Cross‑region durability – Backups live in object storage, which is typically replicated across zones.
- Low‑cost persistence – No need for a managed database instance; you pay only for storage.
Note: Litestream is asynchronous. If a crash occurs before the latest pages are flushed to S3, those writes are lost. For many experimental AI pipelines this is acceptable, but it is not a substitute for a strongly consistent, highly available shared database.
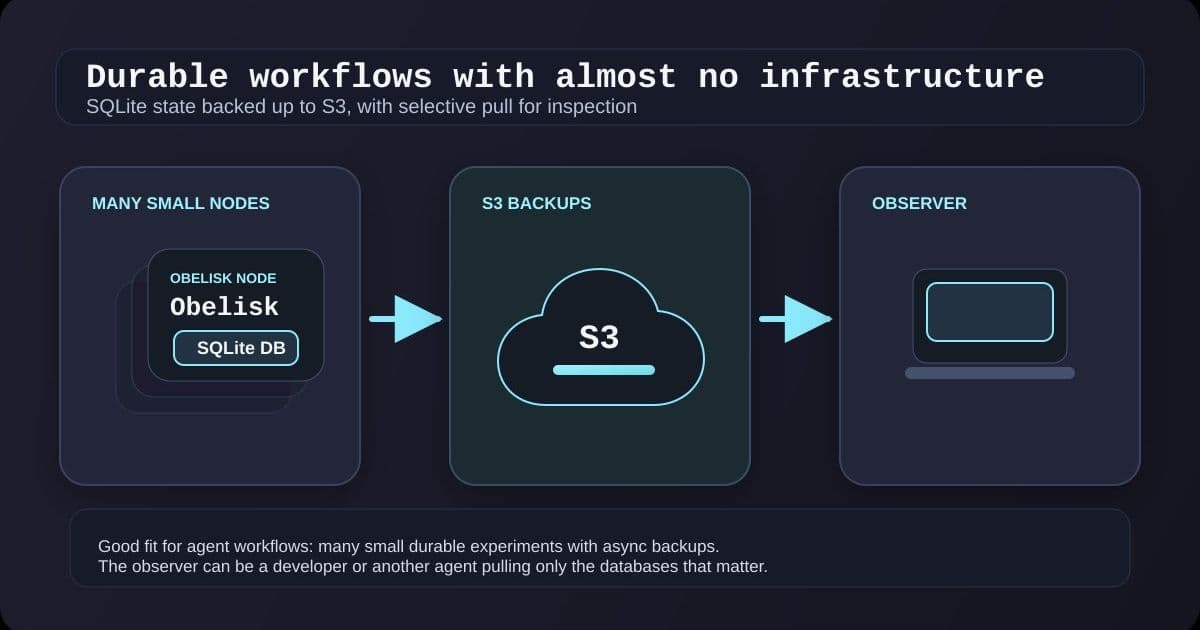
3. The overall operating model
- Obelisk server runs with a local
workflow.dbSQLite file. - Litestream streams that file to an S3 bucket.
- Observer services (e.g., a debugging UI) pull the latest backup for inspection or replay.
- Workers are stateless containers that read the persisted state, perform a step, and write back to the same SQLite file.

The diagram above shows multiple Obelisk workers writing to a shared SQLite file, Litestream backing it up, and an observer pulling copies for analysis.
Where the approach shines
| Scenario | Why SQLite + Litestream works |
|---|---|
| Burst‑oriented AI agents | Each agent can run in its own micro‑VM with a tiny local DB; no need to provision a multi‑tenant Postgres cluster. |
| Experimentation pipelines | Rapid iteration, cheap VMs, and easy roll‑backs by swapping the SQLite file. |
| Cost‑sensitive workloads | Storage on S3 is orders of magnitude cheaper than a continuously running DB instance. |
| Fault isolation | A failure of one worker only corrupts its own SQLite file; other agents remain unaffected. |
Limitations and when to prefer Postgres
- Strong consistency across many workers – If dozens of workers must read and write the same state concurrently, SQLite’s file‑locking can become a bottleneck. Postgres handles concurrent transactions at scale.
- High availability requirements – Litestream’s eventual‑consistency model cannot guarantee zero data loss. For mission‑critical services you still need a replicated DB with automatic failover.
- Complex query patterns – SQLite is fine for key‑value style workflow logs, but analytical queries over large tables are better served by a relational engine with advanced indexing.
- Regulatory durability – Some compliance regimes require synchronous replication to a separate location; Litestream’s async model may not satisfy those rules.
When any of the above apply, Obelisk’s built‑in Postgres support is the safer choice.
Practical steps to try it yourself
- Deploy an Obelisk server using the Docker image:
docker run -v /data:/db obeli/obelisk:latest. - Initialize SQLite – The server creates
workflow.dbautomatically on first run. - Add Litestream – Follow the Litestream quick‑start guide to configure replication to your S3 bucket.
- Write a simple workflow – See the Obelisk example repo for a Python task that logs each step to the DB.
- Inspect the state –
sqlite3 /data/workflow.db "SELECT * FROM events ORDER BY ts;"shows the full execution log.
Bottom line
SQLite plus Litestream is not a universal replacement for a managed database, but for a large subset of AI‑driven, bursty, experimental workloads it offers a minimal, cheap, and inspectable durability layer. The trade‑off is a weaker durability guarantee and limited concurrency. When those constraints line up with your use case, the stack lets you ship durable agents without the operational overhead of a separate orchestration tier.
Comments
Please log in or register to join the discussion