LLMs
OpenAI’s GPT‑4 Turbo Beats GPT‑4 on Cost and Speed, but Gains Are Incremental
5/29/2026
LLMs
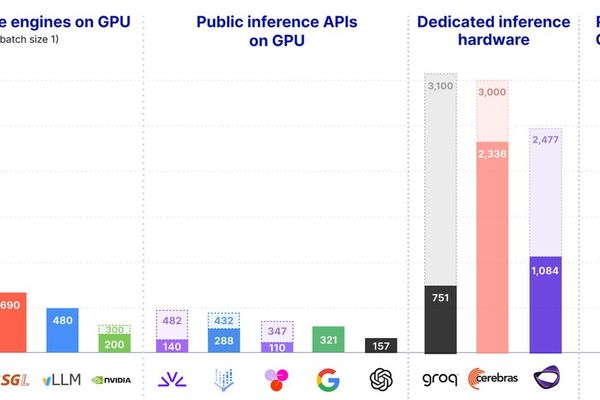
Real‑time LLM Inference on Standard GPUs Hits 3,000 tokens/s per Request
5/29/2026

LLMs
Stepfun releases Step 3.7 Flash: a 196 B sparse‑MoE model tuned for agent pipelines
5/29/2026

LLMs
Claude Opus 4.8: modest gains, honest trade‑offs
5/29/2026

LLMs
AI Models Need Sleep: CMU Research Shows Performance Boost from 'Napping' LLMs
5/29/2026

LLMs
Mysterious Hy3 LLM Surges to Top of OpenRouter Rankings
5/29/2026
LLMs
Claude Opus 4.8 Arrives with Bigger Coding Gains and Sharper Honesty
5/28/2026

LLMs
About LLMs at Zig Days
5/28/2026

LLMs
Beyond Benchmarks: Frontier LLM Disagreement on Fact-Checks
5/28/2026

LLMs
MiniMax’s M3 LLM promises faster sparse attention but still faces open questions
5/28/2026

LLMs
Self‑Improving Tax Agents with Codex: What the Pilot Actually Achieved
5/27/2026
LLMs
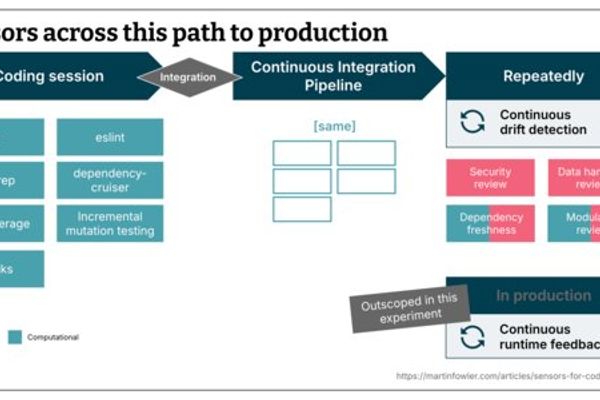
Maintainability Sensors for Coding Agents – A Pragmatic Field Report
5/27/2026

LLMs
Sleep‑Inspired Consolidation for Long‑Context Language Models
5/26/2026