
LLMs
How Semantic Routers Cut Claude Code Skill Tokens by 456×
5/26/2026
LLMs
Distributed LLM inference on Apple silicon: why DwarfStar is looking at multi‑Mac setups
5/25/2026

LLMs
LLM Randomness Under the Microscope: How GPT‑4.1 Mirrors Human Number‑Picking Bias
5/25/2026
LLMs
Re‑creating Usborne’s 1983 ‘Mad House’ game in vanilla JavaScript
5/25/2026

LLMs
Gemma 4 Multi‑Token Prediction Cuts Inference Latency by Up to Three‑Fold
5/25/2026

LLMs
Qwen 3.7 Max: Evaluating Alibaba's Long-Running LLM Claims
5/25/2026

LLMs
LLMs vs. Small Language Models: A Distributed Systems Perspective
5/25/2026
LLMs
datasette-agent 0.1a4 Integrates LLM Agents into Datasette's Navigation System
5/25/2026
LLMs
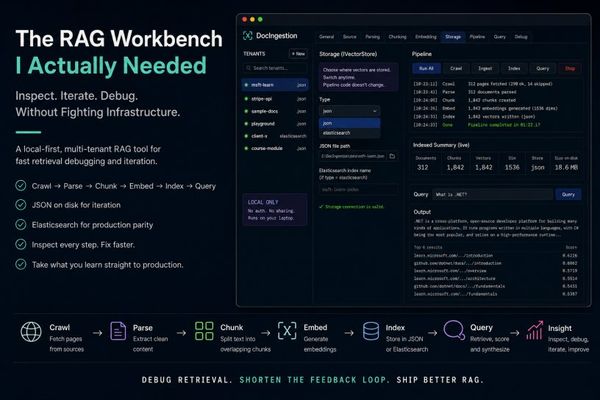
Why a Local‑First RAG Workbench Beats Early‑Stage Vector Databases
5/23/2026

LLMs
Why AI Isn’t Replacing Developers – It’s Amplifying Skill
5/22/2026

LLMs
OpenSCAD LLM Benchmark: Building the Pantheon
5/22/2026
LLMs
Cohere Command A+ Joins Microsoft Foundry Managed Compute – What It Means for Multi‑Cloud AI Strategies
5/22/2026
LLMs
KVBoost: Optimizing LLM Inference Without Model Surgery
5/22/2026