
Atomicity is not just a database definition. It is the rule that keeps partial failure from turning one business operation into several conflicting versions of truth.
Problem
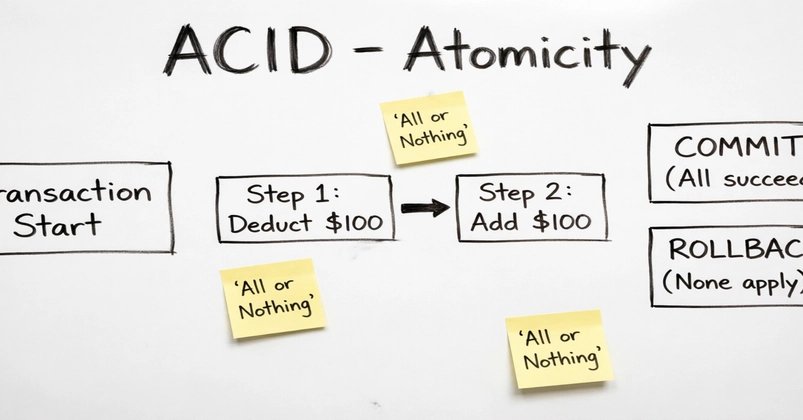
ACID is usually introduced as a checklist: atomicity, consistency, isolation, and durability. That framing is accurate, but it can make the ideas feel smaller than they are. Atomicity, in particular, is not an academic property. It is the line between a system that can fail cleanly and a system that quietly writes contradictory facts.
A transaction should either fully happen or not happen at all. If a payment repair workflow marks an abnormal top-up as resolved, credits the player's wallet, updates lifetime spend, and writes an audit record, those writes are not four unrelated database operations. They are one business fact expressed across several tables or documents. If only the first write succeeds, the system now says the case is resolved while the player never received the money.
That is how many production data incidents start. Not with exotic distributed consensus bugs, but with code that treats a multi-step state transition as a list of independent writes.
Solution Approach
The direct fix is to put all dependent writes inside a database transaction. In PostgreSQL, MySQL InnoDB, SQL Server, MongoDB, and most serious data stores, transactions give the application a controlled failure boundary. PostgreSQL documents this model clearly in its transaction tutorial, and Prisma exposes it through $transaction for application code using Prisma Client.
Conceptually, the abnormal top-up repair should be modeled as one command:
resolveAbnormalTopUp(orderId)
Inside that command, the system reads the order, changes its status, increments the wallet balance, updates the player's cumulative amount, and writes the audit log. If any step fails, the transaction rolls back. The database returns to the state it had before the command began.
That matters because application code is full of partial failure points. The process can crash. The database connection can time out. A row can be locked. A uniqueness constraint can reject a write. A deploy can terminate a worker halfway through a request. In a distributed system, these are not edge cases. They are normal operating conditions.
Atomicity gives the application a smaller promise than many people assume, but it is still a valuable one. It does not mean the user saw a successful response. It does not mean downstream services processed an event. It does not mean a cache was updated. It means the database did not persist half of the transaction.
Consistency Models and Isolation
Atomicity often gets confused with consistency. Atomicity says the transaction is all-or-nothing. Consistency says the transaction moves the database from one valid state to another valid state. Constraints, foreign keys, check rules, and application invariants all contribute to that validity.
Isolation is the next problem. Two top-up repair jobs running at the same time can both read the same order and both attempt to credit the same wallet. A transaction alone does not automatically mean the business operation is safe under concurrency. The isolation level decides what concurrent transactions can observe.
Under weaker isolation, systems can see stale reads, non-repeatable reads, or write skew. Under stronger isolation, such as serializable isolation, the database tries to make concurrent transactions behave as if they ran one after another. That gives cleaner reasoning, but it can increase lock contention and transaction retries. PostgreSQL's transaction isolation documentation is a useful reference because it explains the practical differences between isolation levels.
For wallet-like systems, the usual pattern is to make money movement append-only where possible. Instead of only storing wallet.balance, store ledger entries and derive or reconcile the balance. The balance can still be materialized for fast reads, but the ledger is the source of truth. That design gives operators a way to audit, replay, and repair state after failures.
API Patterns
Atomicity inside the database should be paired with API-level idempotency. Payment and top-up APIs are especially vulnerable to retries. A client may send the same request twice because it did not receive a response. A queue worker may retry after a timeout even though the first attempt committed. Without idempotency, retry safety becomes guesswork.
A common API shape is to require an idempotency key for commands that create financial effects. Stripe's idempotent request model is a good example. The server records the key and the result of the first request. Later retries with the same key return the same logical result rather than applying the money movement again.
At the database layer, that usually means a unique constraint on a command identifier, payment provider event ID, or idempotency key. The transaction checks or inserts that key as part of the same atomic unit as the state change. If the key already exists, the handler returns the existing outcome instead of performing another credit.
This is where API design and database design meet. A clean REST or RPC endpoint is not enough if the underlying command can be applied twice. A good external contract should tell clients which operations are idempotent, which identifiers they must provide, and what result they should expect after retries.
Scalability Implications
Transactions are not free. They hold locks, consume database resources, and create contention around hot rows. A wallet row for a very active player, merchant, or account can become a serialization point. Every increment wants to update the same record. At low volume, this is fine. At high volume, it becomes a throughput ceiling.
There are several ways to handle that pressure. One is to keep transactions short. Do not call external payment providers, send emails, or publish slow network requests while holding a database transaction open. Read the minimum data needed, write the state transition, commit, then perform side effects through an outbox or event pipeline.
The transactional outbox pattern is useful here. The application writes business state and an outbound event into the same transaction. A separate relay later publishes the event to Kafka, RabbitMQ, or another broker. This avoids the classic failure where the database commits but the event publish fails, or the event publishes but the database rolls back.
Another approach is to avoid high-contention counters where exact real-time values are not required. Some systems shard counters, batch updates, or compute aggregates asynchronously. That trade-off improves write throughput but weakens immediate consistency. For financial balances, exactness usually wins. For analytics totals, delayed consistency is often acceptable.
Distributed databases add another layer. MongoDB supports multi-document transactions, and systems like CockroachDB expose serializable transactions across ranges and nodes. These tools are powerful, but distributed atomicity has a cost. Coordinating writes across partitions requires more network round trips, more failure handling, and usually more latency than a single-node transaction.
Trade-offs
The main trade-off is not whether atomicity is good. It is where the atomic boundary belongs.
If the boundary is too small, the system persists partial business facts. That creates manual repair work, customer-facing inconsistencies, and audit gaps. If the boundary is too large, the transaction becomes slow and contentious. It may hold locks while doing work that belongs outside the database, reducing throughput and making outages wider.
A pragmatic rule is to put the minimum set of writes that must agree inside the transaction. For the top-up repair case, order status, wallet credit, cumulative amount, and audit record likely belong together. Sending a notification does not. Publishing an event probably should be represented by an outbox row inside the transaction, then delivered after commit.
There is also an operational trade-off. Transactions reduce some classes of inconsistency, but they do not remove the need for reconciliation. Real systems still need audit queries, repair jobs, duplicate detection, and dashboards for stuck workflows. A transaction prevents many bad states. It does not prove every business process completed across every service.
What Changes in Practice
For application developers, the change is to stop thinking of database writes as individual lines of code and start thinking in commands. A command has invariants. A command has retry behavior. A command has a failure boundary. Once that is clear, the transaction becomes an implementation of the business rule rather than a technical wrapper added later.
For API designers, the change is to make retries first-class. Idempotency keys, stable command IDs, unique constraints, and clear response semantics matter as much as endpoint naming. The API should assume that clients, workers, and networks will retry at awkward times.
For system designers, the change is to treat consistency as a budget. Stronger consistency costs latency and coordination. Weaker consistency costs reconciliation and user trust. The right answer depends on the data. Wallet balances, inventory reservations, and account permissions deserve stricter guarantees than profile view counts or analytics summaries.
Atomicity is the small promise that keeps a failed operation from becoming a corrupted operation. In distributed systems, that distinction is expensive to rediscover after production data has already split into competing truths.
Comments
Please log in or register to join the discussion