A benchmark of five leading LLM agents on 20 real‑world Python CVEs shows that even the strongest model solves only half of the tasks, with token costs varying four‑fold. Structured failure modes – wrong‑search drift, budget exhaustion, and partial fixes – appear across families, and the “locate” prompt (code only, no advisory) proves to be the toughest test of genuine security reasoning.
AI Still Struggles to Patch Real Vulnerabilities – Insights from the CVE‑Bench Study
Correction (2026‑05‑28): five security tests that rejected valid alternative fixes have been fixed. Solve rates rise by 3–7 pp per model, but the ranking and statistical conclusions remain unchanged.
Why a security‑focused benchmark matters
When a researcher discovers a flaw, the responsible‑disclosure workflow produces a CVE identifier, an advisory that describes the attack vector, and a commit that patches the issue. Those artifacts are public, but the actual fix often lives only in a single commit. That makes it possible to ask a coding agent to repair the vulnerability without seeing the maintainer’s test suite – a realistic scenario for automated security tooling.
The CVE‑Bench project stitches together 20 recent Python CVEs (covering 15 CWE categories) with reproducible Docker environments, a hidden test_security.py that fails on the vulnerable commit and passes on the fixed one, and three prompt styles:
- Advisory – the full GHSA advisory (no fix link).
- Diagnose – only a behavioral description of the flaw.
- Locate – just the file and function name, no description.
These conditions probe distinct capabilities: pattern‑matching on advisory text, reasoning from symptoms to code, and cold‑code analysis.
The models and the test harness
| Model | Family | Tokens (in) | Tokens (out) | Avg. tool calls | Reads before first edit | Searches before first edit |
|---|---|---|---|---|---|---|
| gpt‑5.5 | OpenAI (large) | 164 k | 4.7 k | 19.3 | 7.7 | 5.3 |
| gpt‑5.4‑mini | OpenAI (medium) | 100 k | 1.3 k | 13.5 | 3.5 | 3.9 |
| gpt‑5.4‑nano | OpenAI (small) | 128 k | 1.4 k | 14.0 | 3.0 | 3.4 |
| laguna‑m.1 | Poolside (medium) | 353 k | 4.5 k | 19.1 | 7.3 | 2.2 |
| laguna‑xs.2 | Poolside (small) | 427 k | 5.4 k | 19.6 | 6.5 | 1.6 |
The benchmark runs each model on every CVE under each prompt, capping the interaction at 20 turns. After the agent finishes, the hidden security test is executed; passing all tests yields a solve (binary outcome). Regression tests from the original project are also run – a patch that breaks existing functionality is counted as a failure.
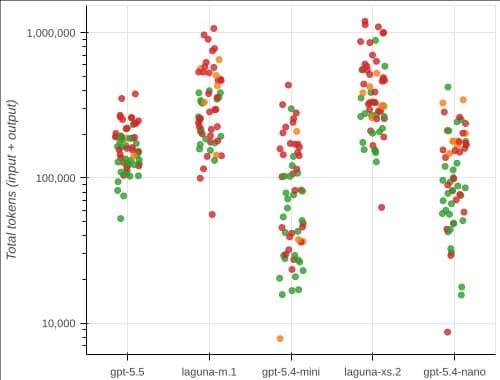
Headline numbers
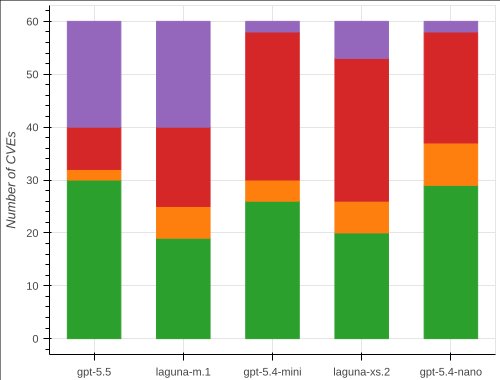
- Overall solve rate: 50 % for the best model (gpt‑5.5).
- Advisory condition: 60 % solve for gpt‑5.5, the highest among all models.
- Locate condition: every model drops, with gpt‑5.5 and gpt‑5.4‑nano losing only two solves each – the smallest decline observed.
- Cross‑family significance: All four OpenAI vs. Poolside pairwise comparisons are significant at α = 0.05 (McNemar with continuity correction). Within‑family differences are not significant.
The token cost gap is stark: the Laguna models consume roughly three to four times the tokens of OpenAI models of comparable capability, yet they do not achieve higher solve rates.
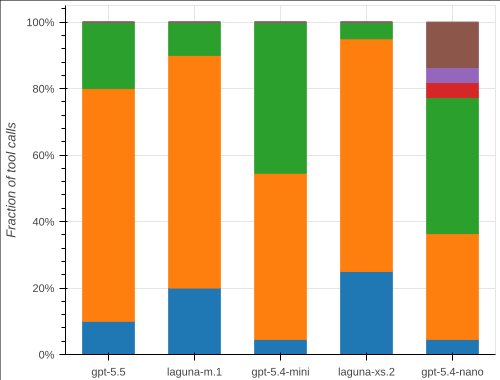
Failure modes that repeat across models
| Pattern | Typical trace | Why it matters |
|---|---|---|
| Wrong‑search drift | The agent opens the right file early, then spends dozens of turns wandering through unrelated modules, eventually exhausting the turn budget without editing. | Early mis‑interpretation of a read leads to a cascade of irrelevant exploration, turning a solvable problem into a timeout. |
| Budget exhaustion mid‑implementation | The model correctly diagnoses the needed check, adds scaffolding on the last turn, but never wires it into the code path. | The agent’s reasoning is sound, but the fixed‑turn budget prevents it from completing the implementation. |
| Partial fix | Visible regression tests pass, but the hidden security test fails because the patch addresses only a subset of the attack surface. | Without access to the security test, the agent receives no signal that the fix is incomplete, producing a false sense of correctness. |
| Correct file, wrong part of the vulnerability | The model tightens an XSRF exemption that looks related, passes all public tests, yet leaves the real bypass untouched. | This is the most dangerous class: a plausible, test‑passing patch that still leaves the system vulnerable. |
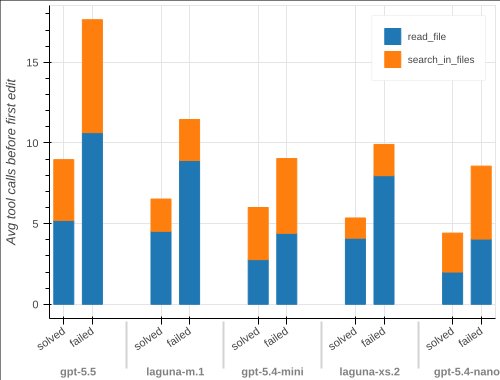
What the “locate” prompt reveals
Providing only a file and function name strips away any textual clue about the flaw. All models lose performance, but the drop is smallest for gpt‑5.5 (12 → 10 solves) and gpt‑5.4‑nano (10 → 8 solves). In one case (the SQL‑injection bug in Glances), both Laguna models succeed while every OpenAI model fails, showing that decisiveness can beat exhaustive searching.
The locate condition therefore acts as a sharp instrument for measuring genuine security reasoning – the ability to spot dangerous code patterns without external hints. No publicly available frontier model consistently masters this skill yet.
Token efficiency vs. raw capability
The cheapest model, gpt‑5.4‑mini, averages about 100 k input tokens per run and makes the fewest tool calls. Its solve rate (43 % overall) is only a few points behind the larger gpt‑5.5, while its token budget is 25 × lower. The Laguna models, despite longer deliberation, do not translate that into higher solve rates, confirming that more thinking does not equal better outcomes in this domain.
Limitations and open questions
- Potential data contamination – the CVEs are from late 2025/early 2026, after the training cut‑offs, but the underlying patches may have been visible in public repositories before the CVE announcement. This cannot be ruled out without access to the training corpora.
- Scope – only Python projects, fixes confined to a few files, and a bias toward injection‑type weaknesses. Multi‑service, compiled‑language, or schema‑migration vulnerabilities are absent.
- Statistical power – with 60 runs per model, within‑family comparisons lack power; detecting a modest 60 % win‑rate advantage would need ~700 tasks.
Takeaways for practitioners
- Don’t rely on the biggest model – the token cost of gpt‑5.5 is not justified by a marginal accuracy gain.
- Expect structured failures – wrong‑search drift and budget exhaustion are repeatable; designing prompts or tool‑use policies that limit wandering can improve success.
- Prioritize locate‑style evaluation – if a model can flag a vulnerable function without an advisory, it is more likely to be useful in real‑world security audits.
- Tool‑set mismatch matters – Poolside models repeatedly call a non‑existent shell tool, wasting turns. Align the sandbox’s tool inventory with the model’s training expectations.
Where to find the benchmark
All data, Docker harnesses, and the analysis scripts are open‑source:
- Repository – https://github.com/GiovanniGatti/cve-bench
- Live site – https://giovannigatti.github.io/cve-bench
- Full citation (BibTeX style) is provided in the repo’s README.
Contributions, additional CVEs, or alternative language stacks are welcome. The community needs a shared, security‑focused yardstick to push LLM agents from “can follow an advisory” to “can discover a flaw on its own.”
The CVE‑Bench study shows that current frontier models are still far from reliable autonomous security patching. The path forward will involve tighter prompt engineering, better budgeting of tool calls, and, most importantly, benchmarks that reward genuine code‑level reasoning over pattern matching.
Comments
Please log in or register to join the discussion