
A researcher used integer linear programming and cutting-plane techniques, the same machinery that cracks hard Traveling Salesman instances, to compute a provably optimal tokenizer for Pride and Prejudice at a vocabulary size of 512. The result is theoretically interesting and practically marginal, and the author is refreshingly upfront about both.
Tokenization is the unglamorous first step in every large language model pipeline, and almost nobody tries to do it optimally. The standard tool, byte-pair encoding (BPE), is a greedy compression algorithm that dates back decades. It works well enough that the question "could we do better?" rarely gets asked, let alone answered. A recent blog post by Alex Nichol takes the question seriously and produces something genuinely uncommon: a provably optimal tokenizer for a real text, computed using techniques borrowed from combinatorial optimization.
The headline result is a tokenizer of vocabulary size 512 that is optimal for the book Pride and Prejudice. "Optimal" here has a precise meaning. Among all possible vocabularies of that size, this one minimizes the total number of tokens needed to encode the training text. That is a strong claim, because the problem is NP-hard in general. The interesting finding is that, like many Traveling Salesman Problem (TSP) instances that are theoretically intractable but routinely solved in practice, this particular tokenization problem turned out to be solvable with the right machinery.
What is actually being computed
Before the optimization, it helps to be clear about what a tokenizer is. LLMs train on sequences of integers called tokens, where each token maps to a sequence of bytes. In the GPT-5 tokenizer, token 290 is the bytes " the" and 6602 is " token", so " the token" encodes as [290, 6602]. The full mapping from tokens to byte sequences is the vocabulary, and it is frozen before training even begins. The goal when building one is to pick a vocabulary of fixed size that compresses a slice of training data into as few tokens as possible.
BPE builds this vocabulary greedily, repeatedly merging the most frequent adjacent pair of tokens. It is fast and it has no optimality guarantee. The work being discussed builds instead on a formulation from Tempus et al. that recasts tokenization as an integer linear program (ILP).
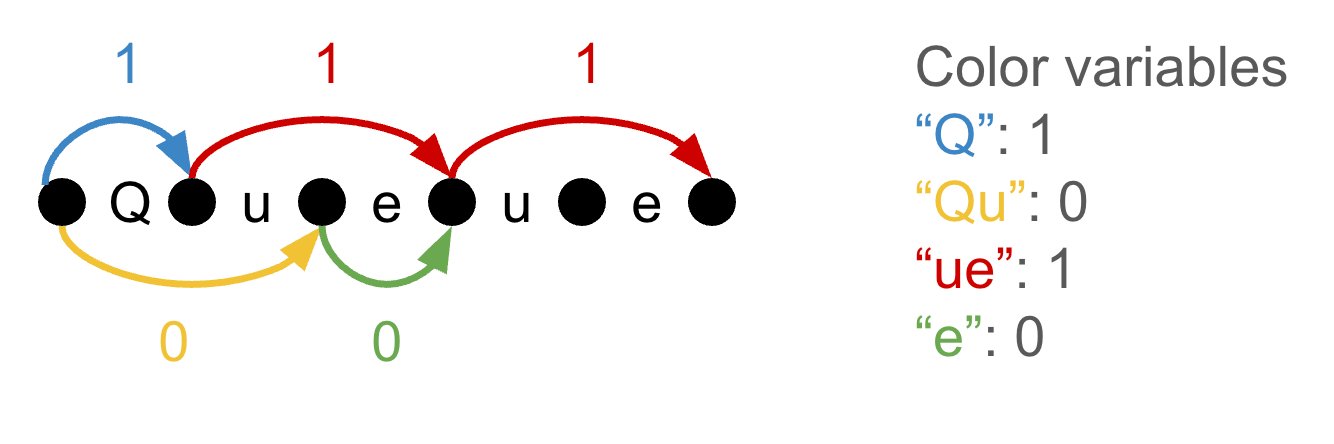
The ILP setup has two kinds of variables. There is a "color" variable for every unique substring in the dataset, set to 1 if that byte sequence is in the vocabulary and 0 otherwise. A single constraint forces the colors to sum to the target vocabulary size. Then, because any given byte sequence can appear many times in the text, there is a separate "edge" variable for each occurrence. The edges encode an actual tokenization: an edge set to 1 means its token is used at that specific position. The objective is to minimize the sum of all edge variables, which is exactly the token count.
Two families of constraints keep the solution honest. First, an edge cannot be used unless its color is in the vocabulary, so each edge variable is constrained to be at most its color variable. Second, flow constraints ensure the text is tokenized in exactly one valid way: at each byte position, the edges flowing in must balance the edges flowing out, except at the start and end of the text.
Why the easy version does not work
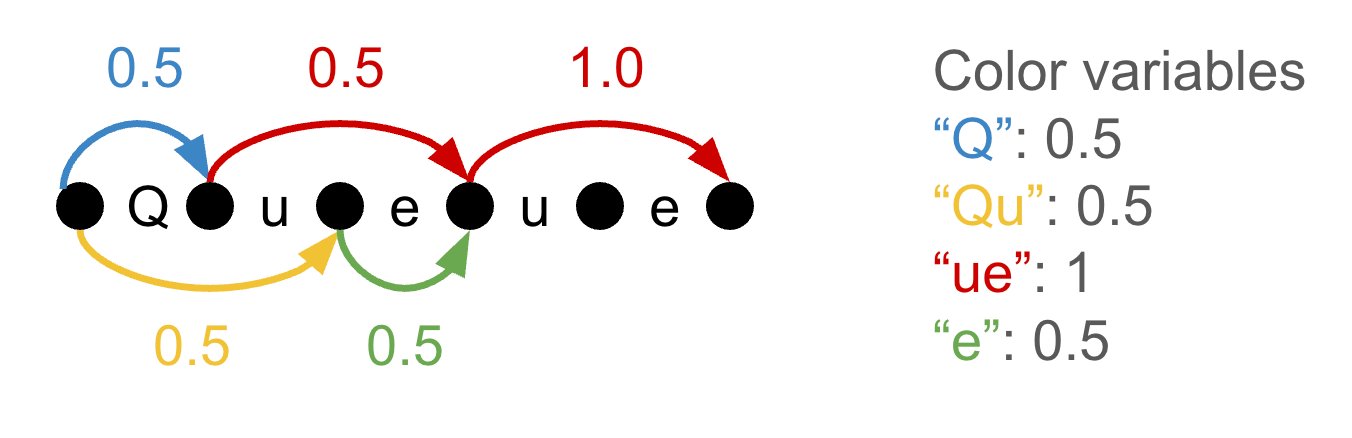
If every variable were forced to be a clean 0 or 1, this ILP would directly yield the optimal tokenizer. The catch is the word "integer." Solving arbitrary integer linear programs efficiently is not possible, so the standard move is to relax the problem: let the variables take any value between 0 and 1 and solve the resulting continuous linear program (LP), which has fast, well-optimized solvers.
The relaxed solution is usually not integral. The post shows an example where the word "Queue" ends up with two superimposed tokenizations, ["Q", "ue", "ue"] and ["Qu", "e", "ue"], each at fractional weight. The color variables sum to 2.5 even though four distinct colors are in play, so this is not a real vocabulary of size 3. Tempus et al. handle this by rounding the fractional colors to get a valid but suboptimal tokenizer. That gives you a sandwich: the continuous LP is a lower bound on the best possible token count, and the rounded tokenizer is an upper bound. If the two numbers do not meet, you do not know you are optimal.
Closing the gap with cutting planes
This is where the TSP connection pays off. The classic way to push an LP relaxation toward an integral answer is to add cutting planes: extra constraints that every valid integer solution satisfies but that the current fractional solution violates. Add enough valid cuts and the lower bound rises to meet the upper bound, pinning down the optimum. The difficulty is that finding useful cuts is creative, problem-specific work. The team behind the Concorde TSP solver wrote an entire book on it.
Rather than derive cut families by hand, the author handed the task to Codex. The first attempts were unimpressive, mostly surface-level word heuristics that barely moved the bound. The breakthrough came from brute force. A cut can be found by building an auxiliary LP with one constraint per integer solution and maximizing the violation of the current fractional point. You cannot do this for the whole problem, since the number of constraints explodes, but you can do it on small projections: pairs or triplets of words that share fractional colors. This found strong cuts but was painfully slow, requiring large auxiliary LPs across enormous numbers of word combinations.
The clever final step was to have Codex inspect the brute-force cuts and reverse-engineer cheaper templates that produce the same kind of constraint. The most effective family, which Codex named "cycle constraints," looks for overlapping fractional edges. If colors A and B conflict, and B and C conflict, and C and A conflict, you can assemble a constraint from those edge and color variables that the continuous LP often violates but no valid integer solution ever does. Finding these cycles reduces to a clean graph problem: make each color a vertex, connect colors whose edges overlap in the current solution, and run depth-first search to find cycles. Codex implemented the whole loop autonomously, which is arguably the more notable part of the story than any single cut.
What this buys you, and what it does not
The author is unusually candid about the limits, which is the right posture for a result like this. The optimal size-512 tokenizer for Pride and Prejudice converged in about a dozen iterations and took a bit over a day on consumer Apple hardware. Bumping the target to 1024 broke the approach: cycle constraints alone were not enough, the lower bound kept moving even after older cut families were added back, and the runs had not finished. There are almost certainly more cut families waiting to be discovered, some of which may be necessary for the harder instances.
There are also three honest reasons the whole exercise may not matter much in practice. First, BPE and the existing rounded solutions are already close to optimal, frequently within about 1 percent. Second, a tokenizer that is optimal on training data may generalize worse on held-out text than a less-tuned alternative, so optimality on the training set is not obviously the right target. Third, and most deflating, an inefficient tokenizer is cheap to fix: you can buy back the lost efficiency by nudging the vocabulary size up a little. When the problem you solved optimally has a trivial workaround, the optimal solution is a curiosity rather than a tool.
A couple of structural caveats are baked into the method as well. To keep the LPs small enough to solve on a CPU, the text is pretretokenized into words and repeated words are merged with weights, which means the solution is only optimal under that pretokenizer. The experiments also drop color variables for substrings appearing fewer than 5 times and cap color length at 16 bytes. Each of these makes the LP tractable while moving the goalposts on what "optimal" strictly means.
The real bottleneck
The most actionable takeaway for anyone wanting to extend this is that the limiting factor is LP solve time, not cleverness about cuts. Individual solves stretched from hours to days, and three different solvers (HiGHS, the one in SCIP, and OR-Tools PDLP) all started to choke on the heavily constrained LPs. The author suspects the cutting-plane process is generating degenerate LPs, which is a known failure mode and a reasonable place to focus. There are no strong GPU-accelerated LP solvers for Apple silicon, so the experiments leaned on HiGHS single-core simplex, which sometimes stalled outright on later iterations.
The open directions are concrete. Scaling to larger corpora will likely demand new cut families. Removing the pretokenizer would make the result cleaner but blows up the LP size, since you lose the ability to merge repeated words, and it breaks the word-based cut strategies that enumerate valid integer tokenizations per word. Reframing those for a single-giant-string dataset is a real research problem on its own.
The hacky implementation is on GitHub, and the author published the optimal Pride and Prejudice vocabulary (actually 510 entries, since the codebase reserves two special tokens). The honest framing throughout is what makes this worth reading: it is a fun, well-executed result that connects two areas cleanly, an example of an AI agent running a full research loop with light supervision, and a problem the author openly admits may not need solving. All three of those can be true at once.
Comments
Please log in or register to join the discussion