
Z.ai’s GLM-5.2 pairs a 51 Intelligence Index score with MIT-licensed open weights, a 1 million-token context window, and higher token use than its closest open-weight peers.

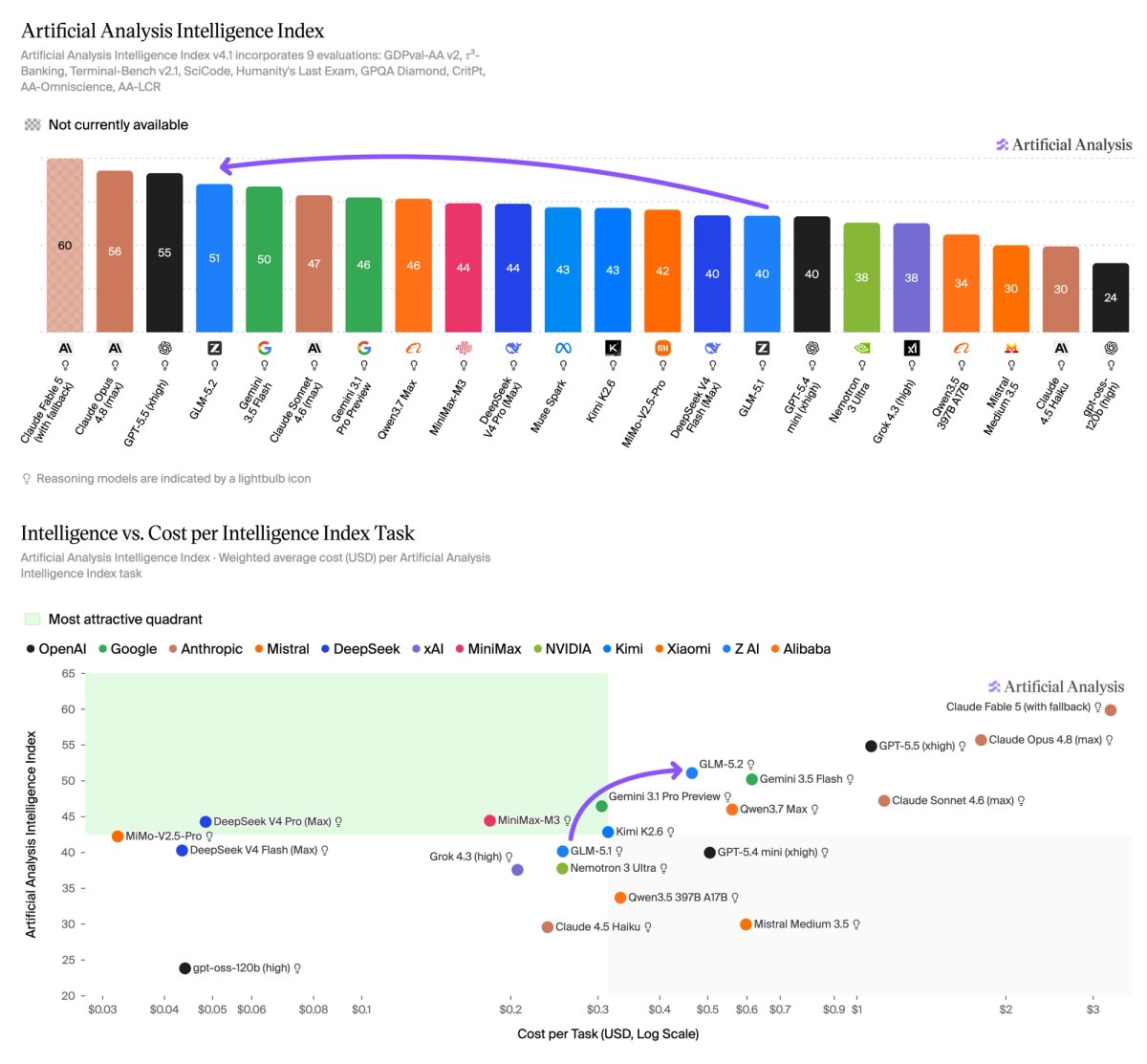
Z.ai’s GLM-5.2 took the top open-weight slot on the Artificial Analysis Intelligence Index v4.1 with a score of 51, ahead of MiniMax-M3, DeepSeek V4 Pro and Kimi K2.6.
Claim
Artificial Analysis ranks GLM-5.2 as the strongest open-weight model in its index. The model uses the same 744 billion total parameters and 40 billion active parameters as GLM-5.1, but it adds 11 points on the Intelligence Index.
That jump puts GLM-5.2 ahead of MiniMax-M3 at 44, DeepSeek V4 Pro max at 44 and Kimi K2.6 at 43. Artificial Analysis also places GLM-5.2 on its Intelligence vs. Cost per Task Pareto frontier, with about $0.46 in cost per task.
Z.ai prices GLM-5.2 through its first-party API at $1.40 per 1 million input tokens, $4.40 per 1 million output tokens and 26 cents per 1 million cache-hit tokens. The company also offers the model through DeepInfra, Novita, Nebius, Parasail, SiliconFlow, GMI Cloud, Baseten and Fireworks.
New results
GLM-5.2 gains across several evaluations that test reasoning, coding and agent work. Artificial Analysis reports a 16-point gain on CritPt to 21%, a 12-point gain on HLE to 40% and a nine-point gain on AA-LCR to 71%.
The model also improves on tau3 banking, up 15 points to 27%, and SciCode, up seven points to 50%. TerminalBench v2.1 rises 16 points to 78%, while GPQA Diamond rises three points to 89%.
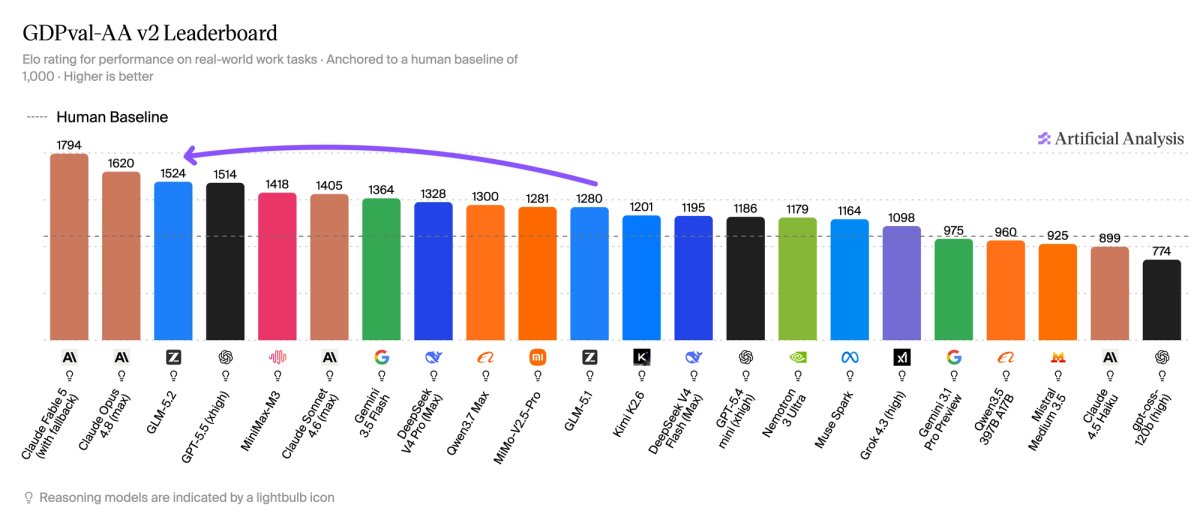
GDPval-AA v2 gives GLM-5.2 its strongest claim. The model scores 1,524, ahead of MiniMax-M3 at 1,418 and DeepSeek V4 Pro max at 1,328. Artificial Analysis says that score puts GLM-5.2 near GPT-5.5 xhigh reasoning, which scores 1,514.
GDPval-AA v2 changes the prior benchmark in ways that suit agent systems. Artificial Analysis bases Elo around human performance at 1,000, uses a rotating panel of frontier-model judges and raises the turn limit from 100 to 250. That longer limit gives models more room to plan, use tools and recover from mistakes.
Architecture and access
Z.ai kept GLM-5.2’s parameter count level with GLM-5.1. The model still uses 744 billion total parameters with 40 billion active parameters, a mixture-of-experts profile that lets Z.ai serve a large model without activating the full network for each token.
The context window grows from 200,000 tokens on GLM-5.1 to 1 million tokens on GLM-5.2. That change gives developers more space for long documents, codebases and agent traces. A larger window can help retrieval-light workflows, though long-context accuracy still depends on how the model uses distant evidence.
Z.ai released GLM-5.2 under the MIT license. That license gives companies and researchers broad room to run, modify and distribute the model, subject to the license terms.
Limits
GLM-5.2 spends more tokens than its open-weight peers. Artificial Analysis says the model uses 43,000 output tokens per Intelligence Index task, including 37,000 reasoning tokens. GLM-5.1 used 26,000 output tokens. MiniMax-M3 uses 24,000, Kimi K2.6 uses 35,000 and DeepSeek V4 Pro max uses 37,000.
That token profile raises cost and latency for agent workloads. GLM-5.2 costs about $0.46 per task, compared with 25 cents for GLM-5.1, 31 cents for Kimi K2.6, 18 cents for MiniMax-M3 and five cents for DeepSeek V4 Pro max.
The benchmark also shows mixed behavior on hallucination. GLM-5.2 improves its AA-Omniscience Index score from two to four, with accuracy rising from 24.2% to 25.1% and hallucination rate falling from 29.4% to 28.1%. The attempt rate stays at 47%.
Those numbers mark progress, but they also show the trade-off. GLM-5.2 attempts fewer than half of the omniscience questions and still hallucinates on more than one-quarter of evaluated attempts. Teams that use the model for research, finance, law or medicine still need retrieval, citations and review.
Developer takeaway
GLM-5.2 gives open-weight users a stronger option for agent work, science reasoning and long-context tasks. The MIT license and broad provider support make deployment easier than closed models with similar benchmark scores.
The main cost sits in output tokens. Developers who run multi-step agents should test GLM-5.2 against MiniMax-M3, Kimi K2.6 and DeepSeek V4 Pro on their own traces, using task success, latency and token spend as the deciding metrics.
The index result gives Z.ai a clear open-weight lead for now. The harder question for production teams concerns efficiency: GLM-5.2 earns its score with long reasoning traces, and that extra reasoning may pay off only on tasks that need it.
Comments
Please log in or register to join the discussion