
Google DeepMind's Aletheia AI has achieved breakthrough performance in fully autonomous mathematical problem-solving, solving 6 out of 10 novel research-level problems without human intervention.
Google DeepMind has unveiled Aletheia, an AI system that represents a significant leap forward in autonomous mathematical research. Built on the Gemini 3 Deep Think architecture, Aletheia tackled the FirstProof challenge—a set of ten unpublished, research-level mathematical lemmas—achieving a remarkable 6/10 success rate with solutions deemed "publishable after minor revisions" by expert human evaluators.

A New Standard for Mathematical AI
What makes Aletheia particularly noteworthy is its approach to the FirstProof challenge. Unlike traditional AI benchmarks that often suffer from data contamination—where models inadvertently memorize training data—these problems were sourced from ongoing mathematical research and had never been posted online. This ensures the AI couldn't have seen them before, making the achievement genuinely novel.
The system operated in strict zero-shot mode, receiving only raw problem prompts without human hints or dialogue loops. This autonomous approach produced candidate proofs completely independently, with expert evaluators judging 6 of the 10 proposed solutions as publishable after minor revisions. Notably, the solution for Problem 8 was judged correct by 5 out of 7 experts, with the remaining two citing a lack of clarifying details.
Reliability Over Raw Capability
Perhaps most impressively, Aletheia demonstrated sophisticated self-awareness by explicitly outputting "No solution found" or timing out for the remaining 4 problems, rather than hallucinating convincing but flawed answers. This self-filtering capability was a key design principle, with DeepMind researchers noting: "We view reliability as the primary bottleneck to scaling up AI assistance on research mathematics. We suspect that many practicing researchers would prefer to trade raw problem-solving capability for increased accuracy."
This approach contrasts sharply with OpenAI's attempt at the same challenge. While OpenAI initially reported solving 6 of the 10 problems, their solution to Problem 2 was later found to be logically flawed, reducing their count to 5. Unlike DeepMind's strict automation, OpenAI acknowledged relying on limited human supervision to manually evaluate and select the best outputs from multiple attempts.
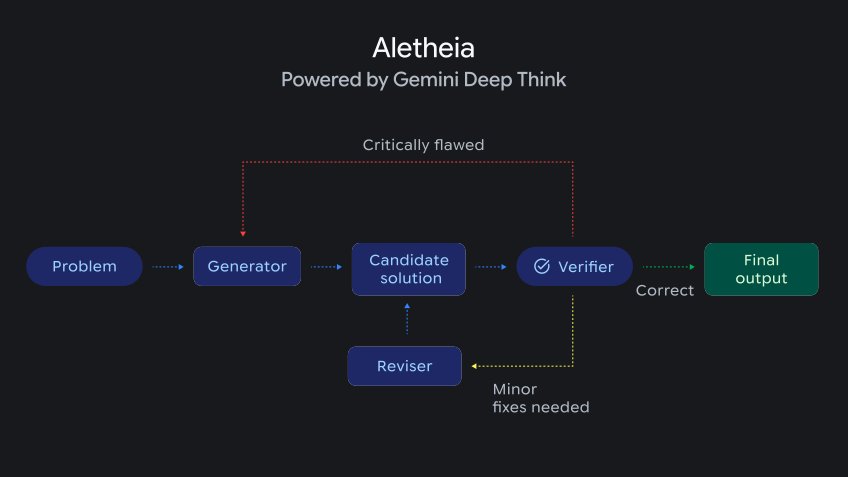
The Multi-Agent Architecture
Under the hood, Aletheia leverages the Gemini 3 Deep Think architecture, relying on extended "test-time compute" (inference time). The system employs a sophisticated multi-agent framework:
- Generator: Proposes logical steps and potential solutions
- Verifier: Evaluates each step for logical flaws and inconsistencies
- Reviser: Iterates and patches mistakes based on verification feedback
This architecture integrates external tools like Google Search, allowing the agent to navigate existing literature to verify concepts and avoid the unfounded citations that typically plague large language models. As Luhui Dev observed in a deep dive, Aletheia functions as a strict, runnable research loop—similar to a CI/CD pipeline for mathematics: propose, verify, fail, repair, and merge.
The LLM acts as a creative candidate generator, while a second agent serves as a peer reviewer to drive remediation. This separation of concerns enables more reliable mathematical reasoning than monolithic approaches.
The Path to Full Autonomy
Despite these impressive achievements, researchers acknowledge that full autonomy remains a work in progress. In the paper "Towards Autonomous Mathematics Research," they note that while progress has been significant over just a few months, challenges persist: "Even with its verifier mechanism, Aletheia is still more prone to errors than human experts. Furthermore, whenever there is room for ambiguity, the model exhibits a tendency to misinterpret the question in a way that is easiest to answer… This aligns with the well-known tendencies for 'specification gaming' and 'reward hacking' in machine learning."
These limitations highlight the complexity of mathematical reasoning and the gap that still exists between AI and human expertise. The tendency to misinterpret ambiguous questions in the easiest-to-answer way demonstrates that Aletheia, while impressive, still lacks the nuanced understanding that human mathematicians bring to problem-solving.
The Future of Mathematical Research
The mathematicians behind the initiative are already working on its second iteration. A new batch of problems will be created, tested, and graded from March to June 2026, designed this time as a fully formal benchmark. This evolution suggests that the field is rapidly advancing, with each iteration pushing the boundaries of what's possible in autonomous mathematical research.
Aletheia's performance on IMO-ProofBench—scoring approximately 91.9%—further demonstrates its capabilities in formal mathematical reasoning. This benchmark, focused on International Mathematical Olympiad-style proofs, provides another rigorous test of the system's abilities.
Implications for the Field
The development of Aletheia has significant implications for mathematical research and AI development more broadly. By demonstrating that AI can contribute meaningfully to research-level mathematics without human intervention, it opens new possibilities for accelerating mathematical discovery and education.
For researchers, tools like Aletheia could serve as powerful assistants, handling routine proof verification and exploration while humans focus on creative problem formulation and interpretation. The system's reliability-first approach suggests a future where AI augments rather than replaces human mathematicians, handling the mechanical aspects of proof construction while leaving the creative insights to human experts.
As the field continues to evolve, the balance between capability and reliability will likely remain a central concern. Aletheia's success in prioritizing accuracy over raw problem-solving ability may set a precedent for future AI systems in domains where correctness is paramount.
The progress represented by Aletheia marks a significant milestone in the journey toward autonomous AI research assistants. While full autonomy remains elusive, the system demonstrates that AI can already contribute meaningfully to cutting-edge mathematical research, potentially transforming how mathematical discoveries are made in the coming years.
Comments
Please log in or register to join the discussion