
Google's 8th-generation TPUs split into specialized inference (8i) and training (8t) variants, featuring improved performance, Arm-based CPUs, and hierarchical scaling capabilities.
Google TPU 8i and TPU 8t: A Deep Dive into Google's Latest AI Accelerators
Google has officially announced its 8th-generation Tensor Processing Units (TPUs), marking a significant evolution in the company's custom silicon strategy for AI workloads. The new generation splits into two distinct variants: the TPU 8i optimized for inference workloads and the TPU 8t designed for large-scale training. This specialization represents Google's continued investment in custom accelerators while acknowledging the different requirements of inference versus training in modern AI deployments.

The Strategic Split: Why Inference and Training Need Different Hardware
Google's decision to create separate TPU variants for inference and training reflects a deeper understanding of workload-specific optimization requirements. Inference workloads prioritize low latency, high throughput, and power efficiency, while training demands massive computational capacity, high memory bandwidth, and efficient scaling across thousands of accelerators.
The TPU 8i targets production inference deployments with claims of significant performance-per-watt improvements over previous generations. Meanwhile, the TPU 8t focuses on scaling training performance to meet the demands of increasingly large frontier models. This specialization allows Google to optimize each architecture for its specific workload rather than maintaining a one-size-fits-all approach.
TPU 8i: Inference-Focused Architecture
The TPU 8i introduces several architectural refinements specifically designed for inference efficiency. At its core, Google claims improved sparsity support and enhanced matrix multiplication units optimized for common inference patterns, particularly transformer-based models that dominate modern AI applications.
Precision Support and Matrix Operations
The TPU 8i supports multiple precision formats, with particular emphasis on INT8 and FP8 operations common in production inference deployments. These lower precision formats enable higher throughput and better power efficiency compared to the FP32 precision traditionally used in training.
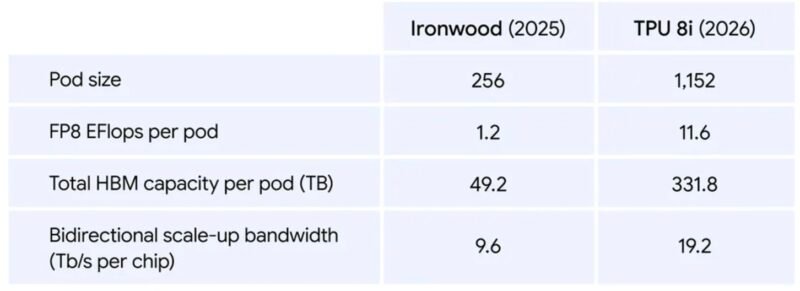
Google TPU 8i Performance Comparison Versus Ironwood
The matrix multiplication units have been redesigned to handle the specific patterns common in inference workloads, where models are often run repeatedly with the same architecture but different inputs. This optimization allows the TPU 8i to achieve higher effective throughput for these repetitive operations.
Boardfly Hierarchical Network Topology
A key architectural improvement in the TPU 8i is the incorporation of Google's Boardfly hierarchical network topology. This topology enables efficient scaling from individual boards to large multi-rack configurations, supporting up to 1,152 chips organized into 36 groups across 8 boards.
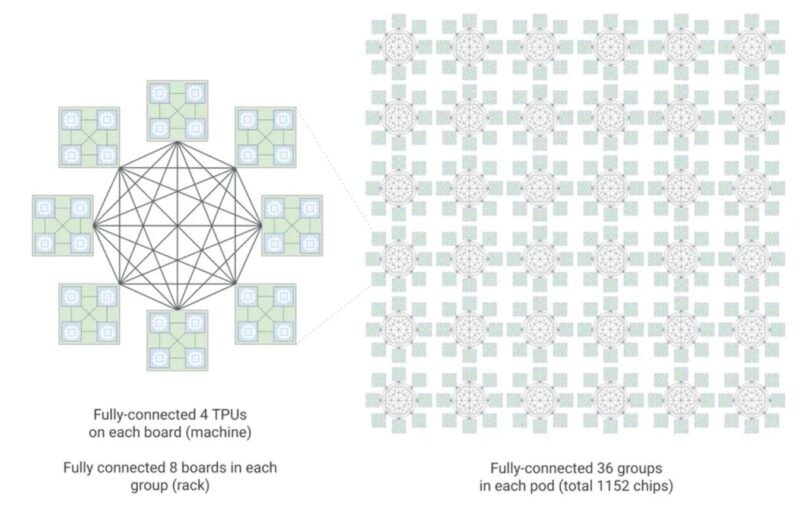
Google TPU 8i Hierarchical Boardfly Topology From 8 Boards To 36 Groups For 1152 Chips
This hierarchical organization is critical for distributed inference workloads, as it facilitates efficient all-reduce operations that coordinate computations across multiple accelerators. The topology minimizes communication overhead by organizing chips into increasingly larger groups, allowing for efficient scaling without the linear increase in latency that typically affects distributed systems.
Axion Arm-Based Integration
Perhaps the most significant architectural change in the TPU 8i platform is the integration of Google's Axion Arm-based CPUs for host processing. The platform maintains a 2:1 TPU-to-CPU ratio, meaning each TPU chip is paired with two Arm-based cores for control tasks and data preprocessing.

Google Axion ARM CPU
This represents a major departure from previous generations, which relied on x86 CPUs for host processing. The switch to Arm architecture provides several advantages:
- Power Efficiency: Arm cores typically offer better performance-per-watt than x86 equivalents
- Integration: Custom Arm designs can be more tightly integrated with the TPU accelerators
- Vertical Integration: Allows Google to control more of the silicon stack
The Axion CPU likely incorporates custom extensions optimized for TPU-specific operations, further reducing the overhead between host processing and accelerator computation.
TPU 8t: Training at Scale
While the TPU 8i focuses on inference efficiency, the TPU 8t addresses the growing demands of large-scale AI model training. The 8t generation scales training performance by increasing compute density and enhancing interconnect bandwidth to support the massive communication requirements of distributed training.
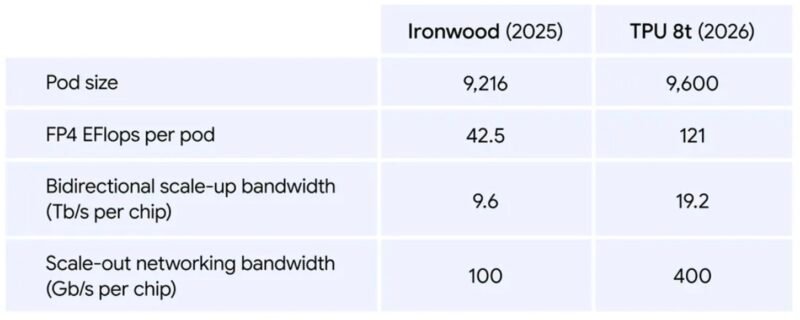
Google TPU 8t Performance Comparison Versus Ironwood
Compute Density and Interconnect Improvements
The TPU 8t builds directly on the Ironwood (TPU v7) architecture, which introduced expanded precision support and broader cloud availability. The 8t extends these capabilities with improved efficiency metrics and larger pod configurations designed for frontier model training requirements.
Key improvements include:
- Higher memory bandwidth to feed the compute cores with training data
- Enhanced interconnect bandwidth to support the all-reduce operations critical for distributed training
- Increased compute density to maximize the number of operations per second per rack unit
Pod-Scale Deployments
Like its predecessors, the TPU 8t supports pod-scale deployments where thousands of chips operate as a unified training fabric. Google's hierarchical network topology enables scaling across multiple rack boundaries while maintaining efficient all-reduce operations.
This capability is essential for training the largest AI models, which may require coordination across thousands of accelerators. The efficiency of these all-reduce operations directly impacts training time and cost, making this architectural optimization critical for large-scale deployments.
Performance Benchmarks and Efficiency Metrics
While Google hasn't published detailed benchmark data comparing the TPU 8i and 8t against previous generations or competitors, we can analyze the architectural improvements to understand potential performance gains.
TPU 8i Inference Performance
The TPU 8i's focus on inference efficiency suggests significant gains in:
- Throughput: Higher operations per second for INT8/FP8 workloads
- Latency: Reduced time-to-first-token for interactive applications
- Power Efficiency: Better performance-per-watt for production deployments
The improved sparsity support could provide substantial performance improvements for models that leverage sparse activations or weights, which is increasingly common in optimized inference deployments.
TPU 8t Training Performance
For training workloads, the TPU 8t likely offers:
- Scaling Efficiency: Better performance when scaling to larger pod configurations
- Memory Bandwidth: Higher throughput for feeding massive datasets to compute cores
- Precision Support: Enhanced capabilities for mixed-precision training techniques
The hierarchical network topology should provide better communication efficiency at scale, reducing the overhead of coordinating thousands of accelerators during training.
Comparison with Previous Generations
The TPU 8i and 8t represent the eighth generation of Google's custom accelerators, building on a lineage that has evolved from inference-only designs to full training capability with pod-scale networking.
- TPU v6 (Pike): Focused on inference with improved matrix multiplication units
- TPU v6.2 (Skylark): Added support for larger models and improved memory
- TPU v7 (Ironwood): Expanded precision support and cloud availability
- TPU v8i/v8t: Specialized inference and training variants with hierarchical scaling
Each generation has brought improvements in compute density, memory bandwidth, and interconnect efficiency, with the current generation continuing this trend while introducing the specialization between inference and training workloads.
Competitive Landscape: TPUs vs. NVIDIA GPUs
Despite Google's continued investment in TPUs, NVIDIA maintains a dominant position in the AI accelerator market. The key differences between the platforms include:
Market Position
TPUs remain primarily deployed within Google's infrastructure and offered through Google Cloud. Unlike NVIDIA's broad ecosystem spanning enterprise, cloud, workstation, and edge deployments, TPUs serve a narrower market segment.
This focused approach enables optimization for specific workloads but limits general applicability. NVIDIA's CUDA ecosystem has become the de facto standard for AI development, with extensive software support and broad hardware availability across multiple cloud providers.
Performance Characteristics
While detailed benchmarks comparing TPU 8i/8t with NVIDIA's latest GPUs aren't yet available, we can consider the general performance characteristics:
- TPUs: Excel at matrix operations with high memory bandwidth, particularly for models that fit within their memory constraints
- GPUs: Offer more general-purpose compute capabilities with a mature software ecosystem
The coexistence of TPU deployments with significant NVIDIA Vera purchases suggests that TPUs complement rather than replace general-purpose accelerators. Google remains a major NVIDIA customer despite years of TPU development, purchasing NVIDIA GPU accelerators at scale for workloads where CUDA ecosystem compatibility or specific hardware capabilities are required.
Build Recommendations and Practical Considerations
For organizations considering TPU-based deployments, several factors should inform the decision between TPU 8i and TPU 8t:
When to Choose TPU 8i
The TPU 8i is ideal for:
- Production inference workloads with high request volumes
- Transformer-based models optimized for INT8/FP8 precision
- Deployments where power efficiency is a critical concern
- Workloads that can benefit from improved sparsity support
When to Choose TPU 8t
The TPU 8t is better suited for:
- Large-scale model training requiring thousands of accelerators
- Research institutions developing frontier AI models
- Organizations already invested in Google's cloud infrastructure
- Workloads that benefit from pod-scale deployment efficiency
Integration Considerations
Organizations should consider the following when integrating TPUs:
- Software Stack: TPU development typically requires TensorFlow integration, though PyTorch support has improved
- Cloud Dependency: TPUs are most accessible through Google Cloud, with limited on-premises options
- Ecosystem Maturity: The TPU ecosystem is less mature than NVIDIA's CUDA, with fewer third-party tools and libraries
- Cost Structure: TPU pricing can be complex, with different models for training vs. inference workloads
The Future of Custom AI Accelerators
Google's TPU program has evolved through multiple generations, expanding from inference-only designs to full training capability with pod-scale networking. The current generation's specialization between inference and training workloads reflects a maturing understanding of the distinct requirements of these AI tasks.
Like NVIDIA, Google is utilizing a 2:1 accelerator to Arm CPU design in this generation, though Google's implementation is more tightly integrated vertically. This approach contrasts with NVIDIA's strategy of offering discrete GPUs that can pair with various CPU architectures.
For homelab builders and small-scale AI practitioners, TPUs remain largely inaccessible due to their cloud-only deployment model and minimum scale requirements. However, the architectural innovations developed for TPUs often influence the broader AI accelerator market, with concepts like specialized precision support and hierarchical network topology eventually finding their way into more accessible hardware.
Conclusion
Google's TPU 8i and TPU 8t represent the company's continued investment in custom accelerator architecture optimized for specific AI workloads. The inference-focused 8i targets production deployment efficiency with improved sparsity support and matrix multiplication units, while the training-oriented 8t scales to frontier model requirements with enhanced interconnect bandwidth.
The introduction of Axion Arm-based CPUs at a 2:1 TPU-to-CPU ratio represents a significant architectural shift that could improve power efficiency and integration. Meanwhile, the Boardfly hierarchical network topology enables efficient pod-scale operations for both inference and training workloads.
Despite these innovations, TPUs remain primarily accessible through Google Cloud and complement rather than replace NVIDIA's GPU offerings. For organizations deeply integrated with Google's cloud infrastructure, TPUs offer a specialized solution for certain AI workloads. For the broader market, however, NVIDIA's more general-purpose accelerators with mature software ecosystems continue to dominate.
As AI models grow larger and more complex, the distinctions between inference and training hardware will likely become more pronounced. Google's split approach with the TPU 8i and 8t may represent the future of AI acceleration, with specialized hardware designed for specific stages of the AI lifecycle.
For more information on Google's TPU offerings, visit the official Google Cloud TPU documentation and research papers detailing the architecture innovations.
Comments
Please log in or register to join the discussion