
AI
Ubuntu Shifts to On‑Device AI with Inference Snaps
5/16/2026

Startups
DeepInfra Raises $107M to Expand Open-Model Inference Cloud Platform
5/5/2026

LLMs
Evaluating and Optimizing LLM Performance: A Practical Guide
4/29/2026

Chips
Google's TPU 8t and 8i: Specialized Chips for the Agentic Era
4/23/2026

Hardware
Google TPU 8i and TPU 8t: A Deep Dive into Google's Latest AI Accelerators
4/23/2026

Machine Learning
Visualizing Mixture of Experts: Inside the Black Box of Modern AI Models
4/13/2026

AI
TurboQuant is a big deal, but it won't end the memory crunch • The Register
4/2/2026

Chips
Meta Accelerates AI Chip Development: Four New MTIA Generations Planned by 2027
3/13/2026

Chips
Meta Accelerates AI Hardware Roadmap with MTIA 400/450/500 Generations
3/13/2026
AI
Enterprise LLM Inference: The Capital Allocation Problem You Can't Ignore
3/3/2026
Machine Learning
Timber: AOT Compiling Classical ML Models to Native C for Microsecond Inference
3/2/2026
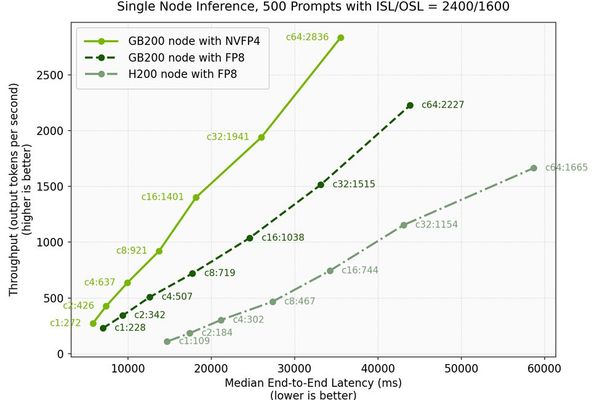
Hardware
Microsoft and NVIDIA Achieve Breakthrough DeepSeek-V3.2 Inference Performance with Blackwell Platform
2/28/2026

Hardware
SambaNova Unveils SN50 AI Accelerator, Partners with Intel for Xeon-Based Inference Infrastructure
2/25/2026