
Meta unveils ambitious MTIA accelerator roadmap spanning four generations, featuring massive performance gains through modular chiplet design and inference-focused optimizations.
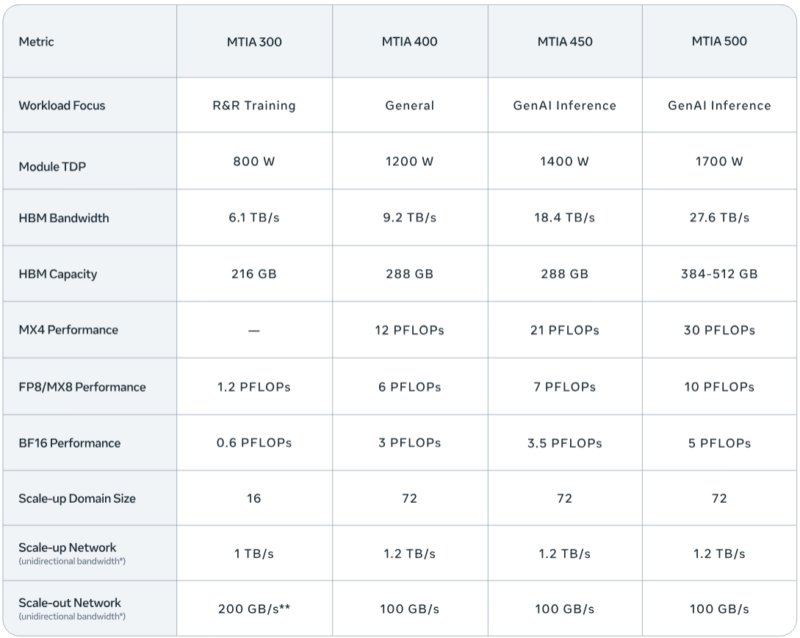
Meta is accelerating its custom AI hardware development with a comprehensive roadmap spanning four new generations of its Meta Training and Inference Accelerator (MTIA) family. The company's latest announcement details the MTIA 400, 450, and 500 accelerators, along with continued production of the MTIA 300, representing a significant evolution in Meta's approach to powering its massive AI infrastructure.

From Ranking to Generative AI: The MTIA Evolution
The MTIA family began with the MTIA 300, which Meta initially optimized for ranking and recommendation models - workloads that dominated Meta's infrastructure before the generative AI boom. This first-generation accelerator established the foundational building blocks that would inform subsequent designs. Currently in production for ranking and recommendation training, the MTIA 300 represents Meta's initial foray into custom silicon for AI workloads.
As generative AI surged in popularity and demand, Meta recognized the need for more powerful and specialized hardware. The MTIA 400 succeeds the 300 series, offering over five times the compute performance and 50% more HBM memory bandwidth. This generational leap also dramatically expands scale-up capabilities, increasing from a 16-node limit on MTIA 300 to 72 nodes on MTIA 400. Meta has completed testing of the MTIA 400 and is preparing for data center deployment.
Modular Chiplet Design Philosophy
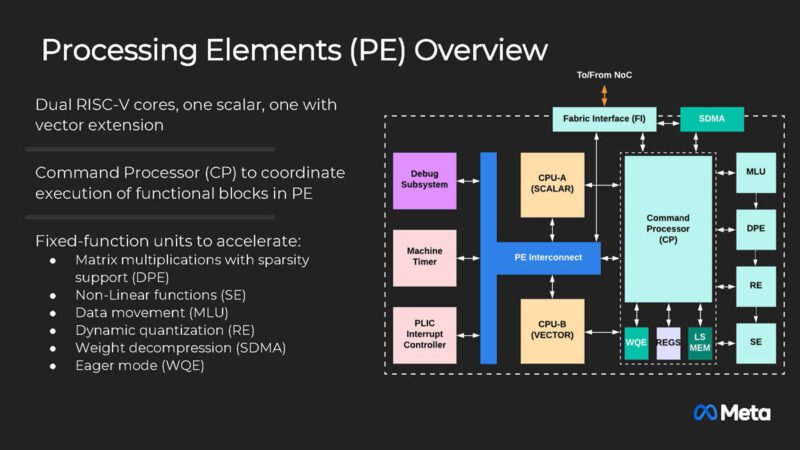
Meta's approach to AI accelerator development centers on modular chiplets and common building blocks. Each processing element within the MTIA architecture contains multiple specialized components: two RISC-V vector cores, a Dot Product Engine for matrix multiplication, a Special Function Unit for activations and elementwise operations, a Reduction Engine for accumulation and inter-PE communication, and a DMA engine for data movement.
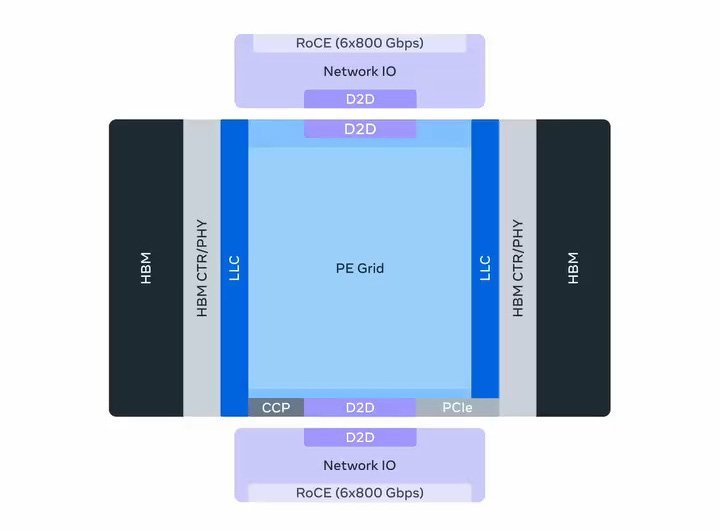
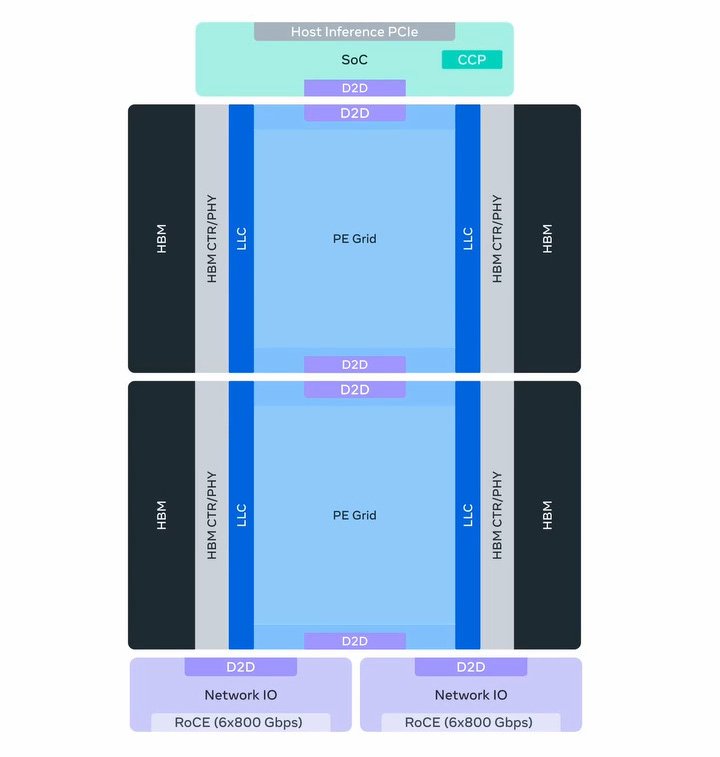
This modular philosophy becomes even more pronounced in the MTIA 500, which employs a two-by-two configuration of smaller compute chiplets. These chiplets are surrounded by HBM stacks, network chiplets, and an SoC chiplet providing PCIe connectivity. This approach allows Meta to rapidly iterate on designs while maintaining compatibility across generations.
Inference-Focused Optimizations
While many companies concentrate on training-focused hardware, Meta has strategically chosen to optimize for inference workloads. This decision aligns with Meta's specific needs, as the company believes using hardware highly optimized for their particular workloads provides a competitive advantage over repurposing training hardware for inference tasks.
This inference-centric approach is evident in the MTIA 450, scheduled for mass deployment in early 2027. Recognizing that HBM bandwidth is the most critical factor affecting generative AI inference performance, Meta doubled the bandwidth from MTIA 400 to 450, increasing from 9.2TB/sec per accelerator to 18.4TB/sec. This gives MTIA 450 significantly more memory bandwidth than existing commercial products. The 450 series also improves support for low-precision data types, including some Meta custom data types.
The MTIA 500: Pushing Boundaries Further
The MTIA 500 continues Meta's focus on generative AI inference, representing the most ambitious design in the roadmap. Compared to the MTIA 450, the 500 series will increase HBM bandwidth by an additional 50 percent, reaching 27.6TB/sec. HBM capacities will reach as high as 512GB per accelerator, contingent on HBM development progress.
The 500 series also promises "data-type innovations" that Meta isn't detailing at this time, suggesting further architectural optimizations beyond raw performance increases. With mass deployment scheduled for 2027, the MTIA 500 represents Meta's vision for next-generation AI inference capabilities.
Performance Trajectory and Deployment Strategy
Across the complete arc from MTIA 300 to MTIA 500, Meta projects HBM bandwidth will increase by four and a half times, while compute FLOPS will increase by 25 times when accounting for lower precision data types. This rapid advancement validates Meta's "velocity strategy," enabling the development of multiple successive generations in just a couple of years.
Meta's deployment strategy leverages common rack and network infrastructure across the MTIA 400, 450, and 500 generations. This standardization allows Meta to quickly swap out accelerators as newer, more powerful chips become available, ensuring their infrastructure remains state-of-the-art without requiring complete system overhauls.
Software Ecosystem and Industry Standards
The MTIA platform is built natively on industry-standard software ecosystems, including PyTorch, vLLM, and Triton. Meta also follows Open Compute Project standards for hardware, ensuring compatibility and ease of integration with existing infrastructure. This approach balances custom optimization with software ecosystem compatibility, avoiding the pitfalls of completely proprietary solutions.
Strategic Implications for AI Infrastructure
Meta's MTIA roadmap demonstrates that there are multiple viable paths forward in AI acceleration. While many companies focus on building the largest possible chips for training, Meta has found success with a different strategy: building inference-optimized chips while rapidly iterating on chip design.
The use of RISC-V architecture and modular chiplet design shows innovation beyond traditional GPU approaches. With hundreds of thousands of MTIA chips already deployed in production, Meta is successfully using custom silicon to deliver both performance and cost efficiency at massive scale.
This strategy allows Meta to maintain control over its AI infrastructure costs while ensuring the hardware is precisely tuned to its specific workload requirements. As AI models continue to evolve rapidly, Meta's ability to iterate quickly on hardware design may prove to be a significant competitive advantage in the ongoing race to deliver the best AI-powered experiences to users.
Comments
Please log in or register to join the discussion