Microsoft and NVIDIA have achieved up to 2.5x lower latency and 16x more users per GPU for DeepSeek-V3.2 inference using NVIDIA's new NVFP4 precision format on the Blackwell GB200 platform, marking a significant advancement in large language model serving efficiency.
Microsoft and NVIDIA have announced a breakthrough in large language model inference performance, achieving up to 2.5x lower per-user latency and the ability to serve up to 16 times more users per GPU for DeepSeek-V3.2 using NVIDIA's new NVFP4 precision format on the Blackwell GB200 platform.
The collaboration focused on optimizing inference for DeepSeek-V3.2, a 690-billion-parameter Mixture-of-Experts (MoE) model, on single nodes of the NVIDIA GB200 NVL72 platform. Each node consists of 2 Grace CPUs and 4 Blackwell GPUs, comparable to the Standard_ND128isr_NDR_GB200_v6 VM available on Azure.
Breakthrough Performance Achieved
Using an aligned apples-to-apples benchmark methodology, the team demonstrated that single-node inference using NVIDIA GB200 nodes with NVFP4 and TensorRT LLM delivers up to 2.5x lower per-user latency than similar inference configurations with NVIDIA H200 GPUs.
Beyond increased performance, using NVIDIA GB200 nodes with NVFP4 dramatically increases the number of users which can be served from the same GPU footprint as an H200 deployment. While maintaining a consistent latency target across both GB200 and H200 deployments, experiments showed that single-node deployments of DeepSeek-V3.2 can serve up to 16 times as many users per GPU when using NVIDIA GB200 nodes versus NVIDIA H200 nodes.
Three-Layer Optimization Approach
The breakthrough results came from end-to-end co-optimization across three layers:
Hardware: Experiments were performed on individual nodes of the NVIDIA GB200 NVL72, with each node consisting of 2 Grace CPUs and 4 Blackwell GPUs.
Model weights: NVFP4-quantized weights for DeepSeek-V3.2 are optimized to deliver high inference efficiency while preserving model quality.
Inference runtime: TensorRT LLM was used as the production-grade serving and execution engine, configured to optimize DeepSeek on Blackwell GPUs.
NVFP4: The Key Innovation
NVFP4 is an innovative 4-bit floating point format introduced with the NVIDIA Blackwell architecture. By encoding quantized blocks with non-power-of-two scaling factors, NVFP4 simultaneously enables higher performance, reduced memory footprint, and preserved model accuracy when compared with FP8 and FP16 floating point formats.
For DeepSeek-V3.2, NVIDIA's NVFP4 quantization reduced the memory footprint of the model by 1.7x compared to the model's original FP8 format (415 GB vs. 690 GB), leading to significant boosts in throughput and cost savings.
NVIDIA has published comprehensive quality benchmarking results for the DeepSeek-V3.2 NVFP4 model, showing that the quantized weights maintain accuracy closely aligned with the original FP8 model across a broad set of industry-standard benchmarks:
| Precision | MMLU Pro | GPQA Diamond | LiveCodeBench V6 | SciCode | AIME 2025 |
|---|---|---|---|---|---|
| FP8 | 0.802 | 0.849 | 0.756 | 0.391 | 0.934 |
| NVFP4 | 0.799 | 0.835 | 0.756 | 0.401 | 0.923 |
Across reasoning, coding, and scientific benchmarks, NVFP4 delivers near-parity results relative to FP8, validating its suitability for production inference where memory efficiency and throughput are critical.
TensorRT LLM Optimization
TensorRT LLM, an open-source library used for optimizing LLM inference, provides high-performance optimizations for NVIDIA GPUs such as low-precision serving, in-flight batching, custom attention kernels, and much more. Its optimized support for sparse attention and large context windows enables DeepSeek-V3.2 to achieve breakthrough performance.
Benchmark Methodology
The team utilized a fair and practical benchmark methodology, reflecting production-style inference patterns. Although multi-node inference is anticipated to deliver higher per-GPU performance, the focus was on isolating experiments to single-node performance to ensure a clear comparison between the two platforms.
| Parameter | Value |
|---|---|
| Input length | 2,400 tokens |
| Output length | 1,600 tokens |
| Concurrent Requests | 1, 2, 4, 8, 16, 32, 64 |
| Dataset | ShareGPT_V3_unfiltered_cleaned_split |
| Target Metrics | Output Throughput (tokens/sec), End-to-End Latency (ms) |
Performance Results
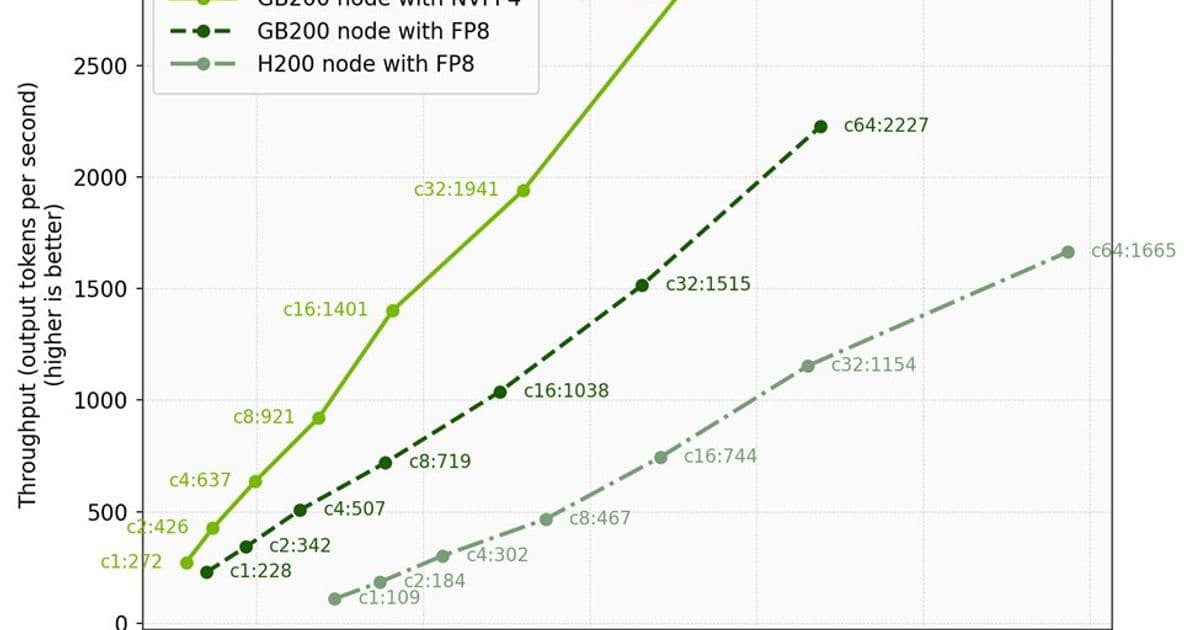
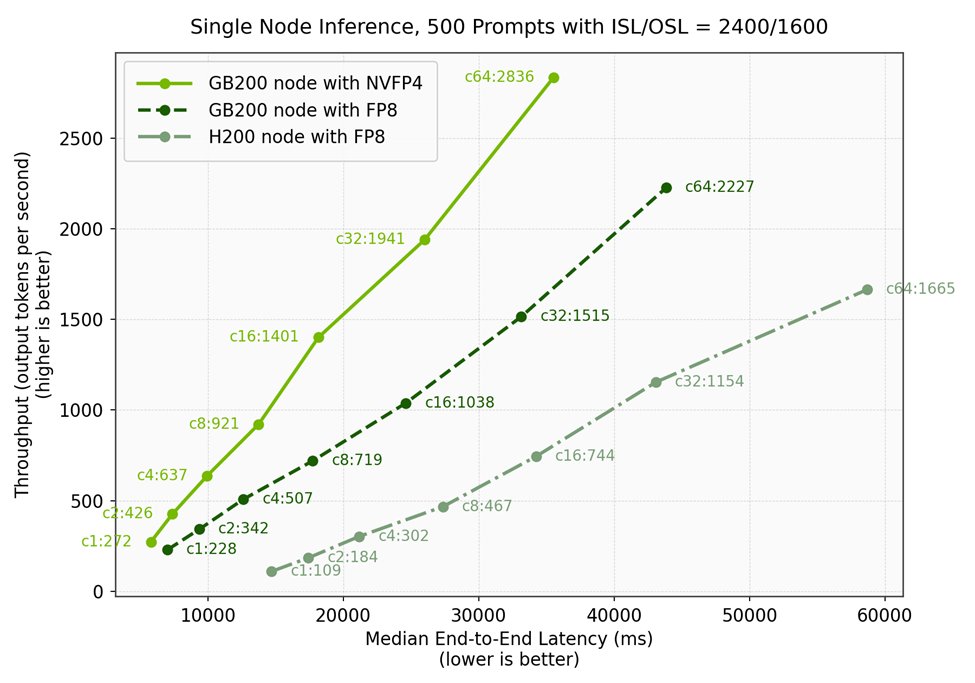
Figure 1 plots throughput (output tokens per second) against median end-to-end latency (ms). The annotations on the graph denoted "cX:Y" outline the request concurrency at which the data point was gathered, where X is the request concurrency, and Y is the throughput observed at that request concurrency, measured in tokens per second. Higher and further left indicates better efficiency.
| Configuration | Concurrency | Throughput (tks/s) | Median E2E Latency (ms) | Throughput/Latency |
|---|---|---|---|---|
| GB200 with NVFP4 | 1 | 272 | 5,801 | 0.047 |
| GB200 with FP8 | 1 | 228 | 7,015 | 0.033 |
| H200 with FP8 | 1 | 109 | 14,716 | 0.007 |
Key findings include:
- Up to 2.5x lower end-to-end latency: A GB200 node with NVFP4 delivers 5801 ms median latency vs. 14716 ms median latency on an H200 node at concurrency 1, a 2.5x improvement.
- Best efficiency curve: At each concurrency, a GB200 node with NVFP4 has the highest throughput and lowest latency compared to both a GB200 node with FP8 and an H200 node with FP8.
- Serve up to 16x more users per GPU: Given an end-to-end latency target of 15,000 milliseconds, single-node inference for DeepSeek-V3.2 with NVFP4 on an NVIDIA GB200 node yields 8x the throughput and can serve up to 8 concurrent users, while an NVIDIA H200 node can serve only 1 user. Since GB200 NVL72 nodes contain 4 GPUs, and H200 nodes contain 8 GPUs, this translates to 16x higher performance per GPU.
Production Deployment
The optimized configuration is now used to serve DeepSeek-V3.2 on Microsoft Foundry. The serving configuration parameters include:
| Parameter | Blackwell NVFP4 | Blackwell FP8 | Hopper FP8 |
|---|---|---|---|
| GPUs | 4x GB200 | 4x GB200 | 8x H200 |
| Nodes | 1 | 1 | 1 |
| Tensor Parallelism | 4 | 4 | 8 |
| Max Batch Size | 64 | 64 | 64 |
| MTP Enabled | Yes | Yes | No |
| Inference Engine | TensorRT LLM v1.2.0rc8 | TensorRT LLM v1.2.0rc8 | TensorRT LLM |
| Model Checkpoint | nvidia/DeepSeek-V3.2-NVFP4 | deepseek-ai/DeepSeek-V3.2 | deepseek-ai/DeepSeek-V3.2 |
Future Directions
The team anticipates even greater performance improvements with multi-node serving configurations, including those leveraging disaggregated serving, TensorRT LLM's Wide EP capabilities, and all 72 GPUs on the NVIDIA GB200 NVL72 rack system. They also plan to apply the same approach of introducing Blackwell, NVFP4, TensorRT LLM, and kernel tuning to additional model families.
The work was enabled by close collaboration between engineering teams from Microsoft and NVIDIA, with key contributors including Xiaoran Li, Tao Wang, and Vivek Ramaswamy from Microsoft; and Stephen McCullough, Anurag Mukkara, and Nikhar Maheshwari from NVIDIA.
This breakthrough represents a significant advancement in making large language model inference more efficient and cost-effective, particularly for demanding applications requiring high throughput and low latency.
Comments
Please log in or register to join the discussion