A technical deep dive into building a voice agent that achieves ~400ms end-to-end latency, outperforming platforms like Vapi by 2×. The article explores the challenges of turn-taking, architecture design choices, and the critical impact of geography and model selection on voice agent performance.
How I built a sub-500ms latency voice agent from scratch
Voice agents present a fascinating technical challenge that goes beyond typical AI applications. Unlike text-based interfaces where users control the interaction pace through explicit actions like hitting "send," voice requires continuous, real-time orchestration of multiple components with precise timing. This article examines how a custom-built voice agent achieved sub-500ms latency, significantly outperforming existing platforms.
The Core Challenge: Turn-Taking
At the heart of any voice agent lies a fundamental question: is the user speaking or listening? This simple binary decision masks substantial complexity. When a user starts speaking, the agent must immediately stop all audio generation and cancel any in-flight processing. When the user stops speaking, the system must confidently determine that they've completed their turn and begin responding with minimal delay.
As the author notes, "Human speech includes pauses, hesitations, filler sounds, background noise, and non-verbal acknowledgements that shouldn't interrupt the agent." This makes turn detection far more nuanced than simple voice activity detection (VAD). A purely VAD-based approach would mistake natural pauses for completed turns, leading to premature responses and awkward conversations.
Architecture Evolution
The author's approach evolved through two distinct phases:
Phase 1: VAD-Only Prototype
The initial implementation deliberately avoided transcription and language models, focusing instead on establishing a functional turn-taking loop:
- A FastAPI server handled WebSocket connections from Twilio
- Audio packets were decoded and fed to Silero VAD (a 2MB open-source model)
- A simple state machine tracked whether the user was speaking or listening
- When speech ended, a pre-recorded WAV file was played back
- When speech resumed, the system flushed buffered audio and stopped playback
This approach provided a valuable baseline for latency and demonstrated that even a minimal implementation could feel somewhat conversational when the turn-taking loop was properly implemented.
Phase 2: Full Pipeline with Flux
The second iteration replaced the hand-rolled VAD with Deepgram's Flux, a streaming API that combines transcription and turn detection. Flux emits "start of turn" and "end of turn" events, providing a more reliable signal for orchestrating the agent's responses.
The full pipeline operates as follows:
- When Flux signals the end of a user turn, the transcript and conversation history are sent to an LLM
- As soon as the first token arrives, it's streamed into a text-to-speech service
- Every audio packet produced by TTS is forwarded directly to the outbound Twilio socket
This streaming architecture is critical to achieving low latency. The author notes that "keeping text-to-speech connections warm" shaved approximately 300ms off response times by avoiding the overhead of establishing new WebSocket connections for each turn.
The Impact of Geography
The author's experiments revealed a crucial insight: in voice systems, physical proximity matters. The initial implementation, running from a remote location in southern Turkey, achieved end-to-end latency of around 1.7 seconds—more than twice as slow as Vapi's comparable configuration.
After deploying the orchestration layer to Railway's EU region and configuring all services (Twilio, Deepgram, and ElevenLabs) to use EU endpoints, the results improved dramatically:
- Latency measured at the server dropped from 1.6s to ~690ms
- Total end-to-end latency (including Twilio's edge) fell to roughly 790ms
- This represented a 2× improvement over the local implementation
Notably, this custom orchestration actually beat Vapi's own estimates by about 50ms using the same underlying models.
Model Selection and TTFT
A significant finding was the dramatic difference in time-to-first-token (TTFT) across providers. After testing various models, the author discovered that Groq's llama-3.3-70b model achieved TTFT latency up to 3× faster than OpenAI's alternatives:
- Groq's models: ~80ms (faster than a human blink, typically ~100ms)
- OpenAI's models: 300-500ms+
Swapping gpt-4o-mini for Groq's llama-3.3-70b further reduced end-to-end latency to approximately 400ms, making the agent feel nearly instantaneous. At this latency, "the conversation felt smooth and snappy," with the agent's voice cutting out almost immediately when the user started speaking.
Technical Takeaways
The project yielded several key insights for building low-latency voice agents:
Latency Optimization: The perceived responsiveness of a voice agent is determined by the time from when a user stops speaking to when they hear the first syllable of the agent's response. This path involves turn detection, transcription, LLM time-to-first-token, text-to-speech synthesis, and network hops.
Model Choice Matters: TTFT accounts for more than half of total latency in voice systems. The author's tests showed that model choice had a greater impact on latency than architectural optimizations.
Streaming Pipelines: A production voice agent cannot be built as three sequential steps (STT → LLM → TTS). Instead, the agent turn must be a streaming pipeline where LLM tokens flow into TTS as soon as they arrive.
Interruption Handling: When a user starts speaking, the system must cancel LLM generation, tear down TTS, and flush buffered audio simultaneously. Missing any component makes interruptions feel broken.
Geography as a Design Parameter: When orchestrating multiple external services, physical co-location is critical. Moving the orchestration layer and using regional endpoints cut end-to-end latency in half.
Bespoke vs. Off-the-Shelf
The author acknowledges that platforms like Vapi and ElevenLabs offer substantial value beyond orchestration, including APIs, observability, reliability, and extensive configuration options. For most teams, rebuilding these components would be impractical.
However, building a custom voice agent provides valuable insights into what parameters actually control performance and where bottlenecks exist. This understanding makes teams better at configuring off-the-shelf platforms and enables them to build more bespoke solutions when their use cases demand it.
As the author concludes, "Voice is an orchestration problem. Once you see the loop clearly, it becomes a solvable engineering problem."
The full source code for this project is available on GitHub, offering a practical reference for developers looking to implement similar solutions.
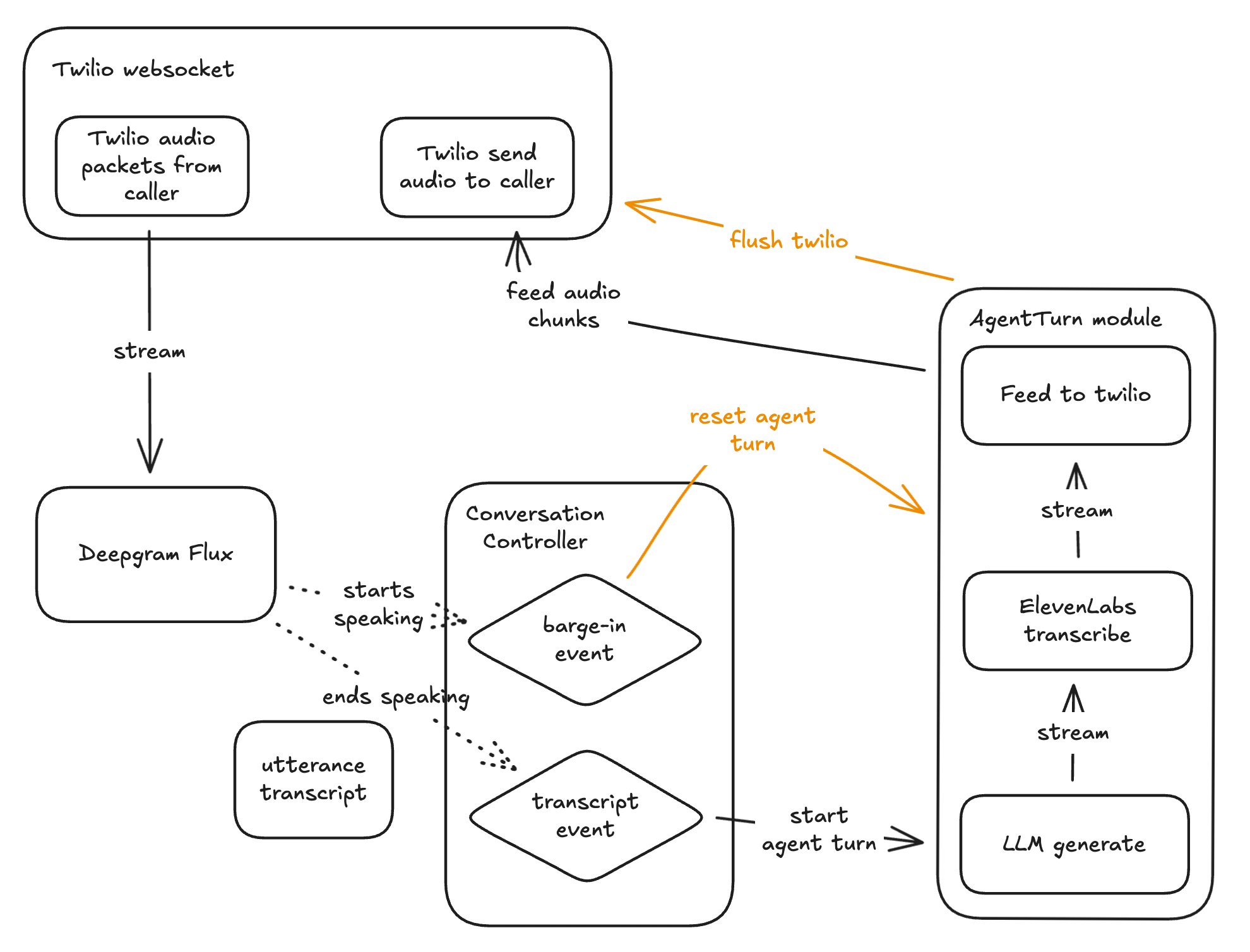
Full voice agent architecture showing how Twilio streams audio to Deepgram Flux for turn detection, which triggers either a barge-in (cancel everything) or an agent turn (LLM → TTS → audio back to the caller)
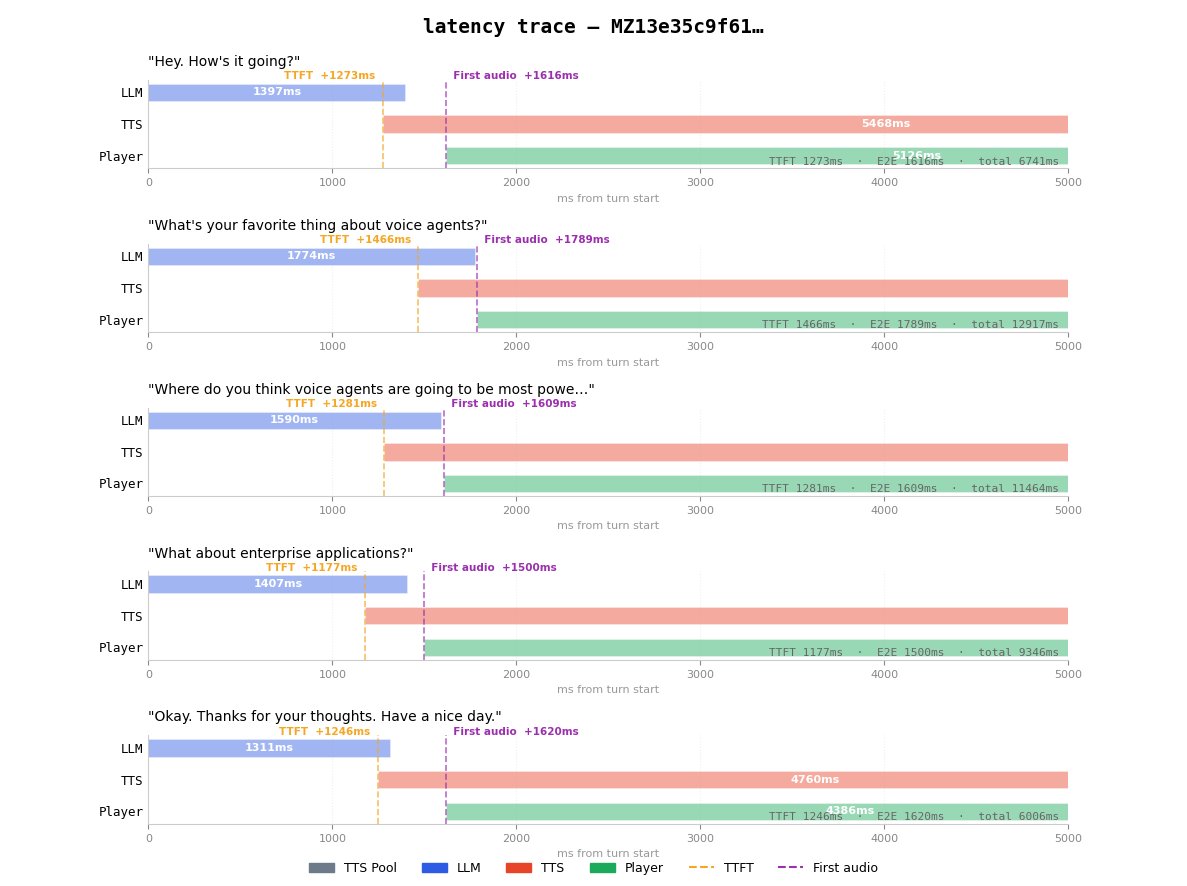
Latency trace running locally from southern Turkey. TTFT averages ~1.3s, with first audio arriving ~1.6s after the turn ends. The delay becomes noticeable at this distance.
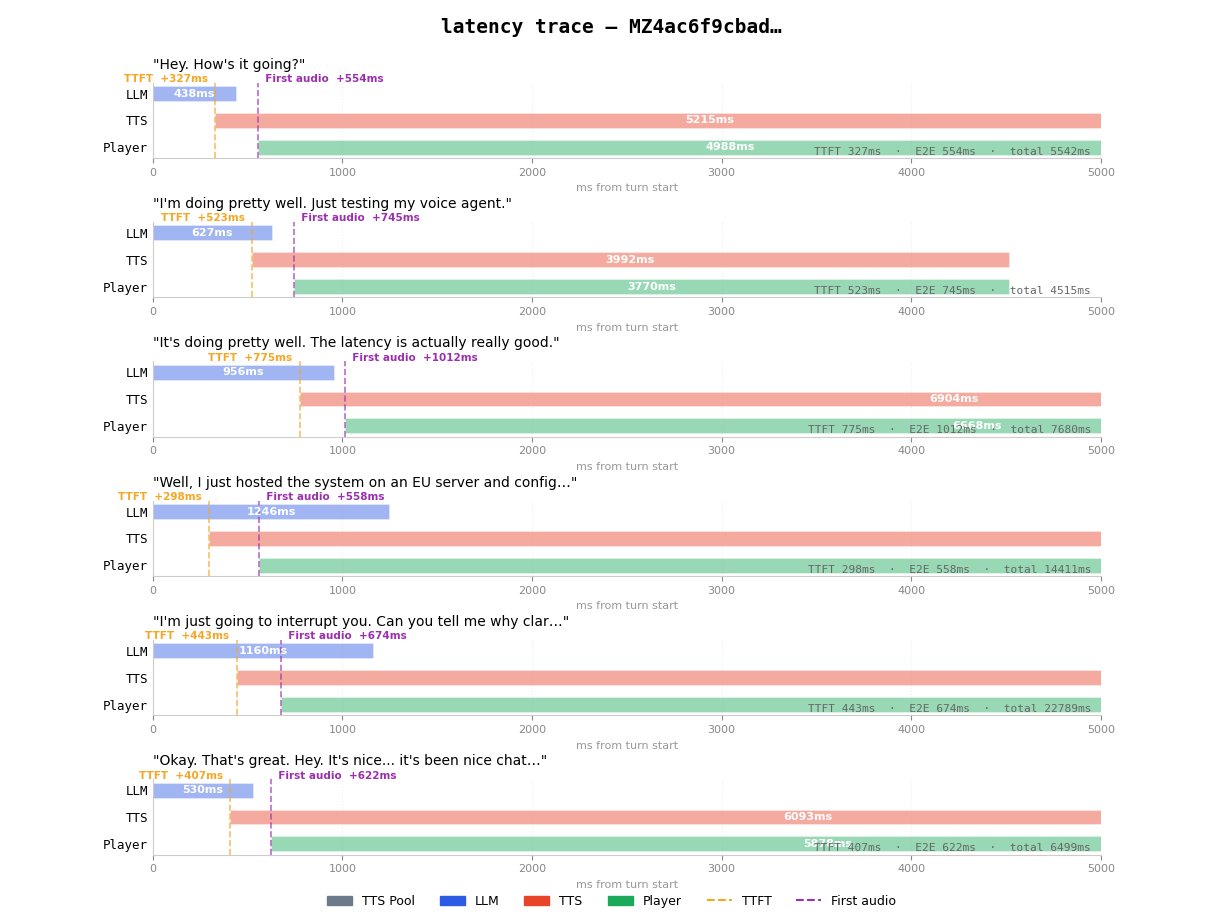
Latency trace after deploying to Railway EU. TTFT drops to ~300-500ms, with first audio at ~550-750ms. The average latency measured at the server dropped to ~690ms, translating to roughly 790ms end-to-end once Twilio's edge is included.
{{IMAGE:2}}
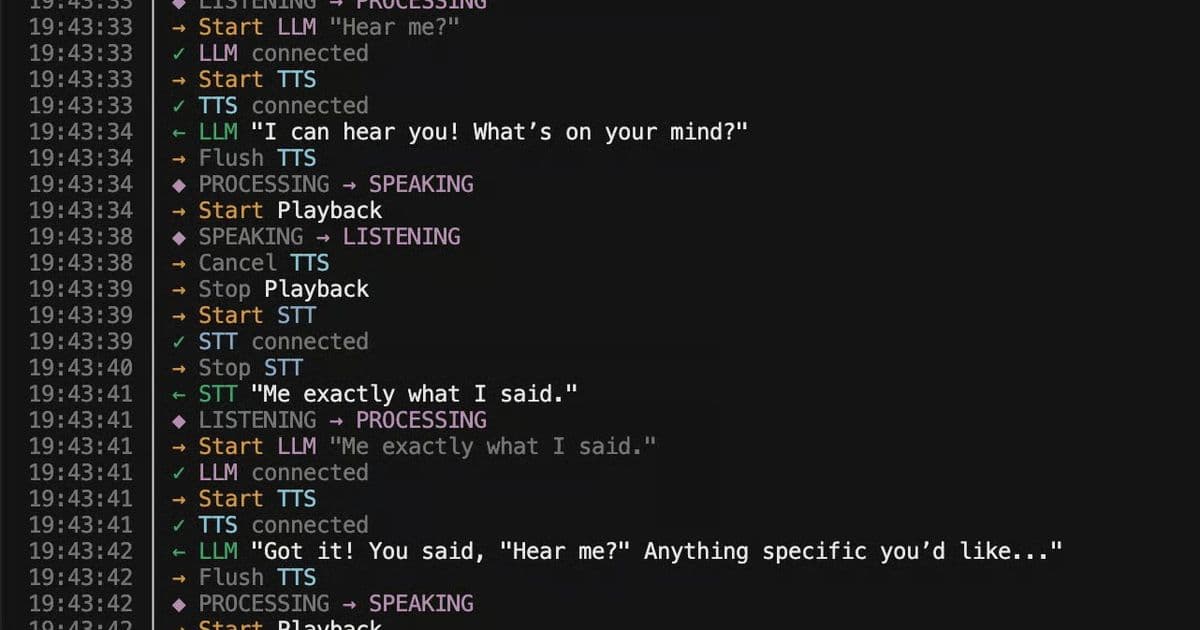
Console output of the voice agent running. The custom implementation outperformed Vapi's equivalent setup by 2× on latency, achieving ~400ms end-to-end response times.
Comments
Please log in or register to join the discussion