A deep dive into how Intercom improved their CI performance by optimizing Ruby's path handling methods, resulting in significant speed improvements for their monolith with 1350 parallel workers.
In the competitive world of continuous integration, every millisecond counts. At Intercom, a customer communications platform, engineers have been working to optimize their CI pipeline that supports their massive Ruby monolith. With 1350 parallel workers running by default, even small optimizations can have outsized impacts - one second shaved from setup time translates to over 20 minutes of compute saved per build.
The Intercom team, led by engineer byroot, identified that application boot time was a key bottleneck in their CI process. When running test suites in parallel, the setup phase - which includes booting the application - becomes a significant portion of total runtime. For a 1-hour test suite with a 1-minute setup phase, using 60 workers instead of 4 reduces runtime from 16 minutes to just 2 minutes, but half of that time is still spent on setup rather than actual testing.
The team focused on improving Bootsnap, a tool that caches Ruby's load path to speed up file loading. While Bootsnap has been part of Rails for nearly a decade, byroot discovered opportunities for significant optimization in how it scans directories.
"The cost of Ruby's require mechanism scales very badly," byroot explained. "An application with 400 gems is likely way more than twice as slow to boot compared to one with 200 gems." This is because Ruby performs a linear search through its load path for each file, resulting in an O(N*M) complexity where N is the load path size and M is the number of loaded features.
The first optimization addressed an N+1 syscall problem in Bootsnap's directory scanning. For each entry in a directory, the code was calling File.directory?, which results in a stat(2) syscall. "This is like the system programming equivalent of N+1 queries in web programming," byroot noted. The team implemented a solution that mimics the d_type member available in readdir(3) on Linux and BSD, allowing directory entries to be classified without additional syscalls.
This change resulted in a 2x speedup, reducing the time to scan 32k files in 10k repositories from 500ms to 230ms. The optimization was so significant that it's being incorporated into Ruby 4.1.0 as a new Dir.scan method. You can learn more about this optimization in the original blog post here.
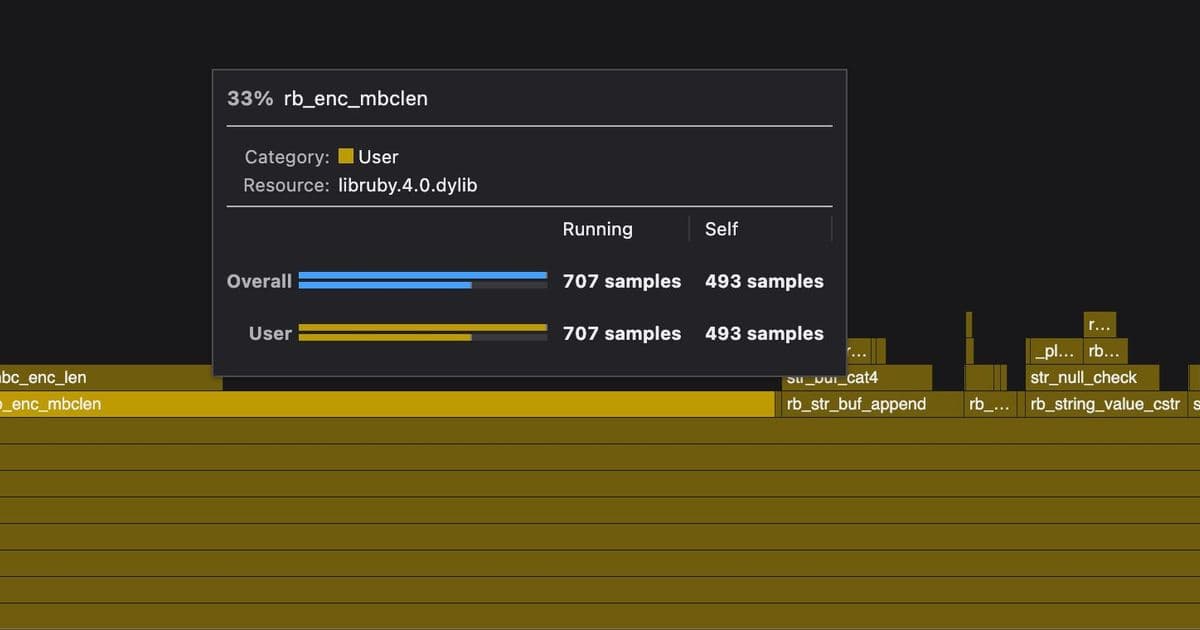
The team then turned their attention to File.join, a method used frequently during application boot. Through profiling, they discovered that File.join was up to 4x slower than simple string interpolation for common cases. The bottleneck was in encoding-related functions, particularly rb_enc_mbclen, which handles multi-byte character processing.
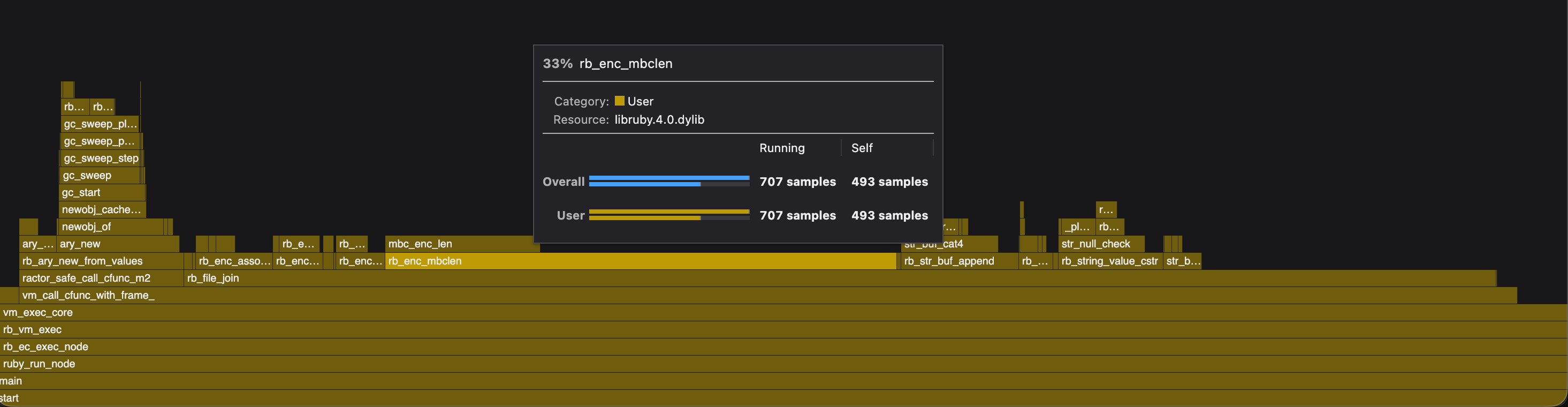
The optimization involved implementing a fast path for ASCII-compatible encodings (UTF-8, ASCII, US-ASCII), which represent the overwhelming majority of path usage. They also improved how trailing path separators are handled by searching from the end of the string rather than scanning the entire string.
Additional optimizations included:
- Replacing unnecessary NULL termination checks with simpler content validation
- Eliminating array allocations for variadic arguments
- Applying similar optimizations to other path methods like File.basename, File.dirname, File.extname, and File.expand_path
The combined efforts resulted in File.join being over 7x faster for common use cases, and in some cases, even outperforming string interpolation. For Intercom's CI system, these improvements mean reduced setup times and significant cost savings across their 1350 parallel workers.

The work demonstrates how even mature programming languages and tools can benefit from performance optimizations when applied to specific high-impact scenarios like CI/CD pipelines. As organizations increasingly rely on automated testing and deployment, such low-level optimizations can provide competitive advantages in both speed and cost efficiency.
The optimizations have been submitted to Ruby core and are expected to be included in Ruby 4.1.0, benefiting the broader Ruby community beyond just Intercom's use case. You can follow the progress of these changes in the Ruby repository here.
This technical deep dive showcases how a systematic approach to performance optimization - identifying bottlenecks, understanding root causes, and implementing targeted fixes - can yield substantial improvements in real-world applications. The work highlights the importance of profiling and understanding the underlying implementation details of commonly used libraries and language features.
Comments
Please log in or register to join the discussion