PgQue brings the zero-bloat queue pattern of Skype's legendary PgQ system to contemporary PostgreSQL deployments, offering a durable event stream without the bloat tax that plagues traditional in-database queues.
In the ever-evolving landscape of data processing and event-driven architectures, the challenge of implementing efficient queues within relational databases has persisted for years. Traditional approaches often create a familiar pattern: initial performance followed by gradual degradation as dead tuples accumulate, VACUUM pressure mounts, and index bloat sets in. Enter PgQue, a modern implementation of the legendary PgQ architecture that promises to break this cycle while maintaining compatibility with managed PostgreSQL services.
The Resurrection of a Proven Architecture
PgQue revives PgQ (Postgres Queue), one of the longest-running PostgreSQL queue architectures in production history. Originally designed at Skype to handle messaging for hundreds of millions of users, PgQ demonstrated remarkable resilience over more than a decade in large self-managed PostgreSQL deployments. Its core strength lay in a snapshot-based batching approach that avoided the row-by-row operations that lead to bloat in traditional queue implementations.
The critical innovation in PgQue is its reimagination of this battle-tested engine in pure PL/pgSQL, removing the dependencies that limited PgQ's adoption in modern environments. Where the original PgQ required a C extension (pgq) and an external daemon (pgqd)—neither of which function on most managed PostgreSQL providers—PgQue operates entirely within the database itself.
Zero Bloat by Design
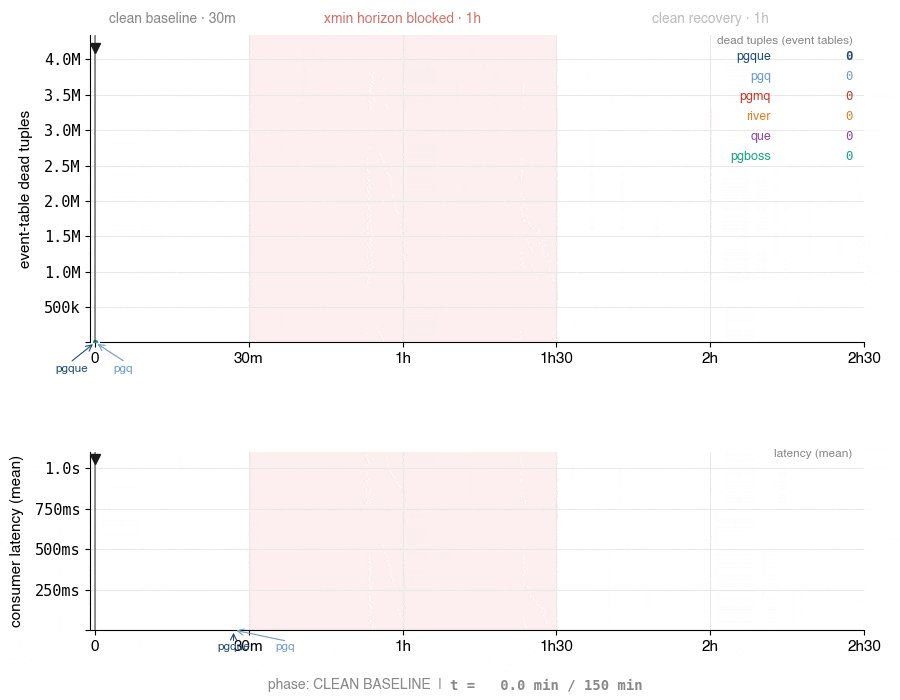
The fundamental problem PgQue addresses is the bloat that inevitably accumulates in traditional PostgreSQL queues. Most implementations rely on SKIP LOCKED plus DELETE and/or UPDATE operations to manage queue processing. While this approach works adequately in simple scenarios, it creates dead tuples under sustained load, leading to VACUUM pressure, index bloat, and performance degradation that worsens over time.
PgQue avoids this entire class of problems through architectural choices:
- Snapshot-based batching: Instead of processing events row by row, PgQue creates batches based on database snapshots, ensuring consistent views of the queue state.
- TRUNCATE-based table rotation: Rather than deleting individual processed events, the queue rotates entire tables, eliminating dead tuples by construction.
- Separate retry and dead-letter tables: Failed processing doesn't pollute the main queue path.
This design ensures the hot path remains predictable and stable regardless of load or runtime duration. As the documentation states, "Zero bloat by design — no dead tuples in the main queue path" and "Built for heavy-loaded systems — the sustained-load regime the original PgQ architecture was designed for."
Managed PostgreSQL Compatibility
Perhaps PgQue's most significant contribution is its compatibility with managed PostgreSQL services. By implementing the queue engine entirely in PL/pgSQL without requiring C extensions or external daemons, PgQue works across virtually all PostgreSQL 14+ deployments:
- Amazon RDS and Aurora
- Google Cloud SQL
- AlloyDB
- Supabase
- Neon
- And most other managed providers
This compatibility eliminates the need for provider approval, shared_preload_libraries configuration, or database restarts—common barriers with custom extensions. The installation is remarkably simple, requiring just a single SQL file to be executed, with pg_cron (or an alternative scheduler) handling the periodic ticking mechanism.
Event-Driven Architecture with Fan-Out Support
PgQue positions itself not as a traditional job queue but as an event/message queue optimized for high-throughput streaming. Its architecture provides a shared event log with independent per-consumer cursors, enabling fan-out patterns where multiple consumers can independently process all events from a single stream.
This model differs significantly from competing approaches:
- Traditional job queues typically deliver each job to a single worker
- Some implementations provide fan-out through data duplication (one INSERT per subscriber per event)
- PgQue maintains a position on a shared log, eliminating data duplication while providing atomic batch boundaries
This approach brings PostgreSQL closer to Kafka-like semantics while maintaining the transactional guarantees and simplicity of a database-native solution.
The Latency Trade-off
Every architectural choice involves trade-offs, and PgQue is no exception. Its snapshot-based batching approach, which prevents bloat, introduces a latency characteristic: end-to-end delivery typically lands within 1-2 seconds in the default configuration (up to 1 second for the next tick plus the consumer's poll interval).
While per-call latency remains in the microsecond range, this design isn't suitable for applications requiring single-digit millisecond dispatch times. The documentation explicitly states: "If your top priority is single-digit-millisecond dispatch, PgQue is the wrong tool. If your priority is stability under load without bloat, that is where PgQue fits."
Implementation and Adoption
The practical implementation of PgQue is straightforward. After installing the single SQL file, developers can create queues, subscribe consumers, send events, and process them using simple SQL functions. The recommended approach uses pg_cron for automatic ticking, though any external scheduler can drive the queue operations.
Current benchmarks show promising performance characteristics: approximately 86k events/second for PL/pgSQL inserts and 2.4M events/second for consumer reads, with zero dead-tuple growth under sustained load.
Positioning in the Broader Ecosystem
PgQue occupies a specific niche in the messaging ecosystem:
- Vs. traditional job queues (pg-boss, Oban, etc.): PgQue prioritizes event streaming with fan-out over per-job processing, lacks built-in worker frameworks, and provides no job priorities
- Vs. external message brokers (Kafka, RabbitMQ): PgQue offers simplicity and transactional guarantees at the cost of throughput and advanced features
- Vs. other PostgreSQL queues (PGMQ, River, Que): PgQue's zero-bloat design and snapshot-based approach provide superior stability under sustained load
Conclusion
PgQue represents a thoughtful reimagination of a proven architecture for contemporary needs. By bringing the battle-tested PgQ pattern into the era of managed PostgreSQL services, it offers a compelling solution for teams seeking event-driven capabilities without the operational complexity of external message brokers or the performance degradation of traditional in-database queues.
As the project documentation acknowledges, PgQue is early-stage as a product and API layer, but its foundation—the PgQ architecture—has demonstrated remarkable resilience at scale for over a decade. For teams already invested in PostgreSQL seeking a durable, zero-bloat event stream, PgQue offers an intriguing proposition that deserves serious consideration.
The project is available on GitHub under the Apache-2.0 license, with documentation, benchmarks, and example implementations to help teams evaluate its suitability for their specific use cases.
Comments
Please log in or register to join the discussion