Shopify has replaced its depth‑first GraphQL executor with a breadth‑first engine called GraphQL Cardinal. The new model batches resolver work across each level of a query tree, delivering up to 15× faster field execution, dramatically lower GC pressure, and several seconds of latency reduction for large list queries. The article explains how the engine works, why it matters for high‑scale commerce APIs, and what trade‑offs teams should consider when adopting a similar approach.
 )
)
Service update – GraphQL Cardinal goes live at Shopify
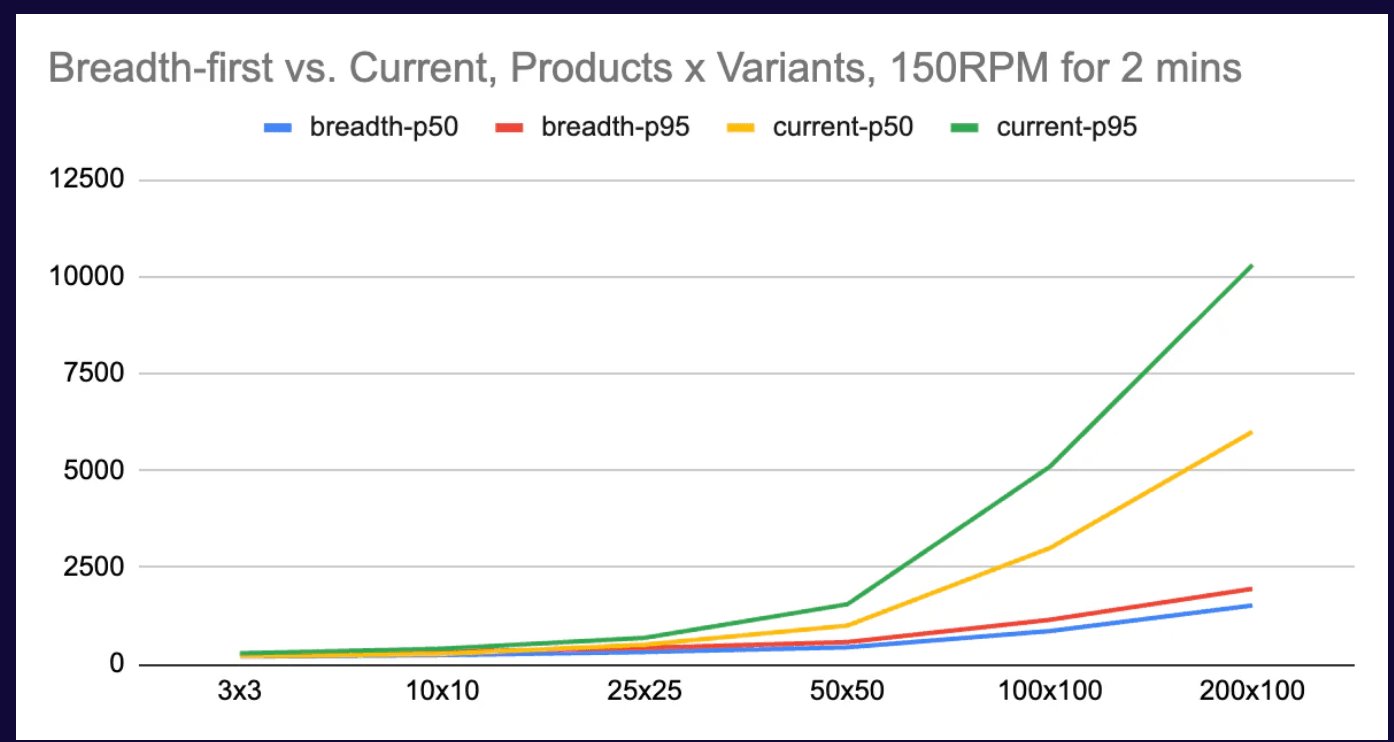
Shopify announced that its production GraphQL service now runs on a custom execution engine dubbed GraphQL Cardinal. The engine swaps the classic depth‑first traversal used by most GraphQL servers for a breadth‑first model that processes a query level by level. In Shopify’s own measurements a large list query that previously took ~20 s to resolve now finishes in ~1.3 s, a 15× speed‑up at the field level, with 6× less garbage‑collection overhead and a 4 s reduction in the P50 end‑to‑end latency.
The change is purely internal – existing schemas, resolvers and client queries remain unchanged – but the execution pipeline has been rewritten to batch resolver calls across all objects at the same depth. Shopify rolled the engine out gradually across its storefront and admin APIs, monitoring latency, error rates, and resource consumption throughout the migration.
“Conventional GraphQL execution is algorithmically expensive at scale, and very few have questioned it.” – Farhan Thawar, Head of Engineering, Shopify (LinkedIn).
Why breadth‑first matters – use‑case breakdown
1. Deep, relational e‑commerce data
Shopify’s product catalog often spans dozens of nested relationships – products → variants → inventory → pricing → promotions. A depth‑first executor walks this tree recursively, invoking a resolver for each node before moving deeper. When a query requests a list of 10 k products with their variants, the engine may call the same resolver thousands of times, each call allocating short‑lived objects that pressure the JVM’s garbage collector.
2. Natural batching without extra code
In a breadth‑first model the engine first resolves all products at depth 1, then all variants at depth 2, and so on. Because each resolver receives a batch of entities, developers can write a single data‑access call that pulls the required rows in one database round‑trip. This eliminates the classic N+1 problem without requiring a separate DataLoader layer or custom batching logic.
3. Better CPU cache locality
Processing a homogeneous batch of objects keeps the working set small and predictable, allowing the CPU cache to retain relevant data between resolver invocations. Depth‑first execution, by contrast, jumps between disparate objects, causing frequent cache misses.
4. Predictable memory usage
Since the engine allocates a batch container per level rather than per node, the peak memory footprint grows with the width of the query, not its depth. This makes it easier to size containers and avoid out‑of‑memory spikes during traffic spikes.
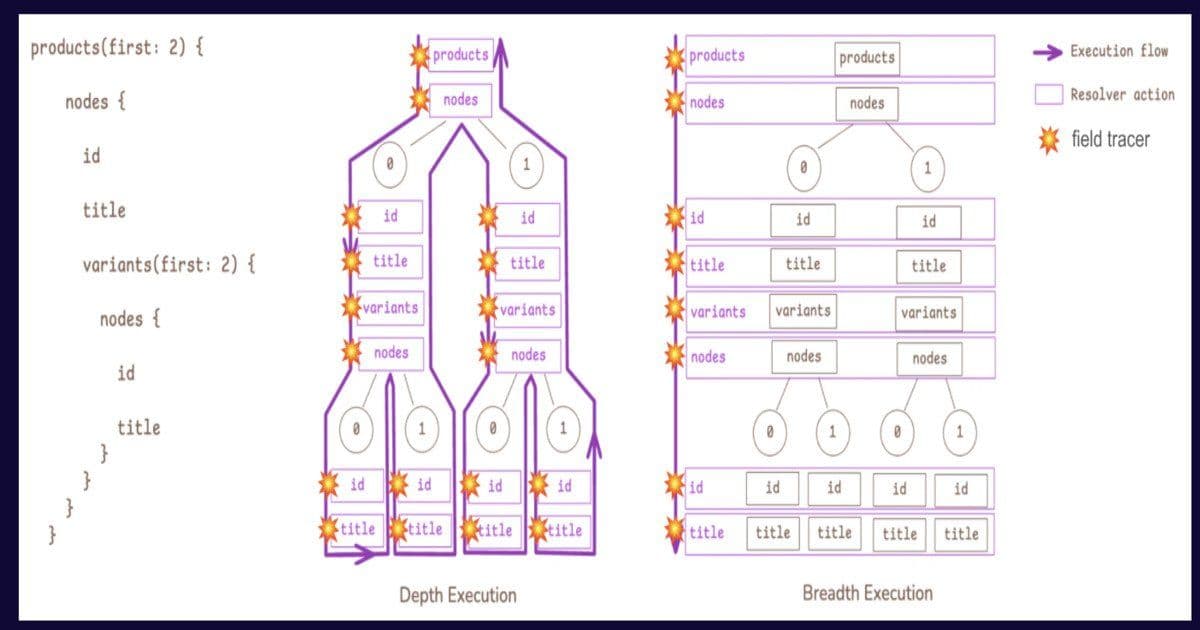
How the engine works – a quick architectural sketch
- Parse & plan – The incoming GraphQL document is parsed into an abstract syntax tree (AST). The planner annotates each field with its depth.
- Level queues – For each depth level a work queue is created. The root fields are placed in level 0.
- Batch dispatch – The executor pulls the next non‑empty queue, groups the pending resolver calls by resolver function, and invokes the resolver once with a list of source objects.
- Result aggregation – The resolver returns a list of results that the engine maps back to the original field positions.
- Advance depth – Once all fields at the current level are resolved, the engine populates the next‑level queue with child fields derived from the returned objects.
- Tracing & metrics – Shopify extended its tracing pipeline (OpenTelemetry‑based) to emit a per‑level timing metric, making it easy to compare breadth‑first vs depth‑first performance in production dashboards.
The approach builds on concepts from the broader GraphQL community, such as Airbnb’s batched resolvers and the experimental graphql-breadth-exec library, but Shopify’s implementation is tightly integrated with its Go‑based runtime and its internal request scheduler.
Trade‑offs and migration considerations
| Aspect | Breadth‑first (Cardinal) | Depth‑first (traditional) |
|---|---|---|
| Resolver design | Resolvers must accept a slice of source objects; simple loops replace recursive calls. | Resolvers receive a single source object; easier for developers unfamiliar with batching. |
| Compatibility | Requires a thin adapter layer for existing resolvers that only accept a single object. Shopify provided a compatibility shim that wraps single‑object resolvers into batch‑aware wrappers. | No adaptation needed; works out‑of‑the‑box with most GraphQL servers. |
| Memory pattern | Predictable, grows with query width. | Can spike with deep nesting and many recursive calls. |
| Latency for small queries | Slight overhead for queue management; negligible for most workloads. | Slightly faster for trivial queries because there is no batching step. |
| Observability | New per‑level metrics give fine‑grained insight. | Traditional field‑level timing only. |
Migration steps for teams
- Add a batch wrapper – Create a helper that converts a resolver expecting a single source into one that can process a slice. Many languages (Go, TypeScript, Java) can generate this automatically.
- Enable Cardinal mode – Switch the GraphQL server configuration flag from
executionMode: depthFirsttoexecutionMode: breadthFirst. - Run A/B tests – Compare latency and GC metrics on a staging cluster before rolling out to production.
- Update tracing – Ensure your OpenTelemetry collector captures the new
graphql.execution.levelattribute. - Monitor error rates – Breadth‑first batching can surface hidden data‑access errors (e.g., batch queries that exceed DB limits). Adjust batch size limits accordingly.
When to consider a breadth‑first engine
- High‑volume list queries that touch many rows (catalogs, feeds, analytics).
- Schemas with deep nesting where the same resolver is invoked thousands of times per request.
- Teams already using DataLoader or similar batching – the engine can replace that layer and simplify code.
- Environments where GC pressure is a known bottleneck (e.g., JVM‑based services under heavy load).
If your API primarily serves point‑lookups or shallow queries, the performance gains may be marginal and the added complexity of batch‑aware resolvers might not be justified.
Looking ahead
Shopify’s public blog post includes a detailed benchmark suite and the open‑source graphql-cardinal prototype (currently internal). The company plans to expose the engine as a configurable module for other teams within its ecosystem, and is exploring a plug‑in model that would let external developers enable breadth‑first execution on top of existing GraphQL servers such as Apollo Server or GraphQL‑Java.
For architects building large‑scale, event‑driven APIs, the key takeaway is that execution algorithms themselves can become a performance frontier. By rethinking the traversal order, you can achieve latency reductions comparable to database indexing or network optimizations, without touching the data layer.
References
- Shopify engineering blog post on GraphQL Cardinal: https://shopify.engineering/graphql-cardinal-breadth-first
- Airbnb’s batched resolver pattern: https://github.com/airbnb/javascript/tree/master/packages/graphql-batch
graphql-breadth-execexperiment: https://github.com/graphile/graphql-breadth-exec- OpenTelemetry GraphQL tracing guide: https://opentelemetry.io/docs/specs/semconv/graphql/
Comments
Please log in or register to join the discussion