Chester Lam examines SPEC’s freshly released CPU2026 benchmark, highlighting its expanded workload set, how modern Intel and AMD cores fare, and why the suite may still fall short of representing real‑world performance diversity.
A New Chapter for SPEC CPU Benchmarks
SPEC’s CPU benchmark has long been the yardstick that CPU designers reach for when they need a repeatable, vendor‑neutral performance story. The jump from CPU2017 to CPU2026 bumps the workload count from 43 to 52 and adds several thousand lines of source code per test. The intent, according to SPEC, is to modernise the suite while keeping the original portability promise.
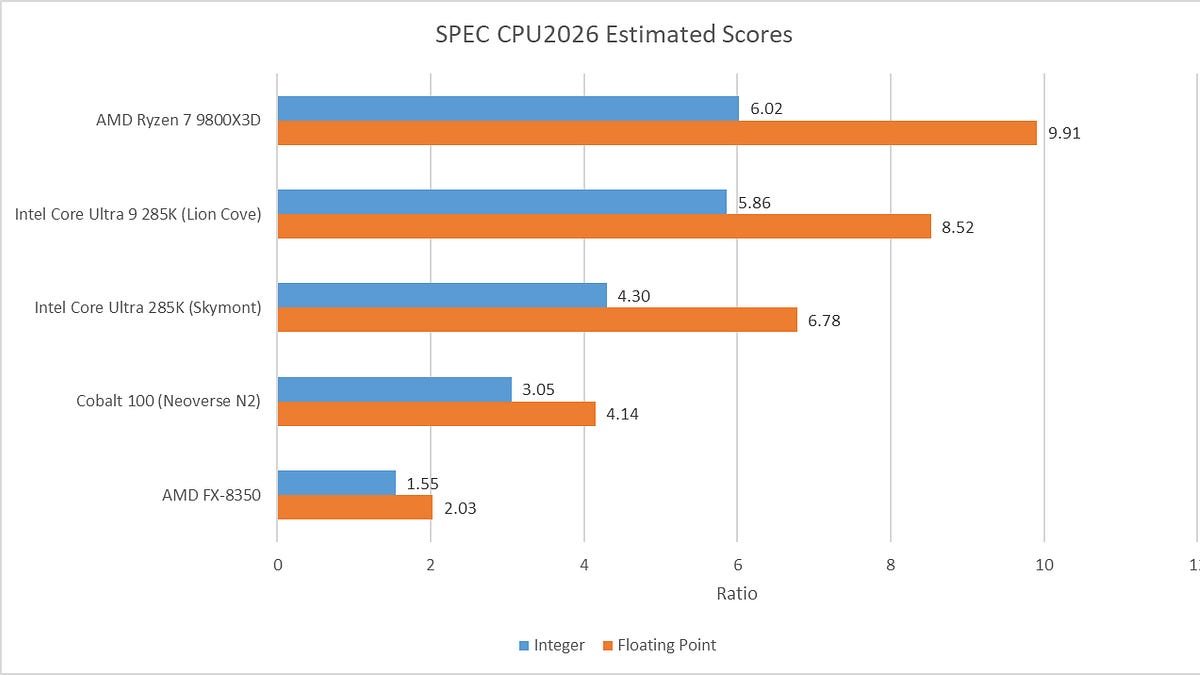
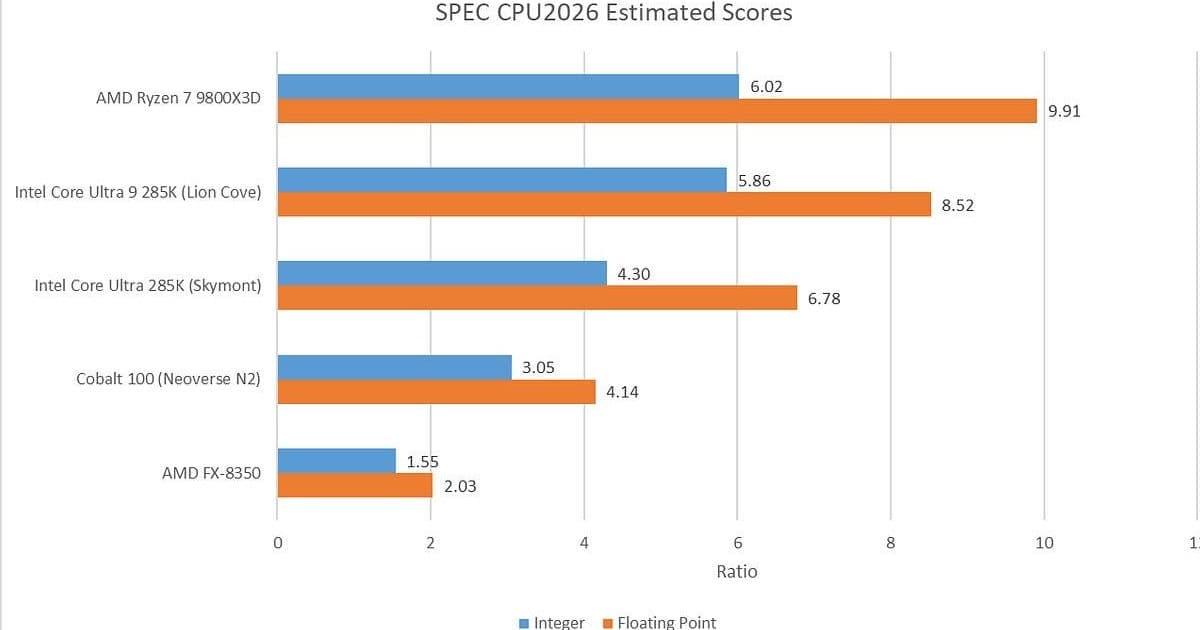
What the Numbers Show
Running the suite with GCC 14.2 ‑O3 on a handful of recent desktop silicon (Intel Lion Cove, AMD Zen 5, and a few older reference chips) reveals a clear pattern:
- Integer scores are now tightly clustered. Zen 5 and Lion Cove sit within a few percent of each other, while the old Ampere eMAG reference system lags dramatically—its score of 1.0 is more a historical artifact than a meaningful baseline.
- Floating‑point scores tilt in AMD’s favour. Zen 5 pulls ahead on most FP tests, largely because GCC is able to emit AVX‑512 instructions for workloads such as
706.stockfish,749.fotonik3d, and765.roms. - IPC (instructions per cycle) has risen overall. The integer suite now averages closer to 3 IPC on high‑throughput tests, a jump from the 2‑3 IPC range seen in CPU2017. The floating‑point suite still shows a wider spread, especially on Zen 5 where some tests exceed 3 IPC while others stay near 2.
These observations line up with what we’ve seen in other synthetic scores like Geekbench 6, where modern cores can keep their pipelines fed with relatively predictable code.
Where the Suite Excels
- Core‑throughput focus – Most workloads have low branch‑misprediction rates. Tests such as
750.sealcryptoor721.gccpresent clean, tight loops that let the front‑end stay saturated. - Instruction‑cache stress – Several new integer tests have instruction footprints that spill out of the micro‑op cache, forcing the L1‑i and L2 caches to work harder. This gives a better view of how Intel’s larger 64 KB i‑cache and AMD’s 32 KB i‑cache handle real‑world code size.
- AVX‑512 utilization – The inclusion of vector‑heavy kernels that compile to AVX‑512 provides a useful data point for platforms that support the extension, something that was largely missing from CPU2017.
What Remains Missing
1. Branch‑prediction challenges are muted
CPU2017’s integer suite featured several notoriously branch‑heavy kernels (505.mcf, 541.leela, 557.xz) that exposed differences in branch‑predictor design. CPU2026 replaces those with compilation‑heavy tests (721.gcc, 725.llvm) that still branch, but far less aggressively. The result is higher IPC across the board, but it also means the benchmark no longer stresses the predictor as rigorously.
2. Low‑IPC corner cases are scarce
The original suite deliberately kept a handful of “slow” workloads to balance the overall picture. With the new set, the lowest‑IPC scores now hover around 1.5 IPC, which is still higher than the ~1 IPC typical of many game loops. Without a true low‑IPC anchor, it becomes harder to gauge how a design that favours raw throughput will behave on more irregular code.
3. Real‑world memory pressure is under‑represented
Most integer tests stay comfortably within a 1 MB L2 cache, and last‑level‑cache (LLC) misses are rare. Only a couple of floating‑point kernels (749.fotonik3d, 765.roms) generate noticeable LLC activity. For architects targeting workloads with large working sets—think in‑memory databases or high‑resolution rendering—the suite may not surface the bottlenecks that matter most.
Counter‑Perspectives from the Community
- Pro‑SPEC view – Advocates argue that a benchmark’s primary job is to be repeatable and vendor‑neutral. By trimming the most unpredictable branch‑heavy tests, CPU2026 reduces variance and makes cross‑generation comparisons cleaner.
- Skeptical view – Critics point out that a benchmark that “plays to the strengths” of today’s wide‑issue, deep‑pipeline cores risks becoming a marketing tool rather than a diagnostic probe. They suggest supplementing SPEC scores with game‑engine traces or real‑world server workloads to fill the gaps.
- Industry‑practitioner angle – Some OEMs have already begun pairing CPU2026 runs with micro‑architectural profiling (using Intel’s Software Development Emulator or AMD’s uProf). Early data shows that while the suite is useful for headline numbers, detailed design decisions still rely on a broader set of traces.
Bottom Line
SPEC CPU2026 is a solid evolution: it adds more code, embraces modern SIMD extensions, and gives a clearer picture of raw core throughput. At the same time, its reduced emphasis on branch‑prediction stress and low‑IPC corner cases means it cannot be the sole arbiter of a processor’s real‑world suitability. Engineers and reviewers should treat the scores as one data point among many, complementing them with workload‑specific benchmarks that probe memory pressure, irregular control flow, and mixed‑type instruction mixes.
For those interested in digging deeper, the full benchmark suite and documentation are available on the SPEC website. The raw performance counters used in this analysis can be found in the accompanying GitHub repository: github.com/chesterslam/spec2026‑analysis.
Comments
Please log in or register to join the discussion