
A reflective analysis of Ally Piechowski's comprehensive approach to auditing legacy Rails applications, focusing on the methodology that transforms technical assessments into actionable insights.
The Art of Rails Auditing: Beyond Code to Systemic Health
In the world of legacy system assessment, we often gravitate toward exhaustive code reviews and comprehensive tooling, believing that thorough examination will reveal all that ails our applications. Ally Piechowski's "How to Audit a Rails Codebase: Legacy App Playbook" challenges this assumption, presenting a methodology that recognizes the first week of an audit isn't about reading the code—it's about reading the signals. After 50+ engagements, Piechowski has developed a systematic approach that prioritizes understanding the human and organizational context of technical debt over purely technical analysis.
The Human Element: Signals Over Static Analysis
The most compelling aspect of Piechowski's approach is its emphasis on the human factors that often determine codebase health more than any metric. The diagnostic question "When's the last time you deployed on a Friday?" reveals more about system fragility than any static analysis could. That nervous laugh from stakeholders tells a story of fear, risk aversion, and broken deployment processes—issues that manifest in the code but originate in organizational practice.
This perspective reframes technical debt not merely as code quality issues but as symptoms of deeper problems: knowledge silos, inadequate documentation, deployment fragility, and organizational fear. The example of the checkout flow written by a departing engineer who never documented it illustrates how the loss of knowledge creates technical debt that transcends code quality itself.
The Diagnostic Trinity: Gemfile, Schema, and Routes
Piechowski's methodology begins with a remarkably efficient examination of three files that can reveal a working thesis in 30 minutes. This approach demonstrates a sophisticated understanding of where Rails applications typically accumulate technical debt:
Gemfile: Duplicated responsibilities (two auth systems, multiple file upload gems) indicate inconsistent architectural decisions over time. Gems that can't be explained represent historical decisions whose rationale has been lost.
schema.rb: "God tables" with 30+ columns signal separation of concerns violations. Missing indexes on foreign keys create performance problems. Integer primary keys in high-volume apps represent ID exhaustion timebombs that may not manifest for years.
routes.rb: The ratio of RESTful resources to custom routes reveals architectural consistency. As Piechowski notes, 500 custom routes isn't merely a style problem—it's an architectural indicator of emergent complexity.
The transactions table example with 122 columns illustrates how business evolution creates technical debt. Each payment processor integration added its own nullable columns, resulting in a database structure where most rows are mostly null—a design pattern that becomes increasingly inefficient as the system scales.
Tooling Strategy: Purposeful and Prioritized
The audit methodology presents a thoughtful approach to tooling that prioritizes based on risk and impact:
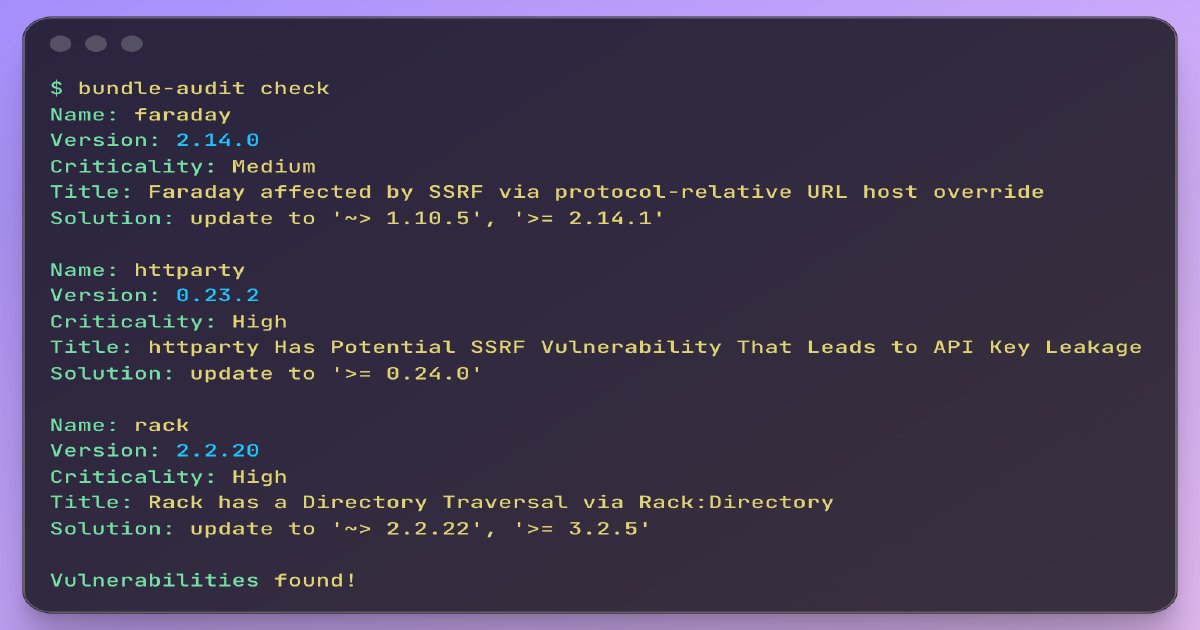
Security First: Bundle-audit and Brakeman should run immediately, with focus on critical CVEs in high-traffic code paths rather than raw advisory counts.
Zero Coverage as Fear Map: SimpleCov reports showing zero coverage on critical files like order.rb, payment.rb, and subscription.rb reveal the areas teams are afraid to touch—the real pain points that need addressing.
Dependency Health: Identifying end-of-life versions (like Rails 6.1 in regulated industries) frames technical debt in terms of compliance liability.
Complexity Analysis: Tools like cloc and RubyCritic provide context about code distribution and churn patterns, helping identify actively problematic areas rather than just measuring code volume.
The author's thoughtful approach to tool interpretation demonstrates that metrics only tell part of the story. High test coverage numbers don't reveal when critical business logic is buried in 900-line models with callbacks, nor do they indicate when the architecture has become so complex that changes in one area unpredictably affect others.
The Rewrite vs. Refactor Decision Matrix
Perhaps the most valuable contribution of this playbook is the clear framework for determining when a codebase needs a complete rewrite versus targeted refactoring. The distinction hinges on the team's relationship with the system:
Recoverable (Refactor):
- The team can specifically name what they're afraid of
- They have accurate mental maps of the system, even if the terrain is difficult
- Deploys happen regularly, even if tense
- A new developer can get the app running in under two hours
Critical (Rewrite):
- Multiple developers independently describe different parts as "nobody touches that"
- Deploys have stopped entirely due to unpredictability
- The test suite is too slow or unreliable to run
- "I changed one thing and something completely different broke" is a regular occurrence
This framework recognizes that the decision isn't purely technical—it's about the cost of continuing to work around the codebase versus the cost of starting over. The insight that sometimes "the business has outgrown the architecture and no amount of cleanup will fix that" reveals a sophisticated understanding of how systems evolve beyond their original design constraints.
The Art of Deliverables: Actionable Over Exhaustive
The evolution from exhaustive findings documents to single-page triage reports represents a significant shift in how technical assessments create value. The three-section approach (fix this week, fix this quarter, don't worry about it) acknowledges that technical teams can only address so much at once, and that prioritization is as much an art as a science.
The inclusion of a fourth category—work that can be done in parallel without interrupting current development—demonstrates an understanding of organizational constraints. Dependency upgrades, security patches, and dead code removal represent progress that doesn't require team bandwidth, creating momentum even on constrained projects.
Leading with the single most surprising finding rather than the longest list of observations reflects the understanding that clients hire auditors not just for observation but for insight—the ability to see patterns others miss and articulate their significance.
AI as a Force Multiplier
The inclusion of AI tools in the audit process represents a forward-looking approach that leverages new capabilities while maintaining human judgment. Using AI to identify distinct responsibilities in god models or spot patterns across multiple files acknowledges that these tools can accelerate analysis once the auditor understands the system's structure.
The caveat that "AI doesn't know what the business does" is crucial—it reminds us that technical assessment must remain grounded in business context. AI can identify patterns, but only human auditors can determine whether complexity is accidental or load-bearing, whether architectural decisions were made with full understanding of tradeoffs.
Implications for Technical Assessment
Piechowski's approach offers several important implications for how we assess and improve legacy systems:
Context Trumps Code: Technical assessment must begin with understanding the organizational context, deployment patterns, and team relationships with the system.
Signals Over Symptoms: Look for the patterns that indicate underlying problems rather than merely cataloging surface-level issues.
Prioritization is Paramount: The value of technical assessment lies not in completeness but in actionable prioritization.
Fear as a Guide: The areas teams are afraid to touch often reveal the most critical technical debt, regardless of code quality metrics.
Evolution Over Revolution: Recognize when incremental improvement is possible versus when a complete system reset is necessary.
The methodology presented in this playbook represents a maturation in how we approach legacy systems assessment—one that recognizes technical debt as both a technical and organizational phenomenon, and that understands the true measure of system health isn't in lines of code or test coverage percentages, but in the team's ability to ship value safely and sustainably.
In the end, the most valuable insight may be this: the first week of an audit should be about understanding the system's relationship with its organization, not just examining the code in isolation. The signals—the deployment patterns, the areas of fear, the unanswered questions—reveal more about what needs fixing than any tool could show on its own.
Comments
Please log in or register to join the discussion