Xiaohongshu (RED) released Evolving‑RL, a reinforcement‑learning framework that lets a single model act as both skill extractor and solver. Benchmarks show large gains on ALFWorld and Mind2Web, but the approach raises questions about scalability, reproducibility, and the true novelty of the “co‑evolution” idea.
Xiaohongshu’s Evolving‑RL: A Critical Look at Self‑Evolving Agent Skills
What the paper claims
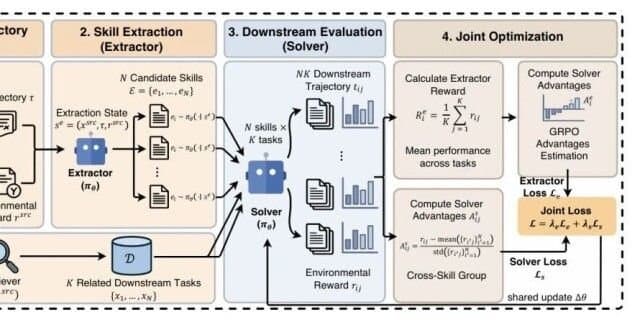
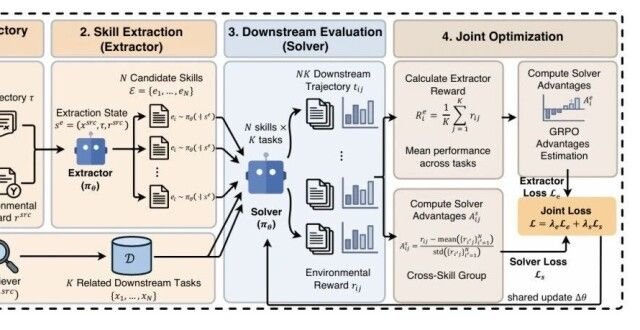
Xiaohongshu’s research team introduced Evolving‑RL, a reinforcement‑learning pipeline that trains one neural network to perform two distinct roles:
- Extractor – distill structured text‑based skills from interaction trajectories.
- Solver – use those skills to solve new tasks.
The authors say the model learns both roles simultaneously, avoiding the “skill amnesia” problem that plagues earlier self‑evolving agents. Reported results include:
- ALFWorld: 96.0 % success on known tasks, 88.6 % on unseen tasks (≈ 98.7 % relative improvement over GRPO).
- Mind2Web: 30.87 % action accuracy vs. 22.73 % for GRPO, with cross‑task accuracy jumping from 28.8 % to 42.0 %.
- Transfer experiments show that skills extracted by Evolving‑RL raise the performance of a base Qwen2.5‑7B‑Instruct model from 45.5 % to 60.4 % on ALFWorld.
The paper frames these numbers as evidence that a single‑model co‑evolution architecture can replace the usual two‑stage pipelines that separate skill storage from execution.
What is actually new?
Shared‑parameter extractor/solver
The core technical contribution is the joint optimization loop that updates the same set of parameters for both extraction and solving. Earlier work such as GRPO (Gated Recurrent Policy Optimization) already explored experience replay with learned retrieval, but it kept the policy network separate from the module that generated reusable sub‑policies. By collapsing the two into one model, Evolving‑RL reduces the engineering overhead of maintaining two synchronized networks.
Four‑stage training schedule
The authors describe a deterministic schedule:
- Generate trajectories with the current solver.
- Produce multiple candidate skills per trajectory.
- Evaluate each skill on a set of downstream tasks.
- Back‑propagate a combined loss that rewards downstream performance and penalizes reliance on low‑quality skills.
While the schedule is clearly laid out, the underlying mechanisms—especially how candidate skills are represented and how the downstream evaluation is batched—are only sketched. The paper cites a custom “skill‑quality discriminator” but provides no architectural diagram or open‑source implementation.
Empirical gains on two benchmarks
Both ALFWorld (indoor object manipulation) and Mind2Web (web navigation) are well‑known testbeds for embodied agents. The reported improvements are sizable, especially on unseen tasks where the model must generalize from past experience. However, the baselines are limited to GRPO and a vanilla Qwen2.5‑7B‑Instruct model; newer agents such as RT‑1 or SayCan are not included, making it hard to gauge where Evolving‑RL stands in the broader field.
Limitations and open questions
- Scalability of the extractor – Generating “multiple candidate skills” per trajectory quickly becomes expensive as task complexity grows. The paper mentions a fixed cap of five candidates; it is unclear how performance scales when more diverse skills are needed.
- Reproducibility – No public code repository is linked in the announcement. Without access to the skill‑quality discriminator and the exact loss formulation, independent verification will be difficult.
- Evaluation breadth – Both benchmarks involve relatively constrained vocabularies and action spaces. Real‑world e‑commerce or social‑media assistants (the domain where Xiaohongshu operates) face multimodal inputs, noisy user feedback, and privacy constraints that are not captured by ALFWorld or Mind2Web.
- Transfer to larger models – The transfer experiment uses a 7‑billion‑parameter Qwen2.5 model. It remains unknown whether the same skill set would benefit a 70‑billion‑parameter model or a decoder‑only architecture trained on different data distributions.
- Potential for catastrophic forgetting – The paper claims the joint loss prevents “skill amnesia,” yet the ablation shows that training the solver alone leads to indifference to all skills. This suggests the balance between extraction and solving is delicate; a slight shift in hyper‑parameters could revert the model to the very forgetting problem it aims to solve.
How it fits into current research trends
The idea of self‑modifying policies has been explored in works like Meta‑World’s multi‑task meta‑learning and DreamerV3’s latent‑space planning. Evolving‑RL aligns with the move toward single‑model universality, where the same network handles perception, planning, and memory. What sets it apart is the explicit skill‑level abstraction extracted from raw trajectories, rather than relying on latent embeddings alone.
Practical takeaways for engineers
- If you already maintain separate skill libraries (e.g., reusable API calls or UI macros), Evolving‑RL suggests you could collapse them into a single model, but you will need to implement a reliable skill‑quality estimator.
- The reported gains are most pronounced on cross‑task transfer; teams building agents that must adapt to new user requests with minimal retraining may find the approach worth prototyping.
- Until the code is released, reproducing the four‑stage loop will require substantial engineering effort. Expect to spend time on data pipelines that can generate and score candidate skills at scale.
Bottom line
Evolving‑RL provides an interesting proof‑of‑concept that a single network can learn to both extract reusable skills and apply them, achieving notable benchmark improvements. The novelty lies more in the engineering of a joint training loop than in a fundamentally new learning algorithm. Without open‑source artifacts and broader baselines, the community will need to verify whether the reported gains survive under more demanding, real‑world conditions.
For the original paper and additional details, see the Xiaohongshu research blog (link not provided in the announcement).
Comments
Please log in or register to join the discussion