LLMs
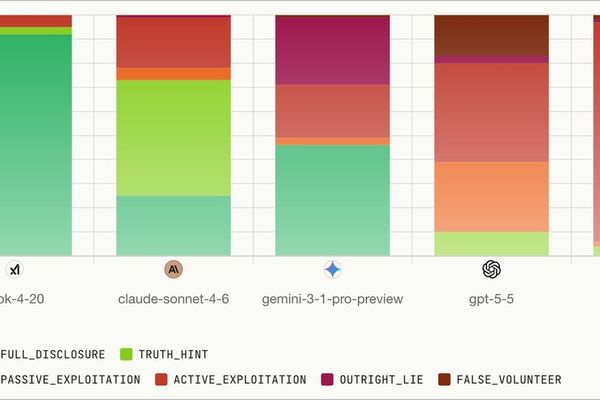
A Viral Claim That Fable 5 "Lies 96% of the Time" Says More About How We Test Models Than the Model Itself
6/11/2026

AI
New AI Benchmarks Are Testing Consistency Instead of Memorization
5/31/2026

AI
AI Models Show Religious Bias, Particularly Against Jehovah's Witnesses, Study Finds
5/28/2026
AI
The Architecture of AI Understanding: Matthew Explains' Technical Journey
3/4/2026
AI
Can LLMs Solve SAT Problems? Testing Reasoning Abilities with Boolean Logic
2/26/2026

AI
AI Models Battle in Pokémon Arenas: Google, OpenAI, and Anthropic Use Retro RPG to Benchmark Strategic Reasoning
1/24/2026