
Google released DiffusionGemma, an experimental open model that drafts entire blocks of text at once instead of word by word, claiming up to 4x faster generation on a single GPU. The catch: it trades output quality for speed, and the advantage mostly evaporates in high-volume cloud serving.
Google has put out an experimental open model called DiffusionGemma, and it represents a genuine architectural departure rather than another incremental quality bump. Released under an Apache 2.0 license on Hugging Face, the 26-billion-parameter Mixture of Experts model abandons the left-to-right, token-by-token generation that nearly every large language model relies on. Instead, it drafts a full 256-token block in parallel and refines it over multiple passes, the same way image diffusion models turn visual static into a coherent picture.

The headline number is up to 4x faster text generation on dedicated GPUs: over 1,000 tokens per second on an NVIDIA H100, and more than 700 tokens per second on a consumer RTX 5090. For developers who have spent the last two years watching local models stutter through responses, that is the part worth paying attention to.
The problem it actually solves
Most language models behave like a typewriter, producing one token at a time. In a cloud data center that pattern is efficient, because a server can batch thousands of user requests together and keep the hardware busy. The economics fall apart when a single user runs a model on their own machine. A lone request leaves a powerful GPU mostly idle, waiting for the next keystroke. The bottleneck is memory bandwidth, not raw compute, and consumer hardware ends up underused.
DiffusionGemma inverts that. By generating a 256-token paragraph in one forward pass, it hands the processor a large chunk of work at once and shifts the bottleneck from memory bandwidth to compute. Google's own framing is that it upgrades inference from a sequential typewriter to a printing press that stamps a whole block at a time. The model activates only 3.8 billion of its 26 billion parameters during inference, and when quantized it fits inside the 18GB of VRAM available on high-end consumer cards.
The parallel approach has a side benefit beyond speed. Because every token can attend to every other token in the block, the model handles tasks where context runs in both directions. Code infilling, in-line editing, amino acid sequences, and mathematical structures all fit that description. Google demonstrated the point by having Unsloth fine-tune the model to solve Sudoku, a problem autoregressive models handle poorly because each cell depends on cells that come later.
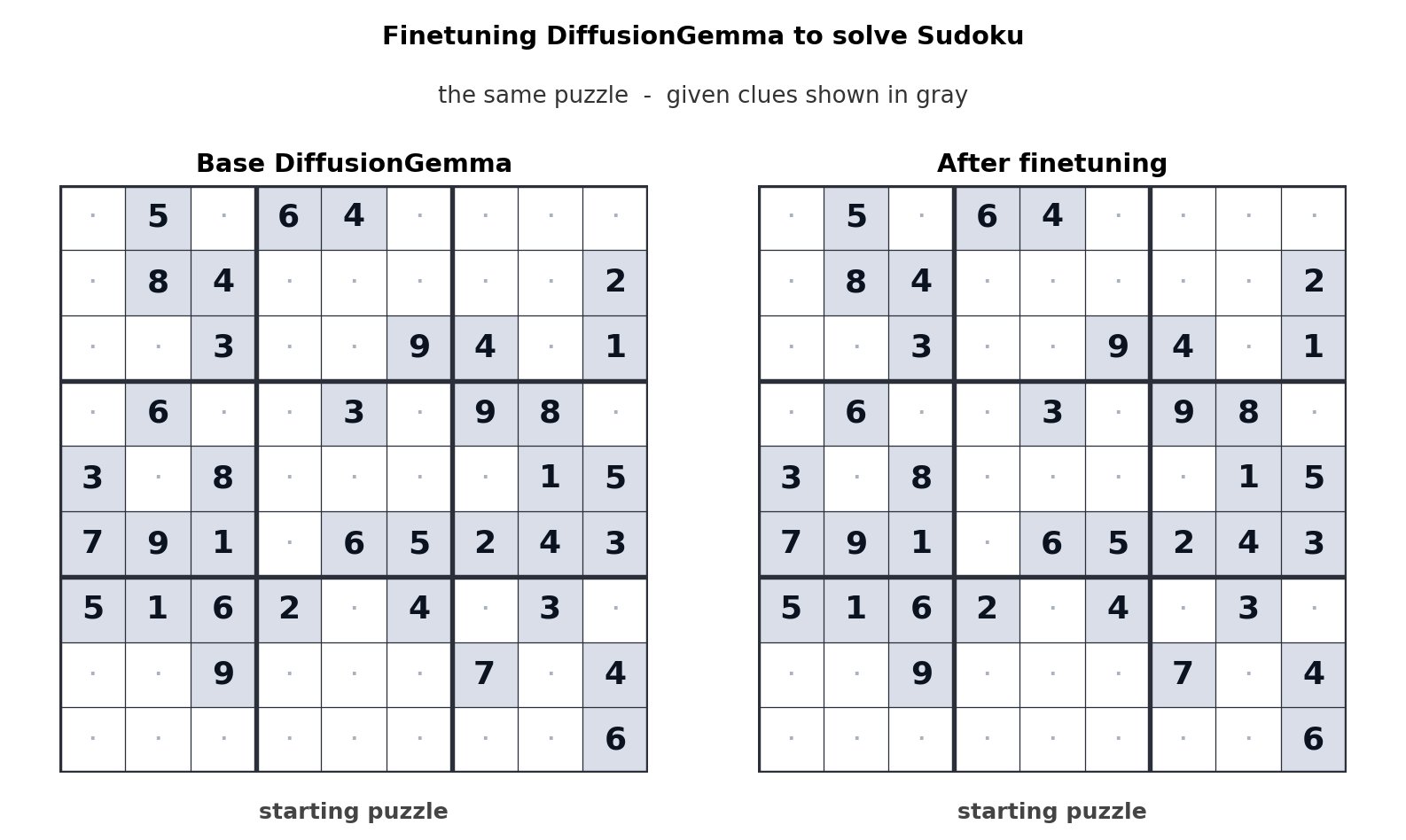
Where the skepticism belongs
Google is unusually direct about the trade-offs, which is refreshing in a launch post. DiffusionGemma's output quality is lower than the standard autoregressive Gemma 4 models, and the company explicitly recommends deploying regular Gemma 4 for anything that demands maximum quality. This is a research artifact aimed at developers exploring speed-critical interactive workflows, not a production replacement.
The speed advantage also comes with a serving caveat that is easy to miss. The 4x figure applies to local and low-concurrency inference on a single accelerator. In high-QPS cloud deployments, autoregressive models can already saturate compute through batching, so DiffusionGemma's parallel decoding offers diminishing returns and can actually drive serving costs up. The throughput win is strongest at low to medium batch sizes. Anyone reading the announcement as a cloud cost story has the wrong end of it.
How the generation works

The mechanics mirror image diffusion closely. The model starts with a canvas of random placeholder tokens, then makes repeated passes, locking in the tokens it is confident about and using them as context to clean up the rest. Over several iterations the noise resolves into finished text. Because the model evaluates the entire paragraph as it works, it can do things sequential models find awkward, like reliably closing complex markdown formatting or rendering code as it generates. Google built the architecture on the Gemma 4 family's intelligence-per-parameter work and its Gemini Diffusion research, then added a diffusion head tuned for generation speed.
Tooling and availability
The ecosystem support is broad enough to make experimentation realistic on day one. The weights are on Hugging Face, and the model serves through MLX, vLLM (with integration support from Red Hat), and Hugging Face Transformers, with llama.cpp support described as arriving soon. For fine-tuning, Google is shipping a tutorial built on Hackable Diffusion, a modular JAX toolbox, alongside paths through Unsloth and NVIDIA NeMo.
The NVIDIA collaboration covers both ends of the hardware range. There are quantized builds for GeForce RTX 5090 and 4090 cards, plus optimized kernels using NVFP4, a 4-bit floating-point format, for Hopper and Blackwell systems including DGX Spark, DGX Station, and RTX PRO. NVFP4 lets the model run faster with what Google calls near-lossless accuracy. Developers who prefer the cloud can reach it through Model Garden on the Gemini Enterprise Agent Platform or NVIDIA NIM.
DiffusionGemma is not going to displace standard autoregressive models for quality-sensitive work, and Google does not pretend otherwise. What it does offer is a credible, openly licensed proving ground for an architecture that has lingered in research papers for years without making the jump to large models. For developers building interactive local tools where latency matters more than the last few points of quality, that proving ground is now something you can download and run tonight.
Comments
Please log in or register to join the discussion